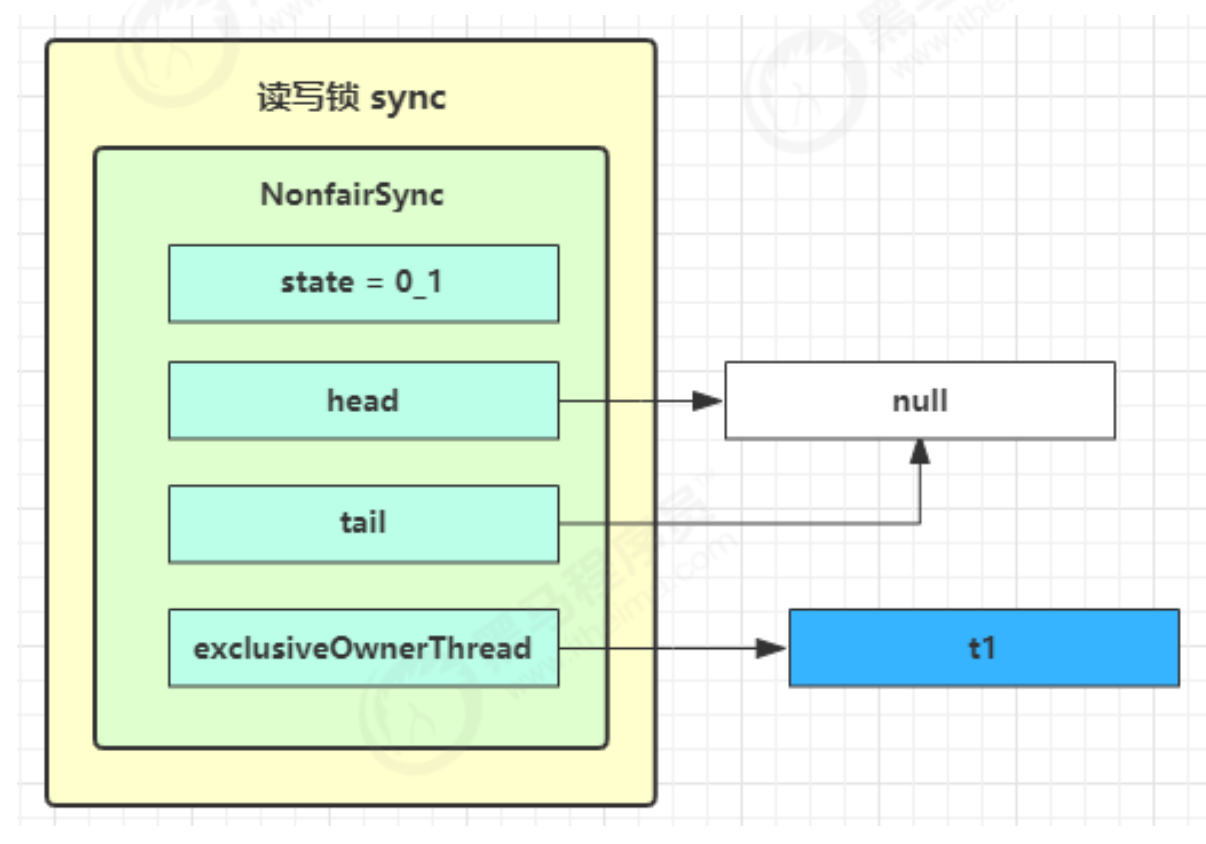
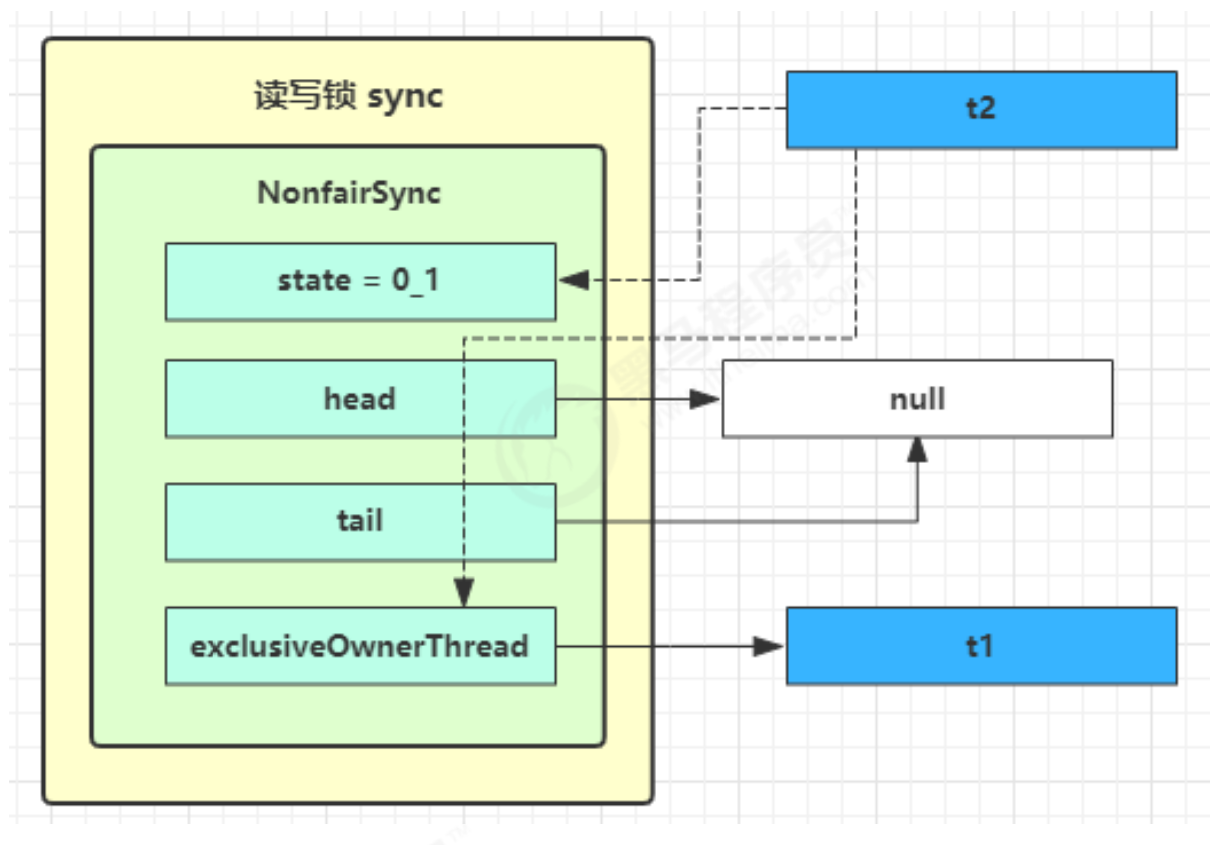
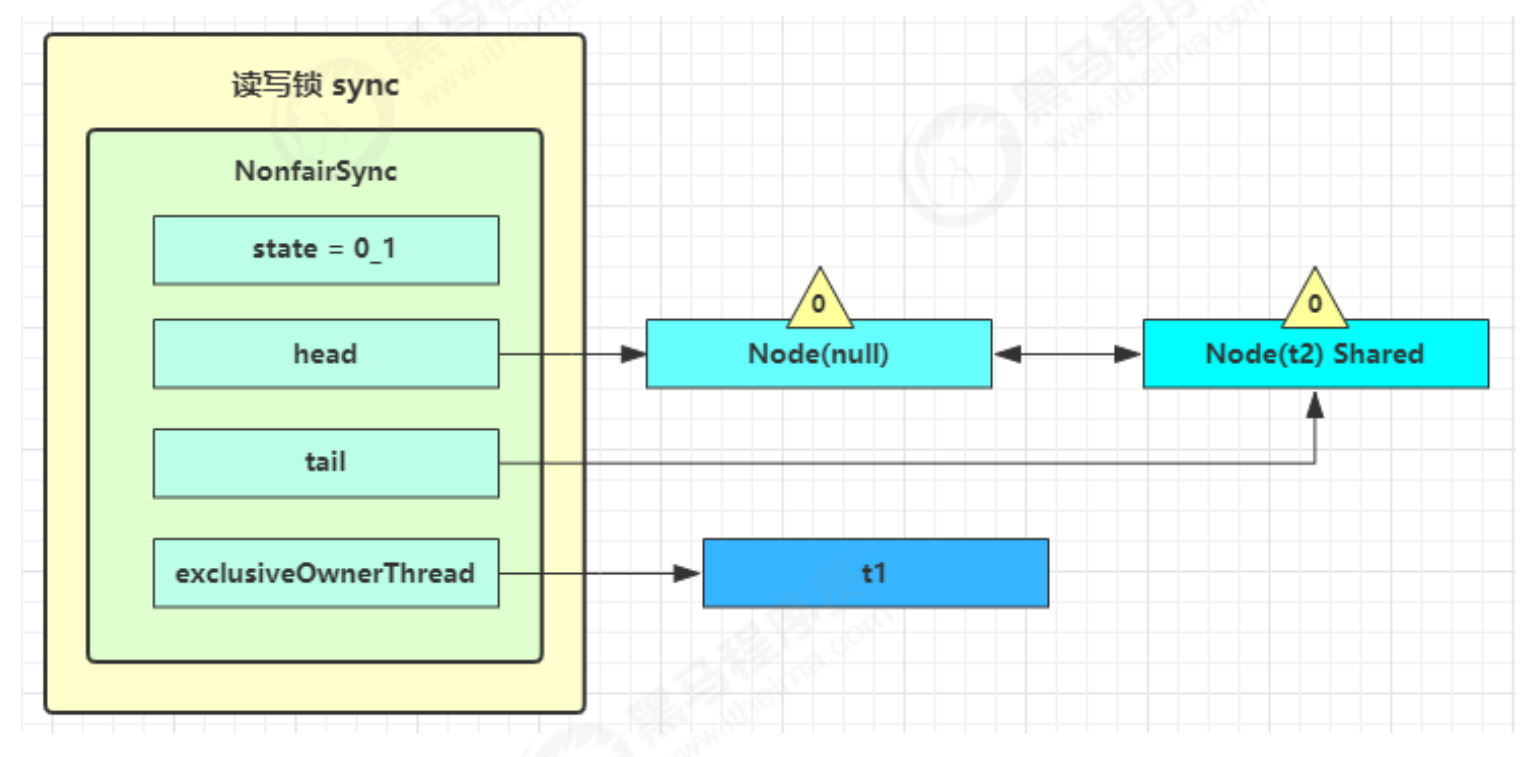
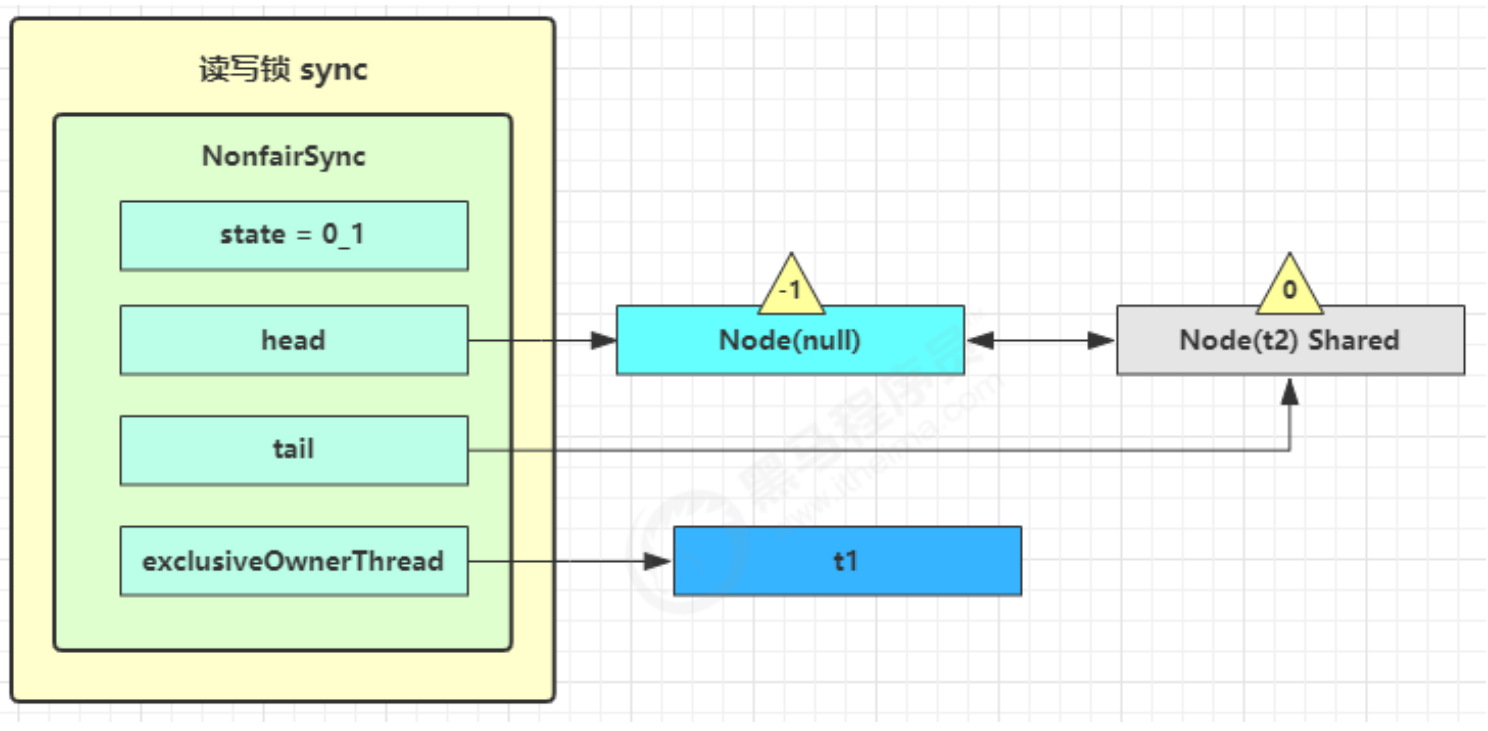
线程运行原理 栈和栈帧
Java Virtual Machine Stacks (Java 虚拟机栈)
我们都知道 JVM 中由堆、栈、方法区所组成,其中栈内存是给谁用的呢?其实就是线程,每个线程启动后,虚拟 机就会为其分配一块栈内存。
每个栈由多个栈帧(Frame)组成,对应着每次方法调用时所占用的内存
每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法
线程的基本操作 停止线程 一般来说线程执行完毕就会结束,无需手动关闭。但是如果我们想关闭一个正在运行的线程,有什么方法呢?可以看一下Thread类中提供了一个stop()方法,调用这个方法,就可以立即将一个线程终止,非常方便
但stop方法为何会被废弃而不推荐使用?stop方法过于暴力,强制把正在执行的方法停止了
大家是否遇到过这样的场景:电力系统需要维修,此时咱们正在写代码,维修人员直接将电源关闭了,代码还没保存的,是不是很崩溃,这种方式就像直接调用线程的stop方法类似。线程正在运行过程中,被强制结束了,可能会导致一些意想不到的后果。可以给大家发送一个通知,告诉大家保存一下手头的工作,将电脑关闭
打断线程 在java中,线程中断是一种重要的线程写作机制,从表面上理解,中断就是让目标线程停止执行的意思,实际上并非完全如此。在上面中,我们已经详细讨论了stop方法停止线程的坏处,jdk中提供了更好的中断线程的方法,就是interrupt()方法,该方法可以打断线程
严格的说,打断并不会使线程立即退出,而是给线程发送一个通知,告知目标线程,有人希望你退出了!至于目标线程接收到通知之后如何处理,则完全由目标线程自己决定
Interrupt说明
interrupt的本质是将线程的打断标记设为true ,并调用线程的三个parker对象(C++实现级别)unpark该线程
基于以上本质,有如下说明:
打断线程不等于中断线程,有以下两种情况:
打断正在运行中的线程并不会影响线程的运行,但如果线程监测到了打断标记为true,可以自行决定后续处理
打断阻塞中的线程会让此线程产生一个InterruptedException异常,结束线程的运行。但如果该异常被线程捕获住,该线程依然可以自行决定后续处理(终止运行,继续运行,做一些善后工作等等)
注意细节:
1.interrupt()方法为什么可以打断sleep,wait,join方法导致的线程阻塞呢?
网络上的原理解析说是这三个方法内部会不断的轮询打断标记状态是否为true,一旦为true则会抛出InterruptedException,结束线程的阻塞状态**(源码是native,未能验证其正确性)**
2.interrupt()方法不能打断由于线程竞争重量级锁Monitor(synchronized)失败而导致线程进入的阻塞状态
3.如果打断的是处于sleep,wait,join方法的线程(阻塞态),系统会重置打断标志位
1 2 3 public void interrupt () public boolean isInterrupted () public static boolean interrupted ()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 @Slf4j public class One { public static void main (String[] args) throws ExecutionException, InterruptedException { Thread t1 = new Thread (){ @Override public void run () { while (true ){ try { Thread.sleep(10000 ); } catch (InterruptedException e) { e.printStackTrace(); Thread.currentThread().interrupt(); } if (Thread.currentThread().isInterrupted()){ System.out.println(Thread.currentThread().getName()+"优雅的中止" ); break ; } } } }; System.out.println(t1.getState()); t1.start(); Thread.sleep(1000 ); t1.interrupt(); System.out.println(t1.getState()); } }
yield 调用 yield 会让当前线程从 Running 进入 Runnable 就绪状态,具体那个线程获取cpu的执行器还是得看cpu的任务调度器来决定
cpu调度器有可能还把执行给回刚刚让出cpu执行的线程
线程优先级
线程优先级会提示(hint)调度器优先调度该线程,但它仅仅是一个提示,任务调度器可以忽略它
如果 cpu 比较忙,那么优先级高的线程会获得更多的时间片,但 cpu 闲时,优先级几乎没作用
等待线程结束(join) join的作用和原理和wait基本一致,参考后面wait即可,但二者也有细微的差别,后面也有章节给出了详细的分析
1 2 public final void join () throws InterruptedException;public final synchronized void join (long millis) throws InterruptedException;
第1个方法表示无限等待,它会一直阻塞当前线程。直到目标线程执行完毕
第2个方法有个参数,用于指定等待时间,如果超过了给定的时间目标线程还在执行,当前线程也会停止等待,而继续往下执行。如果当目标线程早已运行结束,那么即使线程还没有到等待事件也会停止等待
守护线程 概念:进程会等待所有非守护线程运行结束,进程才会结束。而进程不会等待守护线程运行结束,就要所有非守护运行线程结束,即使守护线程仍未结束,进程也会强行结束
守护线程的作用和应用场景暂时不清晰
线程的五种状态及其转换 操作系统层面
Java-API层面
共享模型之管程(Monitor) 多线程操作共享数据带来的问题 线程安全问题产生的前提条件:多个线程同时操作共享数据
那么产生线程安全问题的核心原因是什么呢?
不能保证对共享数据的操作是原子性(下面有详细的原因分析)
Java代码示例 两个线程对初始值为 0 的静态变量一个做自增,一个做自减,各做 5000 次,结果是 0 吗?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 static int counter = 0 ;public static void main (String[] args) throws InterruptedException { Thread t1 = new Thread (() -> { for (int i = 0 ; i < 5000 ; i++) { counter++; } }, "t1" ); Thread t2 = new Thread (() -> { for (int i = 0 ; i < 5000 ; i++) { counter--; } }, "t2" ); t1.start(); t2.start(); t1.join(); t2.join(); log.debug("{}" ,counter); }
问题分析&解决方案 以上的结果可能是正数、负数、零。为什么呢?因为 Java 中对静态变量的自增,自减并不是原子操作,要彻底理解,必须从字节码来进行分析
例如对于 i++ 而言(i 为静态变量),实际会产生如下的 JVM 字节码指令:
1 2 3 4 getstatic i iconst_1 iadd putstatic i
而对应 i– 也是类似:
1 2 3 4 getstatic i iconst_1 isub putstatic i
实际上任何操作都有获取值,将处理完的值写入到结果存储器中这两个操作。
而问题产生的核心原因就在于一个线程因为cpu分配的时间片用完了而未能将处理完的值写入到结果中,导致其他获取到cpu执行权的线程对数据的操作都是无效的,因为当cpu再次切换到未执行完的原线程时,会覆盖此前一系列线程对数据的操作结果
例如:当cpu重新将执行权分配给原来尚未执行写入结果操作的线程时,该线程会继续执行,也就是将刚才处理的结果写入到结果存储器中,就会完全覆盖其他线程对该数据的处理结果
对原因更深一步分析:
实质就算线程交叉运行会导致线程互相覆盖彼此对数据的操作结果,进而产生错误的数据。用一个专业术语来描述就是没有保证线程操作的原子性
那么如何保证线程完全将操作执行完(线程操作的原子性)才让其他线程继续操作共享数据呢?
初步解决方案 :能不能让线程将操作完全执行完再发生线程的上下文切换呢?
答案是不能,因为cpu分配的时间片有限,线程的上下文切换是必然会发生的,我们不可能等一个线程将操作完全执行完再发生线程的上下文切换的。
最终解决方案:既然不能避免线程上下文的切换,那就让其他线程在原线程的操作尚未完全执行完全时,拒绝让其他线程访问共享数据,直到原线程的操作完全执行完才允许其他线程访问共享数据,用专业的术语来说就是实现线程的同步 or 互斥效果
那最终解决方案具体怎么实现呢?
通过给操作的代码加锁即可实现
锁的具体作用是什么呢?为什么给操作的代码加锁就可以实现了呢?
锁的作用:要想对共享数据进行操作,必须获取相应的锁资源才能操作
具体实现:
那么在加了锁的情况下就可以保证即使在cpu将执行权分配给了其他线程时,其他线程也操作不了共享数据,因为其他线程要想操作共享数据必须获取相应的锁资源,而此时锁资源一直在原线程手中并没有被释放
也就是其他线程要想操作共享数据必须等原线程释放锁,那么原线程只要保证在操作执行完再释放锁就可以实现操作的原子性了
synchronized实现加锁 在Java层面,典型的两种锁:对象锁和类锁
对象锁:只要是同一个对象,那使用的就是同一把锁
1 2 3 4 5 6 7 8 9 10 11 12 13 class Test { public synchronized void test () { } } class Test { public void test () { synchronized (this ) { } } }
类锁:只要是同一个类,那使用就是同一把锁
1 2 3 4 5 6 7 8 9 10 11 12 class Test { public synchronized static void test () { } } 等价于 class Test { public static void test () { synchronized (Test.class) { } } }
变量的线程安全分析 分析变量是否是线程安全的核心点有两个:
1.变量是否是共享数据
2.是否存在多线程对共享数据的操作
成员变量和静态变量是否线程安全?
如果它们没有共享,则线程安全
如果它们被共享了,根据它们的状态是否能够改变,又分两种情况
如果只有读操作,则线程安全
如果有读写操作,则这段代码是临界区,需要考虑线程安全
局部变量是否线程安全?
局部变量是线程安全的
但局部变量引用的对象则未必
如果该对象没有逃离方法的作用访问,它是线程安全的
如果该对象逃离方法的作用范围,需要考虑线程安全
普通的局部变量因为不是共享数据是不可能存在线程安全问题的
局部引用是因为可能会通过会暴露引用从而导致局部引用成为共享数据
局部变量线程安全分析 1 2 3 4 public static void test1 () { int i = 10 ; i++; }
每个线程调用 test1() 方法时局部变量 i,会在每个线程的栈帧内存中被创建多份,因此不存在共享
局部变量的引用稍有不同
先看一个成员变量的例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class ThreadUnsafe { ArrayList<String> list = new ArrayList <>(); public void method1 (int loopNumber) { for (int i = 0 ; i < loopNumber; i++) { method2(); method3(); } } private void method2 () { list.add("1" ); } private void method3 () { list.remove(0 ); } }
测试类执行方法代码
1 2 3 4 5 6 7 8 9 10 static final int THREAD_NUMBER = 2 ;static final int LOOP_NUMBER = 200 ;public static void main (String[] args) { ThreadUnsafe test = new ThreadUnsafe (); for (int i = 0 ; i < THREAD_NUMBER; i++) { new Thread (() -> { test.method1(LOOP_NUMBER); }, "Thread" + i).start(); } }
因为ArrayList集合是共享数据,并且ArrayList集合的操作并没有对线程安全问题进行处理
具体分析:
因为add不是线程安全的,2个线程同时执行add最后可能只add了一个元素,然后remove2次就报错了
通过观察add方法源码即可理解,添加元素发现线程安全问题的核心是size++,和前面分析的i++原理是一致的
异常分析:两个线程同时添加元素,同时获取size的值,此时一个线程添加完元素尚未执行完索引自增如0+1的操作,而另一个线程却获取到了错误的数据0,那么该线程将会继续对索引0的位置赋值,就会覆盖上一个线程已经添加的元素值。那么实际上只添加了一个元素执行了两次删除操作,自然就发生异常了
1 2 3 4 5 public boolean add (E e) { ensureCapacityInternal(size + 1 ); elementData[size++] = e; return true ; }
解决方案:
将 list 修改为局部变量就不会有上述问题了,因为ArrayList集合不是共享数据了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class ThreadSafe { public final void method1 (int loopNumber) { ArrayList<String> list = new ArrayList <>(); for (int i = 0 ; i < loopNumber; i++) { method2(list); method3(list); } } private void method2 (ArrayList<String> list) { list.add("1" ); } private void method3 (ArrayList<String> list) { list.remove(0 ); } }
方法访问修饰符带来的思考,如果把 method2 和 method3 的方法修改为 public 会不会带来线程安全问题?
结论是有可能带来线程安全问题,因为可以通过子类重写父类方法的方式暴露局部引用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class ThreadSafe { public final void method1 (int loopNumber) { ArrayList<String> list = new ArrayList <>(); for (int i = 0 ; i < loopNumber; i++) { method2(list); method3(list); } } private void method2 (ArrayList<String> list) { list.add("1" ); } private void method3 (ArrayList<String> list) { list.remove(0 ); } } class ThreadSafeSubClass extends ThreadSafe { @Override public void method3 (ArrayList<String> list) { new Thread (() -> { list.remove(0 ); }).start(); } }
从这个例子可以看出 private 或 final 提供【安全】的意义所在,请体会开闭原则中的【闭】
常见线程安全类
String
Integer
StringBuffer
Random
Vector
Hashtable
java.util.concurrent 包下的类
这里说它们是线程安全的是指,多个线程调用它们同一个实例的某个方法时,是线程安全的。也可以理解为
1 2 3 4 5 6 7 Hashtable table = new Hashtable ();new Thread (()->{ table.put("key" , "value1" ); }).start(); new Thread (()->{ table.put("key" , "value2" ); }).start();
它们的每个方法是原子的
但注意它们多个方法的组合不是原子的,见后面分析
线程安全类方法的组合
分析下面代码是否线程安全?
1 2 3 4 5 Hashtable table = new Hashtable ();if ( table.get("key" ) == null ) { table.put("key" , value); }
非常容易混淆的点:如果每个操作是原子性的,但操作之间的组合并非是原子性的
就拿这个案例来分析:
线程 1:
时间点1:申请获取锁资源成功,调用table.get方法
时间点2:调用完table.get方法后,释放锁资源,再次申请锁资源失败,阻塞等待锁资源的释放
时间点3:仍在继续阻塞等待锁资源的释放
时间点4:申请锁资源成功,调用table.put方法,方法调用完毕
线程2:
时间点1:申请获取锁资源失败(因为线程1获取了锁资源),无法调用table.get方法,阻塞等待锁资源的释放
时间点2:申请获取锁资源成功,调用table.get方法
时间点3:调用完table.get方法后,释放锁资源,但此时再次由线程2比线程1先申请成功获取锁资源
时间点4:执行table.put完方法,执行完释放锁资源
从这个案例可以很清晰的看出,两个线程的操作一直在交叉执行
很明显,虽然每个操作都是原子性的,但每个操作执行完后会释放锁资源,此时另一个线程就可以获取到锁资源并执行相关的操作,所以即使每个操作都是原子性的,但并不能保证操作之间的组合是原子性的
不可变类线程安全性
String、Integer 等都是不可变类,因为其内部的状态不可以改变,因此它们的方法都是线程安全的 有同学或许有疑问,String 有 replace,substring 等方法【可以】改变值啊,那么这些方法又是如何保证线程安全的呢?
不可变类线程安全的核心:因为不可变类中的数据是不能改变的,所以不可能存在对共享数据的写操作,自然就会出现线程安全问题了
1 2 3 4 5 6 7 8 9 public class Immutable { private int value = 0 ; public Immutable (int value) { this .value = value; } public int getValue () { return this .value; } }
如果想增加一个增加的方法呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 public class Immutable { private int value = 0 ; public Immutable (int value) { this .value = value; } public int getValue () { return this .value; } public Immutable add (int v) { return new Immutable (this .value + v); } }
实例分析 例题概括:因为Tomcat中的servlet是单例的,所以Servlet中的成员变量都是共享数据,如果没有对共享数据进行线程安全的处理(操作的原子性),那么都会存在线程安全问题
例1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class MyServlet extends HttpServlet { Map<String,Object> map = new HashMap <>(); String S1 = "..." ; final String S2 = "..." ; Date D1 = new Date (); final Date D2 = new Date (); public void doGet (HttpServletRequest request, HttpServletResponse response) { } }
例2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class MyServlet extends HttpServlet { private UserService userService = new UserServiceImpl (); public void doGet (HttpServletRequest request, HttpServletResponse response) { userService.update(...); } } public class UserServiceImpl implements UserService { private int count = 0 ; public void update () { count++; } }
例3:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Aspect @Component public class MyAspect { private long start = 0L ; @Before("execution(* *(..))") public void before () { start = System.nanoTime(); } @After("execution(* *(..))") public void after () { long end = System.nanoTime(); System.out.println("cost time:" + (end-start)); } }
例4:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class MyServlet extends HttpServlet { private UserService userService = new UserServiceImpl (); public void doGet (HttpServletRequest request, HttpServletResponse response) { userService.update(...); } } public class UserServiceImpl implements UserService { private UserDao userDao = new UserDaoImpl (); public void update () { userDao.update(); } } public class UserDaoImpl implements UserDao { public void update () { String sql = "update user set password = ? where username = ?" ; try (Connection conn = DriverManager.getConnection("" ,"" ,"" )){ } catch (Exception e) { } } }
例5:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class MyServlet extends HttpServlet { private UserService userService = new UserServiceImpl (); public void doGet (HttpServletRequest request, HttpServletResponse response) { userService.update(...); } } public class UserServiceImpl implements UserService { private UserDao userDao = new UserDaoImpl (); public void update () { userDao.update(); } } public class UserDaoImpl implements UserDao { private Connection conn = null ; public void update () throws SQLException { String sql = "update user set password = ? where username = ?" ; conn = DriverManager.getConnection("" ,"" ,"" ); conn.close(); } }
例6:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class MyServlet extends HttpServlet { private UserService userService = new UserServiceImpl (); public void doGet (HttpServletRequest request, HttpServletResponse response) { userService.update(...); } } public class UserServiceImpl implements UserService { public void update () { UserDao userDao = new UserDaoImpl (); userDao.update(); } } public class UserDaoImpl implements UserDao { private Connection = null ; public void update () throws SQLException { String sql = "update user set password = ? where username = ?" ; conn = DriverManager.getConnection("" ,"" ,"" ); conn.close(); } }
例7:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public abstract class Test { public void bar () { SimpleDateFormat sdf = new SimpleDateFormat ("yyyy-MM-dd HH:mm:ss" ); foo(sdf); } public abstract foo (SimpleDateFormat sdf) ; public static void main (String[] args) { new Test ().bar(); } }
其中 foo 的行为是不确定的,存在暴露局部引用的可能
1 2 3 4 5 6 7 8 9 10 11 12 public void foo (SimpleDateFormat sdf) { String dateStr = "1999-10-11 00:00:00" ; for (int i = 0 ; i < 20 ; i++) { new Thread (() -> { try { sdf.parse(dateStr); } catch (ParseException e) { e.printStackTrace(); } }).start(); } }
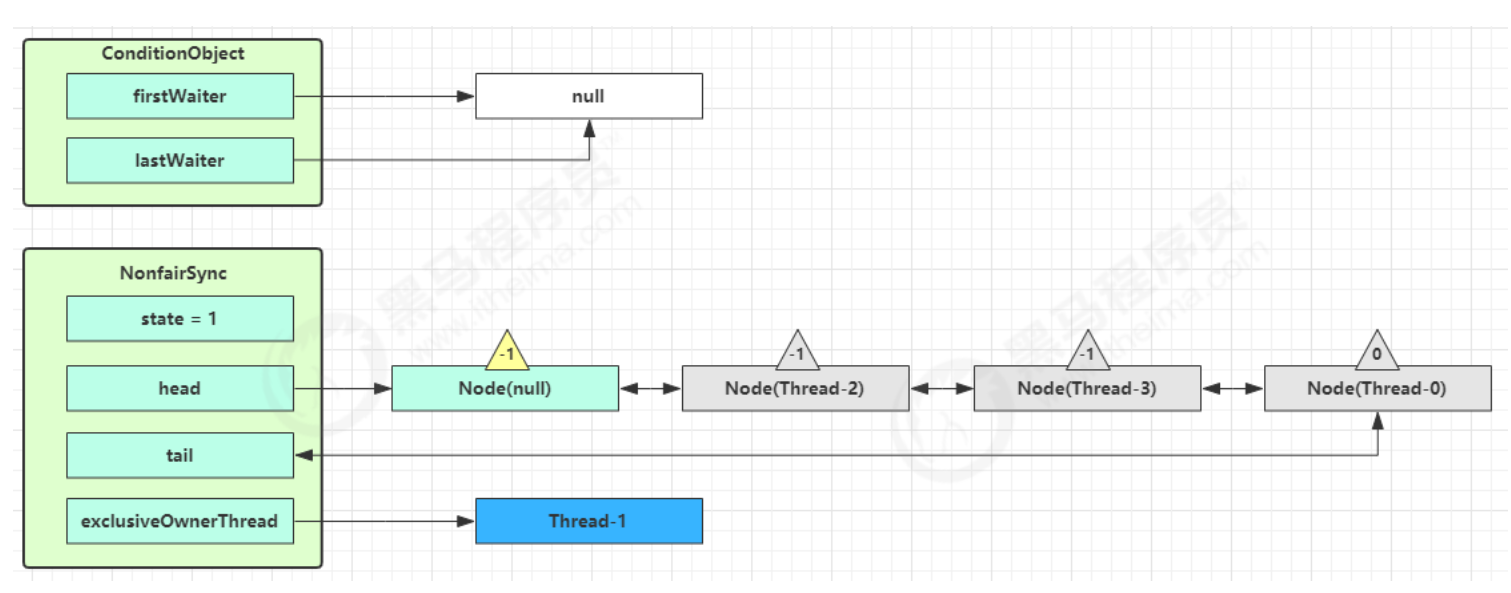
Monitor 概念 Java 对象头 以 32 位虚拟机为例
普通对象
1 2 3 4 5 |-------------------------------------------------------------- | | Object Header (64 bits) | |------------------------------------ |-------------------------| Mark Word (32 bits) | Klass Word (32 bits) ||------------------------------------ |-------------------------|
数组对象
1 2 3 4 5 |--------------------------------------------------------------------------------- | | Object Header (96 bits) | |-------------------------------- |-----------------------|------------------------ | | Mark Word(32bits) | Klass Word (32bits) | array length(32bits) | |-------------------------------- |-----------------------|------------------------ |
其中 Mark Word 结构 为
1 2 3 4 5 6 7 8 9 10 11 12 13 |------------------------------------------------------- |--------------------| Mark Word (32 bits) | State ||------------------------------------------------------- |--------------------| hashcode: 25 | age:4 | biased_lock: 0 | 01 | Normal |-------------------- ||thread:23 |epoch: 2 | age:4 | biased_lock: 1 | 01 | Biased | -------------------- || ptr_to_lock_record:30 | 00 | Lightweight Locked | |------------------------------------------------------- |--------------------| ptr_to_heavyweight_monitor: 30 | 10 | Heavyweight Locked |-------------------- || | 11 | Marked for GC | |------------------------------------------------------- |--------------------|
64 位虚拟机 Mark Word
1 2 3 4 5 6 7 8 9 10 11 12 13 |-------------------------------------------------------------------- |--------------------| Mark Word (64 bits) | State ||-------------------------------------------------------------------- |--------------------| unused: 25 | hashcode:31 | unused: 1 | age:4 | biased_lock: 0 | 01 | Normal |-------------------- || thread:54 | epoch: 2 | unused:1 | age: 4 | biased_lock:1 | 01 | Biased | |-------------------------------------------------------------------- |--------------------| ptr_to_lock_record: 62 | 00 | Lightweight Locked |-------------------- || ptr_to_heavyweight_monitor:62 | 10 | Heavyweight Locked | |-------------------------------------------------------------------- |--------------------| 11 | Marked for GC |-------------------- |
参考资料
https://stackoverflow.com/questions/26357186/what-is-in-java-object-header
原理之Monitor(锁) Monitor 被翻译为监视器 或管程
每个 Java 对象都可以关联一个 Monitor 对象,如果使用 synchronized 给对象上锁(重量级)之后,该对象头的 Mark Word 中就被设置指向 Monitor 对象的指针
Monitor锁:实际上对象不是真正的锁,对象只是在对象头中保存了真正的锁的引用
Monitor 结构如下
如何通过Monitor锁来实现线程安全呢(加锁原理&&实现原理)?
1.如果一个线程想要加锁,那么他就会跟Monitor锁形成关联(关联就是对象头会保存Monitor锁的引用)
2.线程和锁形成关联后,线程会通过锁的Owner值判断该锁是否已经有主人了(是否被其他线程占有了),如果没有Owner为null,证明该锁没有主人,线程就会把Owner值设置为自己的线程id,标识自己获取了这把锁
3.当另一个线程也想要加锁时,那么该线程也会跟同一个Monitor锁形成关联,通过判断锁的Owner值判断锁是否已经被其他线程占有,如果Owner值不为空,说明已经被其他线程占有,那么此线程就会将自己的线程状态从运行状态切换为阻塞状态并进入Monitor锁的等待队列EntryList中
4.占有锁的线程如何释放锁?释放锁会做些什么操作?
占有锁的线程会将Owner值重写置为Null,并唤醒等待队列中正在等待的线程,然后接触和Monitor锁的关联,此时已经被唤醒的线程会重新竞争锁
小细节:
因为对象头的存储空间有限,对象头是使用本来存储 hashcode:25 | age:4 | biased_lock:0 的空间来存储Monitor锁的引用,那么对象头本来的hashcode,age,biased_lock的数据是交给了Monitor锁来暂时存储的,等到释放锁时二者再重新交换,恢复对象头的MarkWork结构
注意 :
synchronized 必须是进入同一个对象的 monitor 才有上述的效果
不加 synchronized 的对象不会关联监视器,不遵从以上规则
原理之 synchronized 从JVM的字节码角度 讲述synchronized原理
1 2 3 4 5 6 7 static final Object lock = new Object ();static int counter = 0 ;public static void main (String[] args) { synchronized (lock) { counter++; } }
对应的字节码为
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public static void main (java.lang.String[]) ;descriptor: ([Ljava/lang/String;)V flags: ACC_PUBLIC, ACC_STATIC Code: stack=2 , locals=3 , args_size=1 0 : getstatic #2 3 : dup 4 : astore_1 5 : monitorenter 6 : getstatic #3 9 : iconst_1 10 : iadd 11 : putstatic #3 14 : aload_1 15 : monitorexit 16 : goto 24 19 : astore_2 20 : aload_1 21 : monitorexit 22 : aload_2 23 : athrow 24 : return Exception table: from to target type 6 16 19 any 19 22 19 any LineNumberTable: line 8 : 0 line 9 : 6 line 10 : 14 line 11 : 24 LocalVariableTable: Start Length Slot Name Signature 0 25 0 args [Ljava/lang/String; StackMapTable: number_of_entries = 2 frame_type = 255 offset_delta = 19 locals = [ class "[Ljava/lang/String;" , class java /lang/Object ] stack = [ class java /lang/Throwable ] frame_type = 250 offset_delta = 4
从JVM的字节码清晰可以看出加锁的原理
加锁过程就是对象头(MarkWork结构属于对象头的内部结构)保存了Monitor锁的引用
解锁过程就是唤醒等待队列中的线程并解除跟Monitor锁的关联(重置对象头的MarkWork结构)
重置对象头的MarkWork结构实际上就是将对象头中存储的Mointor锁引用和锁暂时存储的对象头的MarkWork结构信息进行交换,恢复对象头MarkWork结构的信息
原理之 synchronized 进阶 轻量级锁 轻量级锁的使用场景:
如果一个对象虽然有多线程要加锁,但他们加锁的时间是错开的,也就是不存在多线程同时 访问共享资源的情况,就基本不会出现线程安全问题,那么就可以使用轻量级锁来优化重量级的Monitor锁
为什么需要优化Monitor锁?
Monitor锁属于操作系统层面的锁,涉及操作系统的资源调配和线程的上下文切换,对性能的消耗是非常大的,所以称其为重量级的锁
为什么明明已经不存在同时访问共享资源的情况,也就是不存在线程安全问题了,还要加轻量级锁呢?
因为我们不能保证一定没有同时 访问共享资源的情况,要做好如果真的出现同时访问共享资源的安全处理
轻量级锁加锁原理:
1.轻量级锁是使用线程栈的一个锁记录结构来实现的 ,每一个栈的栈帧都会包含一个锁记录结构
2.线程如果想要加锁,首先先判断锁对象的对象头MarkWork结构是否已经保存了其他锁记录的引用信息,如果已经保存了其他锁记录的引用信息,证明该锁已经被其他线程持有,加锁失败
3.如果没有保存其他锁记录的引用信息,则让锁记录和锁对象进行CAS操作,如果CAS操作成功,则标识着线程成功加锁,如果CAS操作失败则加锁失败
CAS操作分为三步:
1.获取锁对象的对象头MarkWork结构的值
2.将获取到的MarkWrok结构的值与锁对象的MarkWork结构的值相比较,如果相同则证明在加锁过程中没有其他线程干扰
3.如果相同则会让锁记录的引用地址信息和锁对象的对象头MarkWork结构信息进行交换,交换成功即上锁成功
轻量级锁解锁原理
锁记录和锁对象使用CAS操作,如果交换成功则解锁成功,如果交换失败,则说明轻量级锁已经升级为重量级锁,进入重量级锁的解锁流程(重量级级锁的解锁原理上面有)
细节:
如果轻量锁加锁失败则会进行锁膨胀 or 累加锁的重入次数LockRecord
如果是因为同一个线程重复加锁,则会累加锁的重入次数,如果是因为有其他线程同时竞争锁(同时访问共享资源),则会进行锁膨胀,锁膨胀就是将轻量级锁升级为重量级锁。因为存在线程安全问题,只能升级为重量级锁解决线程安全问题了
案例演示
轻量级锁对使用者是透明的,即语法仍然是 synchronized
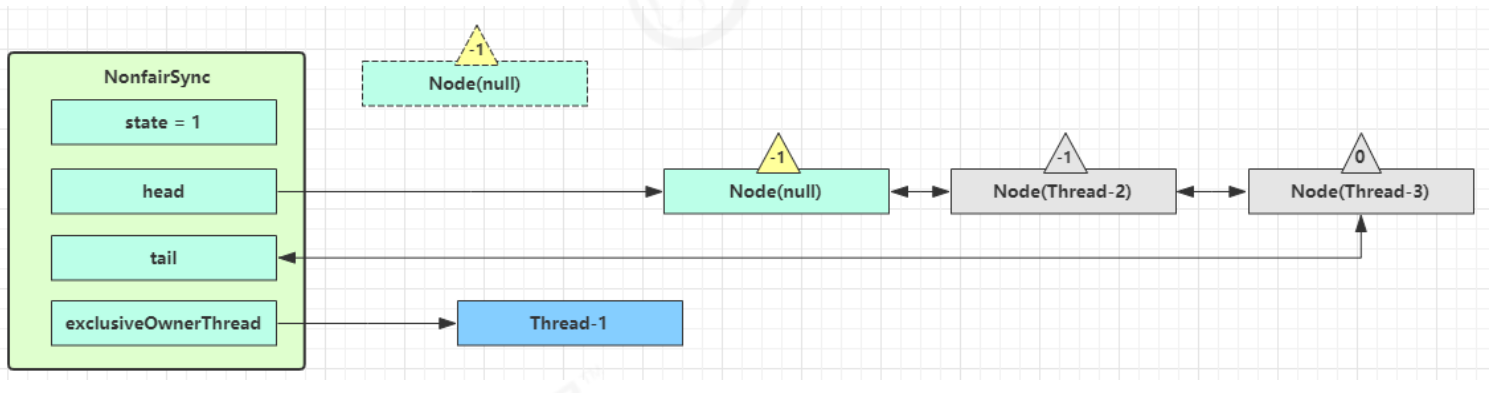
假设有两个方法同步块,利用同一个对象加锁
1 2 3 4 5 6 7 8 9 10 11 12 static final Object obj = new Object ();public static void method1 () { synchronized ( obj ) { method2(); } } public static void method2 () { synchronized ( obj ) { } }
创建锁记录(Lock Record)对象,每个线程栈的栈帧都会包含一个锁记录的结构,内部可以存储锁定对象的 Mark Word
让锁记录中 Object reference 指向锁对象,并尝试用 cas 替换 Object 的 Mark Word,将 Mark Word 的值存 入锁记录
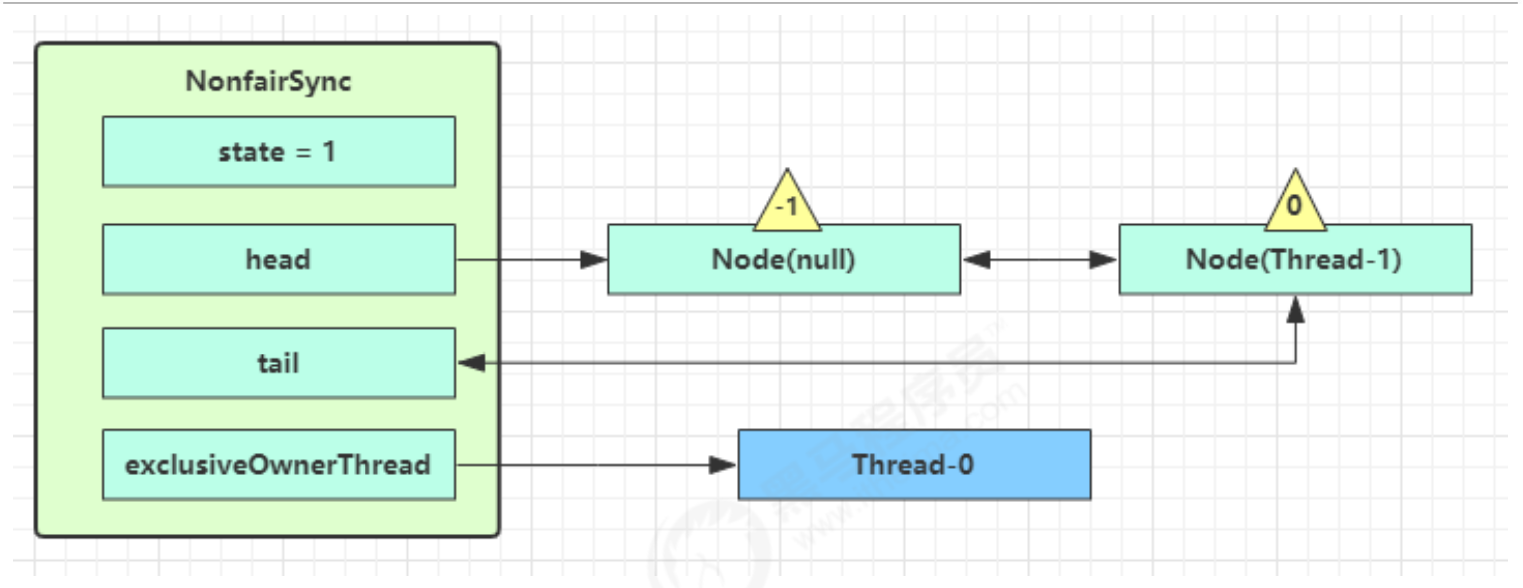
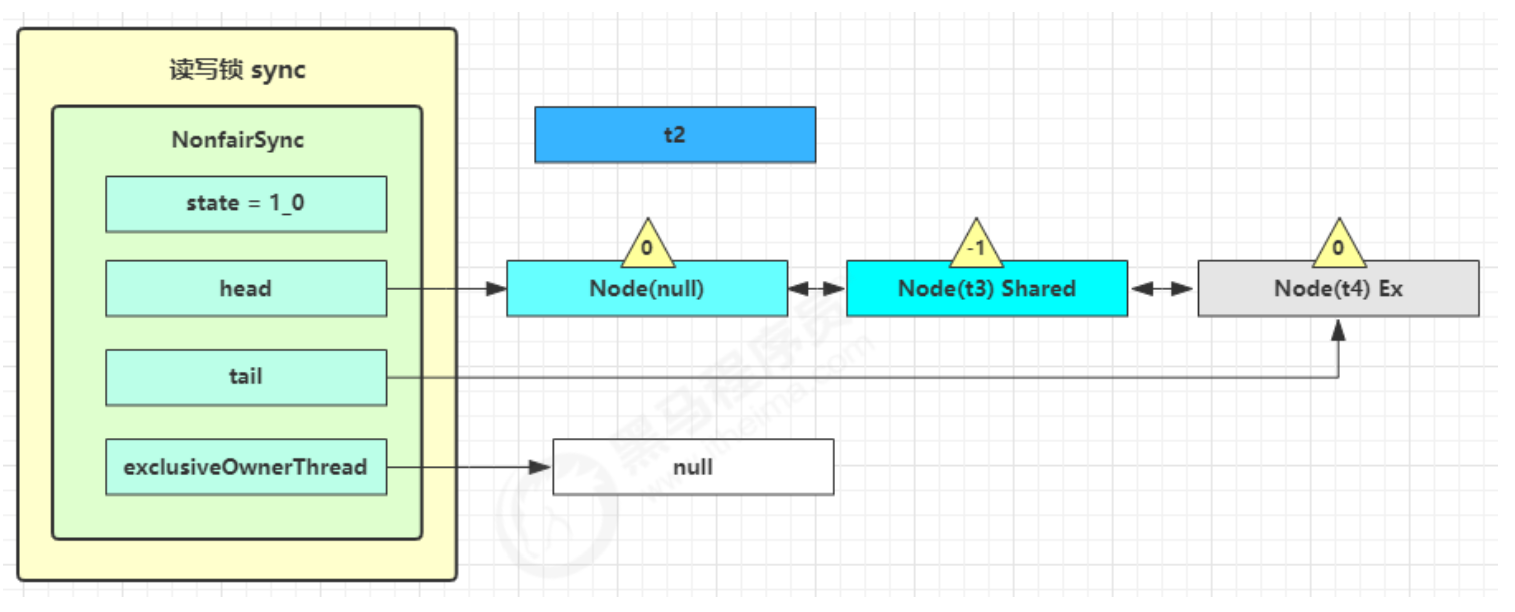
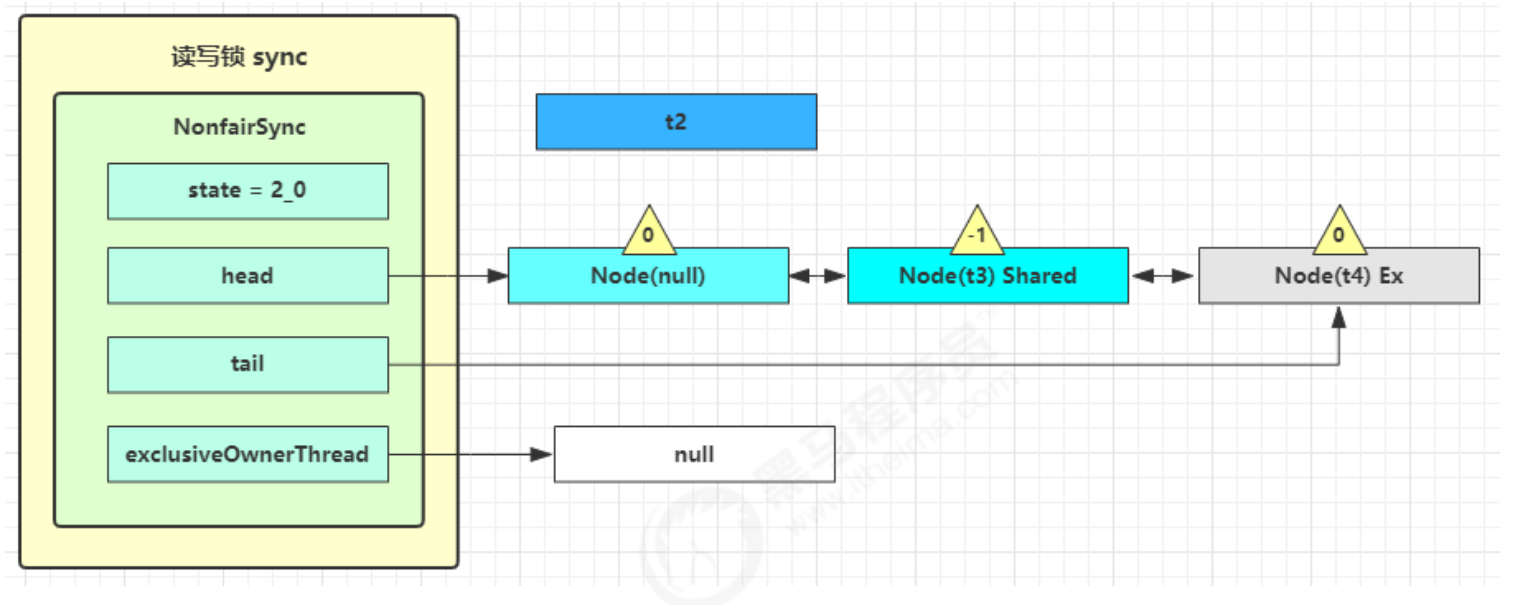
如果 cas 替换成功,对象头中存储了 锁记录地址和状态 00 ,表示由该线程给对象加锁,这时图示如下
如果 cas 失败,有两种情况
如果是其它线程已经持有了该 Object 的轻量级锁,这时表明有竞争,进入锁膨胀过程
如果是自己执行了 synchronized 锁重入,那么再添加一条 Lock Record 作为重入的计数
当退出 synchronized 代码块(解锁时)如果有取值为 null 的锁记录,表示有重入,这时重置锁记录,表示重 入计数减一
当退出 synchronized 代码块(解锁时)锁记录的值不为 null,这时使用cas将Mark Word的值恢复给对象头
成功,则解锁成功
失败,说明轻量级锁进行了锁膨胀或已经升级为重量级锁,进入重量级锁解锁流程
锁膨胀 如果在尝试加轻量级锁的过程中,CAS 操作无法成功,这时一种情况就是有其它线程为此对象加上了轻量级锁(有竞争 ),这时需要进行锁膨胀,将轻量级锁变为重量级锁。
1 2 3 4 5 6 static Object obj = new Object ();public static void method1 () { synchronized ( obj ) { } }
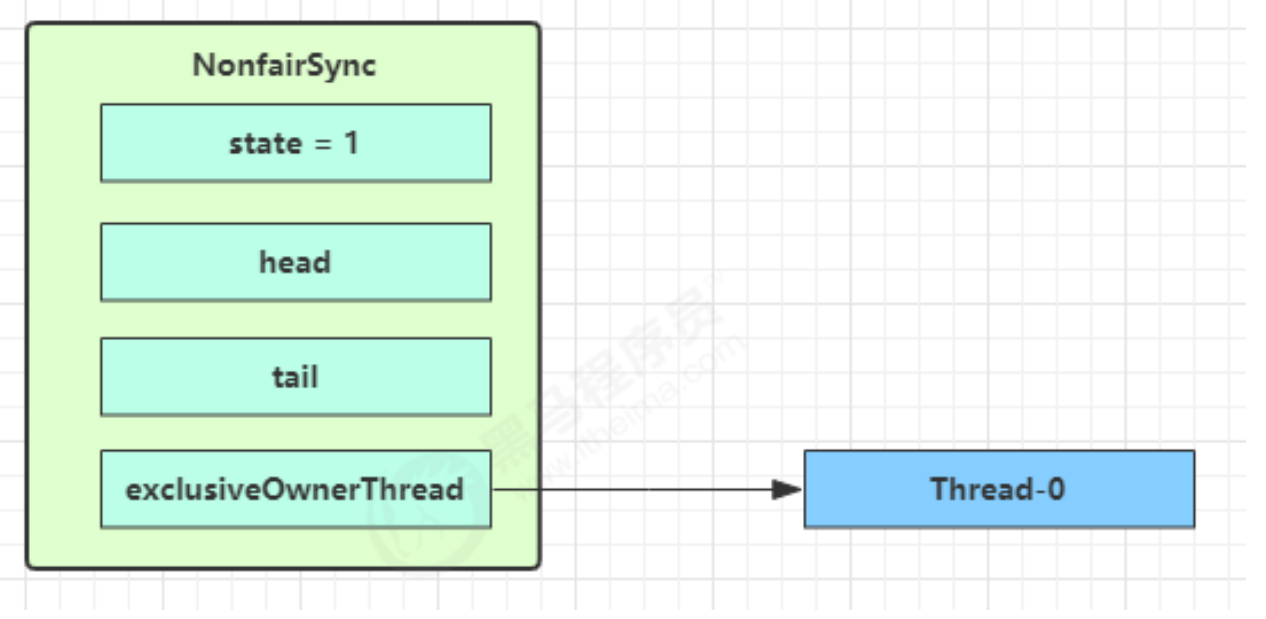
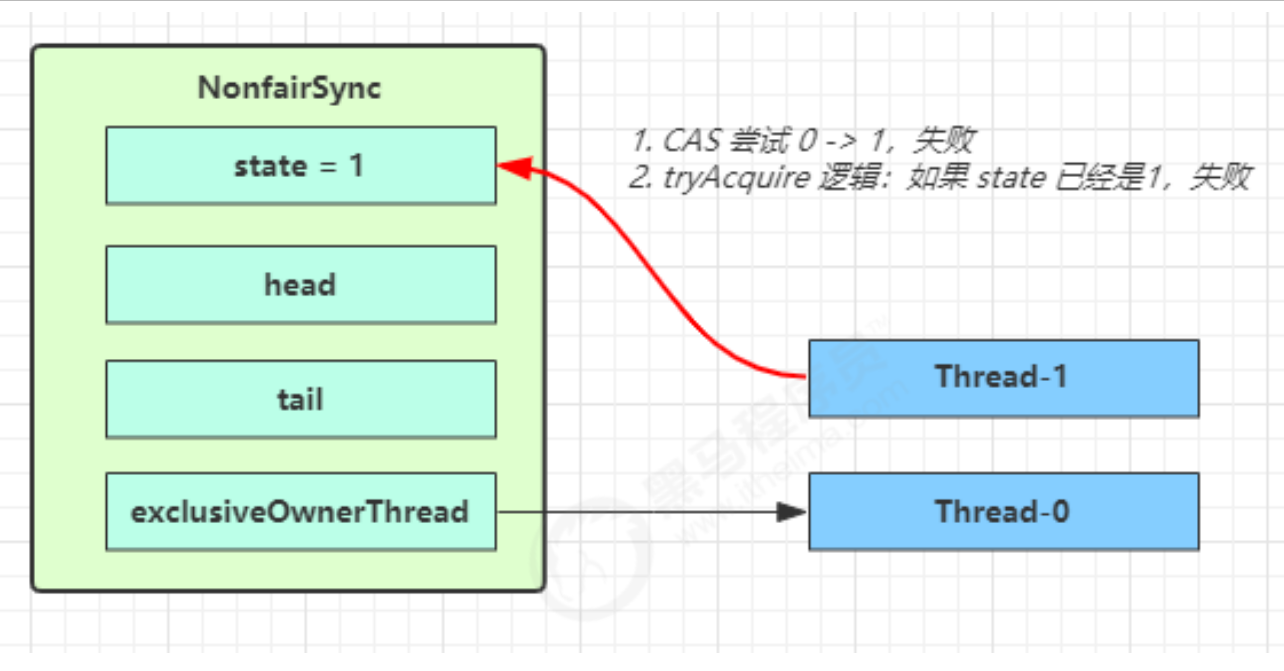
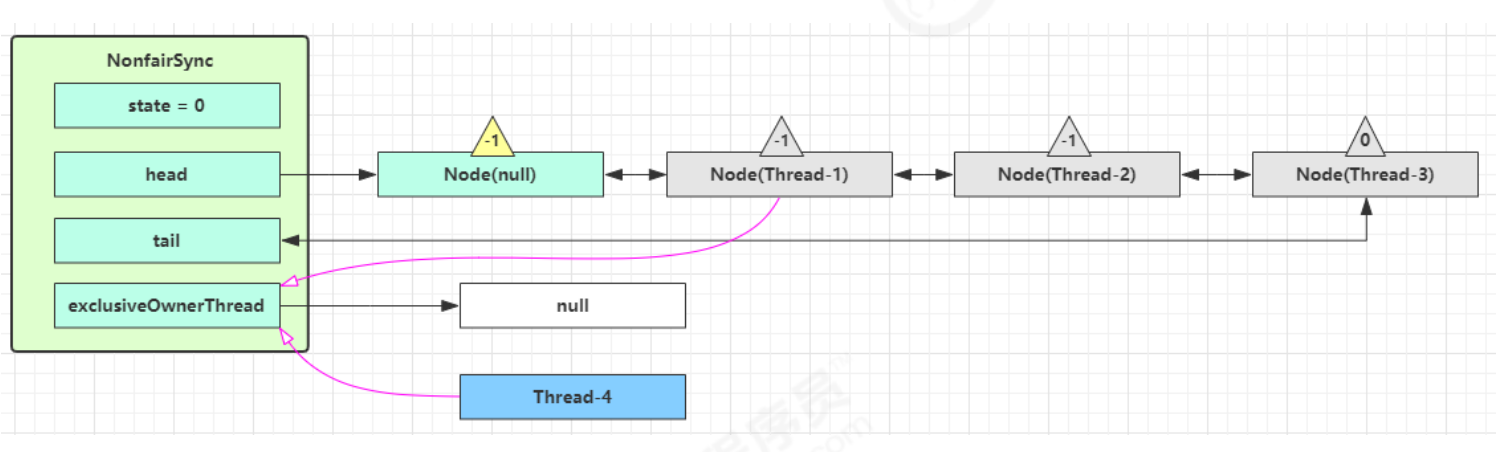
当 Thread-1 进行轻量级加锁时,Thread-0 已经对该对象加了轻量级锁
这时 Thread-1 加轻量级锁失败,进入锁膨胀流程
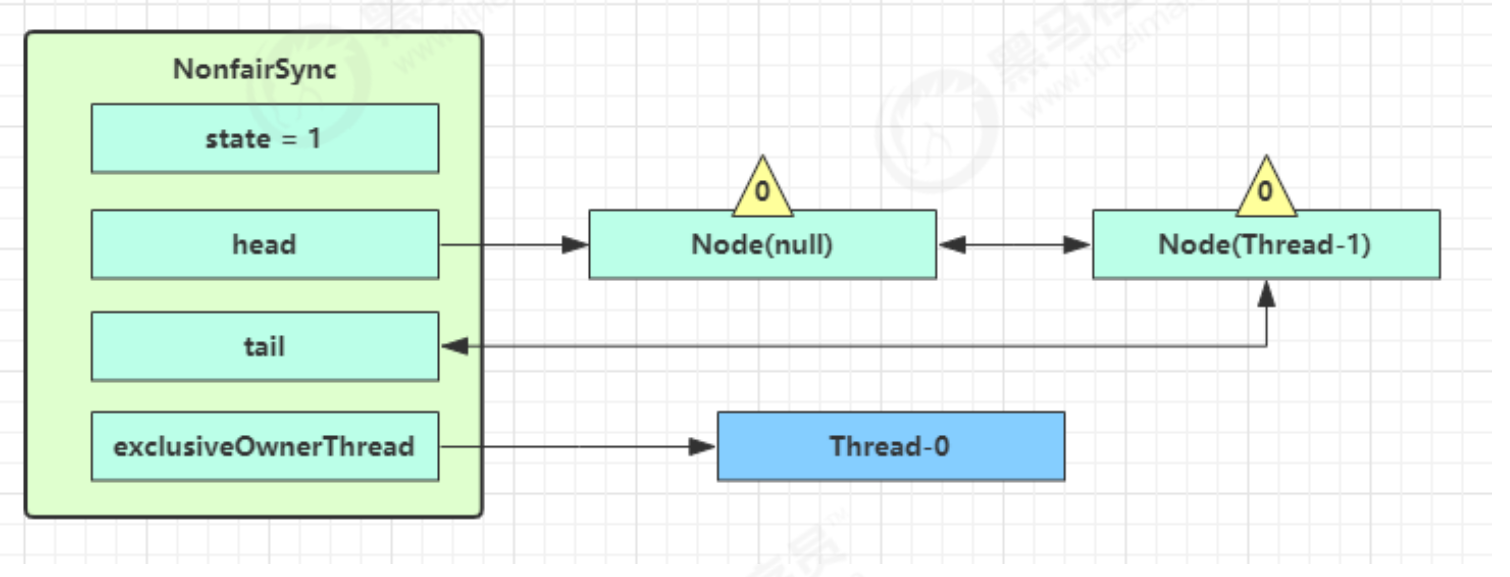
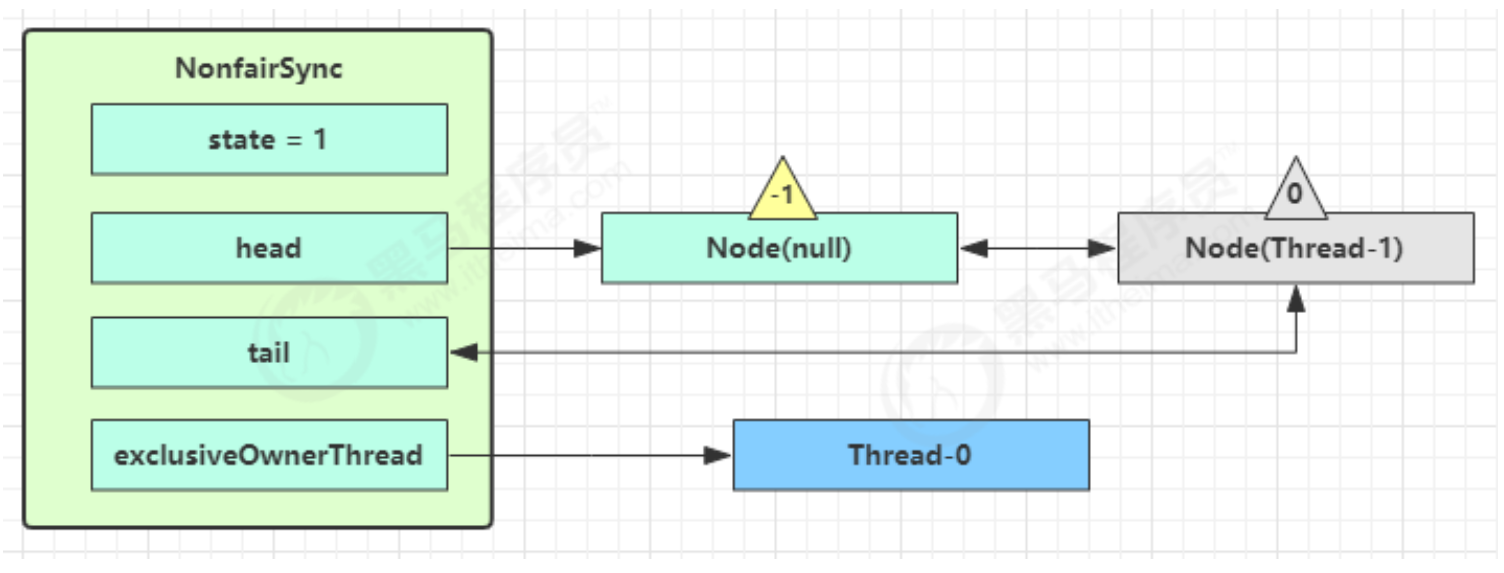
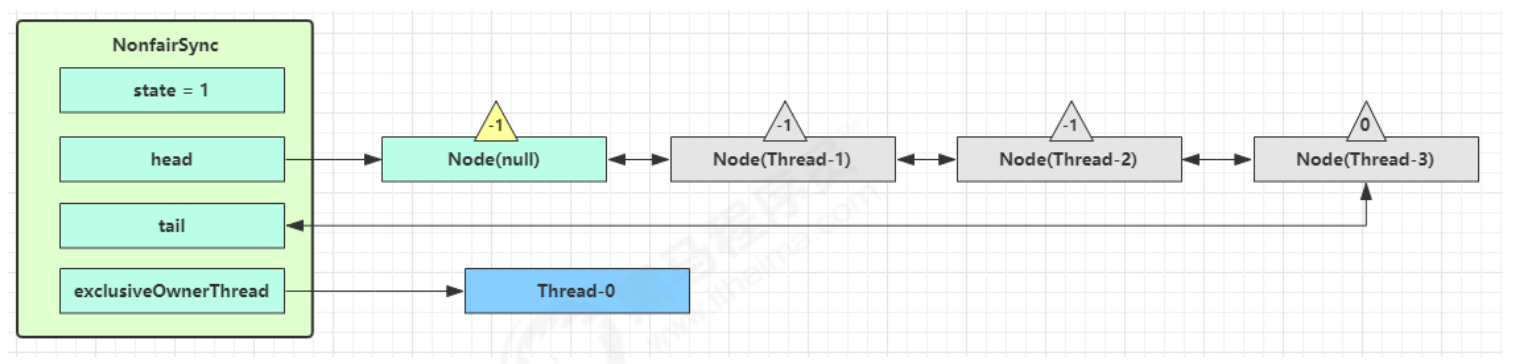
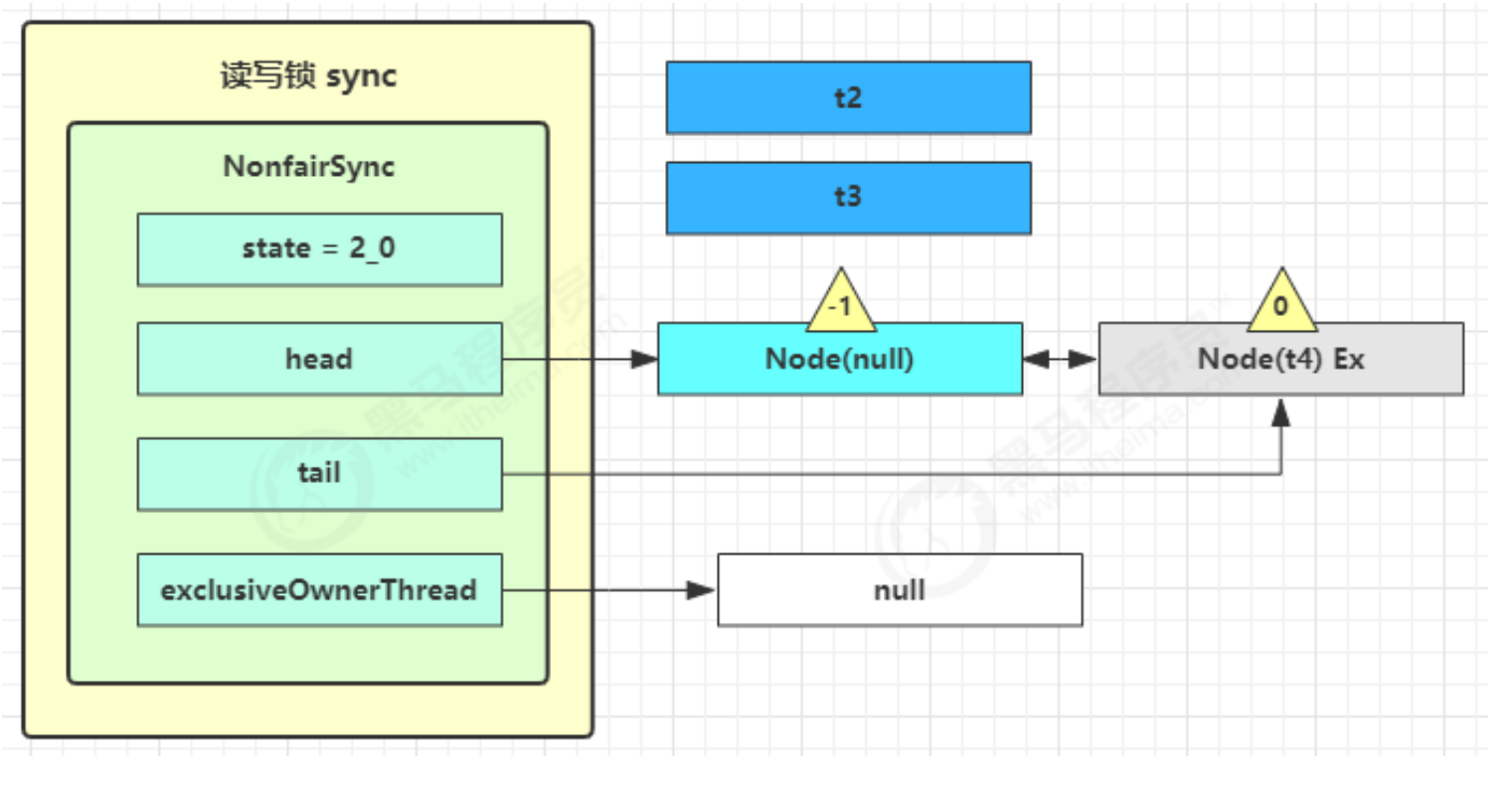
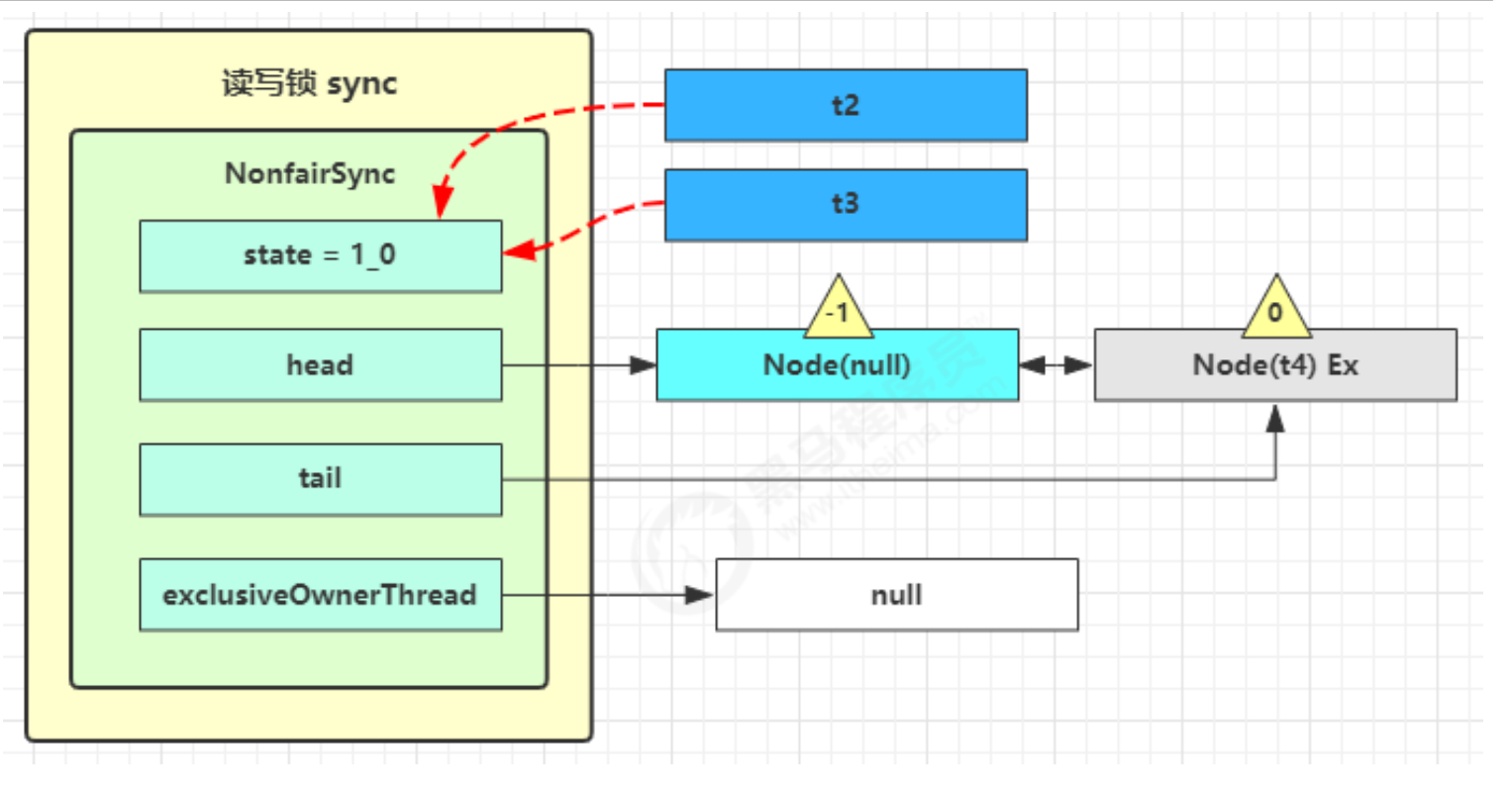
1.即为Object 对象(锁对象)申请 Monitor 锁 ,让 Object 指向重量级锁地址 (锁对象不再保存锁记录的引用地址)
2.然后自己进入 Monitor 的 EntryList 等待队列 中,并将自己的线程状态切换为阻塞状态
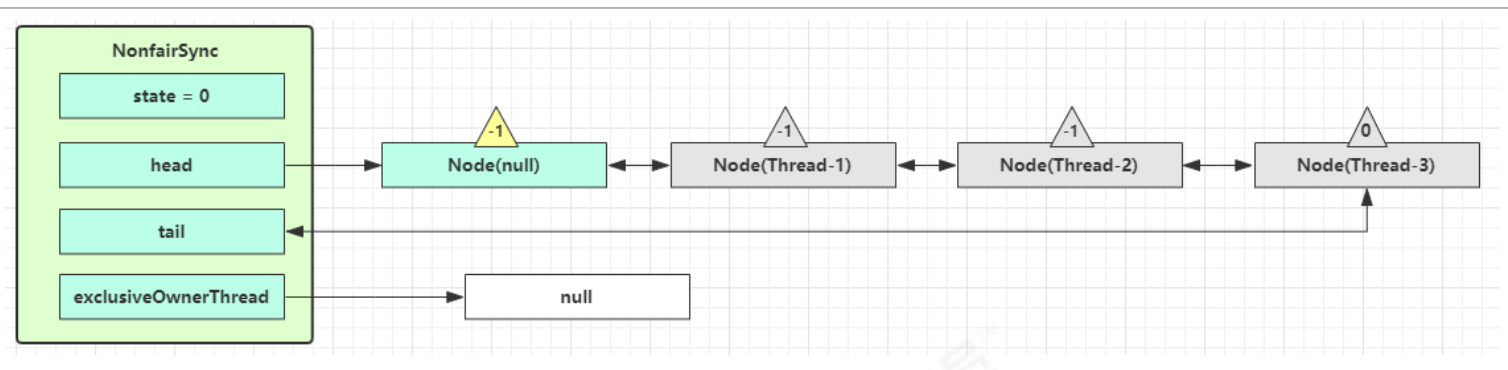
3.当 Thread-0 退出同步块解锁时,使用 cas 将 Mark Word 的值恢复给对象头,失败。这时会进入重量级解锁流程 ,即按照 Monitor 地址找到 Monitor 对象,设置 Owner 为 null,唤醒 EntryList 中 BLOCKED 线程
自旋优化 重量级锁竞争的时候,还可以使用自旋来进行优化,如果当前线程自旋成功(即这时候持锁线程已经退出了同步 块,释放了锁),这时当前线程就可以避免阻塞
实质上是通过避免线程状态的切换(从运行态切换为阻塞太),从而节约操作系统的资源,进而提高操作的性能
自旋重试成功的情况
线程1 ( core 1上)
对象Mark
线程2 ( core 2上)
-
10(重量锁)
-
访问同步块,获取monitor
10(重量锁)重量锁指针
-
成功(加锁)
10(重量锁)重量锁指针
-
执行同步块
10(重量锁)重量锁指针
-
执行同步块
10(重量锁)重量锁指针
访问同步块,获取 monitor
执行同步块
10(重量锁)重量锁指针
自旋重试
执行完毕
10(重量锁)重量锁指针
自旋重试
成功(解锁)
01(无锁)
自旋重试
-
10(重量锁)重量锁指针
成功(加锁)
-
10(重量锁)重量锁指针
执行同步块
-
…
…
自旋重试失败的情况
线程1 ( core 1上)
对象Mark
线程2( core 2上)
-
10(重量锁)
-
访问同步块,获取monitor
10(重量锁)重量锁指针
-
成功(加锁)
10(重量锁)重量锁指针
-
执行同步块
10(重量锁)重量锁指针
-
执行同步块
10(重量锁)重量锁指针
访问同步块,获取monitor
执行同步块
10(重量锁)重量锁指针
自旋重试
执行同步块
10(重量锁)重量锁指针
自旋重试
执行同步块
10(重量锁)重量锁指针
自旋重试
执行同步块
10(重量锁)重量锁指针
阻塞
-
…
…
自旋会占用 CPU 时间,单核 CPU 自旋就是浪费,多核 CPU 自旋才能发挥优势
在 Java 6 之后自旋锁是自适应的,比如对象刚刚的一次自旋操作成功过,那么认为这次自旋成功的可能性会 高,就多自旋几次;反之,就少自旋甚至不自旋,总之,比较智能 Java 7 之后不能控制是否开启自旋功能
偏向锁 轻量级锁在没有竞争时(就自己这个线程),每次重入仍然需要执行 CAS 操作,而CAS操作仍会消耗一定的性能
优化方案: 既然只有一个线程在操作了,并不存在其他线程干扰的问题,那能不能在重入锁时不需要执行CAS操作呢,只需要判断一下是不是自己的锁即可呢?
答案是能,用偏向锁优化轻量级锁即可
偏向锁来做进一步优化轻量级锁:
只有第一次使用 CAS 将线程 ID 设置到对象的 Mark Word 头,之后发现这个线程 ID是自己的就表示没有竞争,不用重新CAS。以后只要不发生竞争,这个对象就归该线程所有
例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 static final Object obj = new Object ();public static void m1 () { synchronized ( obj ) { m2(); } } public static void m2 () { synchronized ( obj ) { m3(); } } public static void m3 () { synchronized ( obj ) { } }
轻量级锁优化前后对比
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 graph LR subgraph 偏向锁 t5("m1内调用synchronized(obj)") t6("m2内调用synchronized(obj)") t7("m2内调用synchronized(obj)") t8(对象) t5 -.用ThreadID替换MarkWord.-> t8 t6 -.检查ThreadID是否是自己.-> t8 t7 -.检查ThreadID是否是自己.-> t8 end subgraph 轻量级锁 t1("m1内调用synchronized(obj)") t2("m2内调用synchronized(obj)") t3("m2内调用synchronized(obj)") t1 -.生成锁记录.-> t1 t2 -.生成锁记录.-> t2 t3 -.生成锁记录.-> t3 t4(对象) t1 -.用锁记录替换markword.-> t4 t2 -.用锁记录替换markword.-> t4 t3 -.用锁记录替换markword.-> t4 end
偏向状态 回忆一下对象头格式
1 2 3 4 5 6 7 8 9 10 11 12 13 |-------------------------------------------------------------------- |--------------------| Mark Word (64 bits) | State ||-------------------------------------------------------------------- |--------------------| unused: 25 | hashcode:31 | unused: 1 | age:4 | biased_lock: 0 | 01 | Normal |-------------------- || thread:54 | epoch: 2 | unused:1 | age: 4 | biased_lock:1 | 01 | Biased | |-------------------------------------------------------------------- |--------------------| ptr_to_lock_record: 62 | 00 | Lightweight Locked |-------------------- || ptr_to_heavyweight_monitor:62 | 10 | Heavyweight Locked | |-------------------------------------------------------------------- |--------------------| 11 | Marked for GC |-------------------- |
一个对象创建时:
如果开启了偏向锁(默认开启 ),那么对象创建后,markword 值为 0x05 即最后 3 位为 101,这时它的 thread、epoch、age 都为 0
偏向锁是默认是延迟的,不会在程序启动时立即生效,如果想避免延迟,可以加 VM 参数- XX:BiasedLockingStartupDelay=0来禁用延迟
如果没有开启偏向锁,那么对象创建后,markword 值为 0x01 即最后 3 位为 001,这时它的 hashcode、 age 都为 0,第一次用到 hashcode 时才会赋值
实质就是用对象头的MarkWork结构的倒数第三位表示是否启动偏向锁,如果是0表示未启用,如果是1表示启用偏向锁
1) 测试延迟特性
2) 测试偏向锁
利用 jol 第三方工具来查看对象头信息(注意这里我扩展了 jol 让它输出更为简洁)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public static void main (String[] args) throws IOException { Dog d = new Dog (); ClassLayout classLayout = ClassLayout.parseInstance(d); new Thread (() -> { log.debug("synchronized 前" ); System.out.println(classLayout.toPrintableSimple(true )); synchronized (d) { log.debug("synchronized 中" ); System.out.println(classLayout.toPrintableSimple(true )); } log.debug("synchronized 后" ); System.out.println(classLayout.toPrintableSimple(true )); }, "t1" ).start(); }
1 2 3 4 5 6 11:08:58.117 c.TestBiased [t1] - synchronized 前 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000101 11:08:58.121 c.TestBiased [t1] - synchronized 中 00000000 00000000 00000000 00000000 00011111 11101011 11010000 00000101 11:08:58.121 c.TestBiased [t1] - synchronized 后 00000000 00000000 00000000 00000000 00011111 11101011 11010000 00000101
注意
处于偏向锁的对象解锁后,线程 id 仍存储于对象头中
3)测试禁用
在上面测试代码运行时在添加 VM 参数 -XX:-UseBiasedLocking 禁用偏向锁
输出
1 2 3 4 5 6 11:13:10.018 c.TestBiased [t1] - synchronized 前 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001 11:13:10.021 c.TestBiased [t1] - synchronized 中 00000000 00000000 00000000 00000000 00100000 00010100 11110011 10001000 11:13:10.021 c.TestBiased [t1] - synchronized 后 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001
4)测试 hashCode
正常状态对象一开始是没有 hashCode 的,第一次调用才生成
撤销 - 调用对象 hashCode 调用了对象的 hashCode,但偏向锁的对象 MarkWord 中存储的是线程 id,如果调用 hashCode 会导致偏向锁被 撤销
因为对象头的空间有限,如果存储了hashCode就没有额外的空间存储线程id了
轻量级锁会在锁记录中记录 hashCode
重量级锁会在 Monitor 中记录 hashCode
在调用 hashCode 后使用偏向锁,记得去掉-XX:-UseBiasedLocking
输出
1 2 3 4 5 6 7 11:22:10.386 c.TestBiased [main] - 调用 hashCode:1778535015 11:22:10.391 c.TestBiased [t1] - synchronized 前 00000000 00000000 00000000 01101010 00000010 01001010 01100111 00000001 11:22:10.393 c.TestBiased [t1] - synchronized 中 00000000 00000000 00000000 00000000 00100000 11000011 11110011 01101000 11:22:10.393 c.TestBiased [t1] - synchronized 后 00000000 00000000 00000000 01101010 00000010 01001010 01100111 00000001
撤销 - 其它线程使用对象 当有其它线程使用偏向锁对象时,会将偏向锁升级为轻量级锁
因为有其他锁使用偏向锁对象,证明存在多个线程同时访问共享资源的去情况,必须将锁升级未轻量级锁,只有轻量级锁在遇到线程安全问题时将锁升级重量级锁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 private static void test2 () throws InterruptedException { Dog d = new Dog (); Thread t1 = new Thread (() -> { synchronized (d) { log.debug(ClassLayout.parseInstance(d).toPrintableSimple(true )); } synchronized (TestBiased.class) { TestBiased.class.notify(); } }, "t1" ); t1.start(); Thread t2 = new Thread (() -> { synchronized (TestBiased.class) { try { TestBiased.class.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } log.debug(ClassLayout.parseInstance(d).toPrintableSimple(true )); synchronized (d) { log.debug(ClassLayout.parseInstance(d).toPrintableSimple(true )); } log.debug(ClassLayout.parseInstance(d).toPrintableSimple(true )); }, "t2" ); t2.start(); }
输出
1 2 3 4 [t1] - 00000000 00000000 00000000 00000000 00011111 01000001 00010000 00000101 [t2] - 00000000 00000000 00000000 00000000 00011111 01000001 00010000 00000101 [t2] - 00000000 00000000 00000000 00000000 00011111 10110101 11110000 01000000 [t2] - 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001
撤销 - 调用 wait/notify 因为wait/notify本身就是重量级锁的api,如果在偏向锁中要想使用重量级锁的api,必须将偏向锁升级为重量级锁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public static void main (String[] args) throws InterruptedException { Dog d = new Dog (); Thread t1 = new Thread (() -> { log.debug(ClassLayout.parseInstance(d).toPrintableSimple(true )); synchronized (d) { log.debug(ClassLayout.parseInstance(d).toPrintableSimple(true )); try { d.wait(); } catch (InterruptedException e) { e.printStackTrace(); } log.debug(ClassLayout.parseInstance(d).toPrintableSimple(true )); } }, "t1" ); t1.start(); new Thread (() -> { try { Thread.sleep(6000 ); } catch (InterruptedException e) { e.printStackTrace(); } synchronized (d) { log.debug("notify" ); d.notify(); } }, "t2" ).start(); }
输出
1 2 3 4 [t1] - 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000101 [t1] - 00000000 00000000 00000000 00000000 00011111 10110011 11111000 00000101 [t2] - notify [t1] - 00000000 00000000 00000000 00000000 00011100 11010100 00001101 11001010
批量重偏向 如果对象虽然被多个线程访问,但没有竞争,这时偏向了线程 T1 的对象仍有机会重新偏向 T2,重偏向会重置对象 的 Thread ID
当撤销偏向锁阈值超过 20 次后,jvm 会这样觉得,我是不是偏向错了呢,于是会在给这些对象加锁时重新偏向至 加锁线程
案例演示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 private static void test3 () throws InterruptedException { Vector<Dog> list = new Vector <>(); Thread t1 = new Thread (() -> { for (int i = 0 ; i < 30 ; i++) { Dog d = new Dog (); list.add(d); synchronized (d) { log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintableSimple(true )); } } synchronized (list) { list.notify(); } }, "t1" ); t1.start(); Thread t2 = new Thread (() -> { synchronized (list) { try { list.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } log.debug("===============> " ); for (int i = 0 ; i < 30 ; i++) { Dog d = list.get(i); log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintableSimple(true )); synchronized (d) { log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintableSimple(true )); } log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintableSimple(true )); } }, "t2" ); t2.start(); }
输出验证
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 [t1] - 0 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 1 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 2 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 3 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 4 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 5 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 6 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 7 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 8 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 9 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 10 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 11 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 12 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 13 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 14 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 15 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 16 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 17 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 18 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 19 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 20 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 21 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 22 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 23 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 24 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 25 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 26 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 27 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 28 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t1] - 29 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - ===============> [t2] - 0 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 0 00000000 00000000 00000000 00000000 00100000 01011000 11110111 00000000 [t2] - 0 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001 [t2] - 1 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 1 00000000 00000000 00000000 00000000 00100000 01011000 11110111 00000000 [t2] - 1 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001 [t2] - 2 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 2 00000000 00000000 00000000 00000000 00100000 01011000 11110111 00000000 [t2] - 2 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001 [t2] - 3 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 3 00000000 00000000 00000000 00000000 00100000 01011000 11110111 00000000 [t2] - 3 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001 [t2] - 4 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 4 00000000 00000000 00000000 00000000 00100000 01011000 11110111 00000000 [t2] - 4 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001 [t2] - 5 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 5 00000000 00000000 00000000 00000000 00100000 01011000 11110111 00000000 [t2] - 5 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001 [t2] - 6 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 6 00000000 00000000 00000000 00000000 00100000 01011000 11110111 00000000 [t2] - 6 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001 [t2] - 7 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 7 00000000 00000000 00000000 00000000 00100000 01011000 11110111 00000000 [t2] - 7 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001 [t2] - 8 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 8 00000000 00000000 00000000 00000000 00100000 01011000 11110111 00000000 [t2] - 8 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001 [t2] - 9 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 9 00000000 00000000 00000000 00000000 00100000 01011000 11110111 00000000 [t2] - 9 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001 [t2] - 10 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 10 00000000 00000000 00000000 00000000 00100000 01011000 11110111 00000000 [t2] - 10 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001 [t2] - 11 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 11 00000000 00000000 00000000 00000000 00100000 01011000 11110111 00000000 [t2] - 11 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001 [t2] - 12 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 12 00000000 00000000 00000000 00000000 00100000 01011000 11110111 00000000 [t2] - 12 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001 [t2] - 13 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 13 00000000 00000000 00000000 00000000 00100000 01011000 11110111 00000000 [t2] - 13 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001 [t2] - 14 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 14 00000000 00000000 00000000 00000000 00100000 01011000 11110111 00000000 [t2] - 14 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001 [t2] - 15 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 15 00000000 00000000 00000000 00000000 00100000 01011000 11110111 00000000 [t2] - 15 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001 [t2] - 16 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 16 00000000 00000000 00000000 00000000 00100000 01011000 11110111 00000000 [t2] - 16 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001 [t2] - 17 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 17 00000000 00000000 00000000 00000000 00100000 01011000 11110111 00000000 [t2] - 17 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001 [t2] - 18 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 18 00000000 00000000 00000000 00000000 00100000 01011000 11110111 00000000 [t2] - 18 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001 [t2] - 19 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 19 00000000 00000000 00000000 00000000 00011111 11110011 11110001 00000101 [t2] - 19 00000000 00000000 00000000 00000000 00011111 11110011 11110001 00000101 [t2] - 20 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 20 00000000 00000000 00000000 00000000 00011111 11110011 11110001 00000101 [t2] - 20 00000000 00000000 00000000 00000000 00011111 11110011 11110001 00000101 [t2] - 21 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 21 00000000 00000000 00000000 00000000 00011111 11110011 11110001 00000101 [t2] - 21 00000000 00000000 00000000 00000000 00011111 11110011 11110001 00000101 [t2] - 22 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 22 00000000 00000000 00000000 00000000 00011111 11110011 11110001 00000101 [t2] - 22 00000000 00000000 00000000 00000000 00011111 11110011 11110001 00000101 [t2] - 23 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 23 00000000 00000000 00000000 00000000 00011111 11110011 11110001 00000101 [t2] - 23 00000000 00000000 00000000 00000000 00011111 11110011 11110001 00000101 [t2] - 24 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 24 00000000 00000000 00000000 00000000 00011111 11110011 11110001 00000101 [t2] - 24 00000000 00000000 00000000 00000000 00011111 11110011 11110001 00000101 [t2] - 25 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 25 00000000 00000000 00000000 00000000 00011111 11110011 11110001 00000101 [t2] - 25 00000000 00000000 00000000 00000000 00011111 11110011 11110001 00000101 [t2] - 26 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 26 00000000 00000000 00000000 00000000 00011111 11110011 11110001 00000101 [t2] - 26 00000000 00000000 00000000 00000000 00011111 11110011 11110001 00000101 [t2] - 27 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 27 00000000 00000000 00000000 00000000 00011111 11110011 11110001 00000101 [t2] - 27 00000000 00000000 00000000 00000000 00011111 11110011 11110001 00000101 [t2] - 28 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 28 00000000 00000000 00000000 00000000 00011111 11110011 11110001 00000101 [t2] - 28 00000000 00000000 00000000 00000000 00011111 11110011 11110001 00000101 [t2] - 29 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 [t2] - 29 00000000 00000000 00000000 00000000 00011111 11110011 11110001 00000101 [t2] - 29 00000000 00000000 00000000 00000000 00011111 11110011 11110001 00000101
批量撤销 当撤销偏向锁阈值超过 40 次后,jvm 会这样觉得,自己确实偏向错了,根本就不该偏向。于是整个类的所有对象 都会变为不可偏向的,新建的对象也是不可偏向的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 static Thread t1,t2,t3;private static void test4 () throws InterruptedException { Vector<Dog> list = new Vector <>(); int loopNumber = 39 ; t1 = new Thread (() -> { for (int i = 0 ; i < loopNumber; i++) { Dog d = new Dog (); list.add(d); synchronized (d) { log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintableSimple(true )); } } LockSupport.unpark(t2); }, "t1" ); t1.start(); t2 = new Thread (() -> { LockSupport.park(); log.debug("===============> " ); for (int i = 0 ; i < loopNumber; i++) { Dog d = list.get(i); log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintableSimple(true )); synchronized (d) { log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintableSimple(true )); } log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintableSimple(true )); } LockSupport.unpark(t3); }, "t2" ); t2.start(); t3 = new Thread (() -> { LockSupport.park(); log.debug("===============> " ); for (int i = 0 ; i < loopNumber; i++) { Dog d = list.get(i); log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintableSimple(true )); synchronized (d) { log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintableSimple(true )); } log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintableSimple(true )); } }, "t3" ); t3.start(); t3.join(); log.debug(ClassLayout.parseInstance(new Dog ()).toPrintableSimple(true )); }
参考资料
https://github.com/farmerjohngit/myblog/issues/12
https://www.cnblogs.com/LemonFive/p/11246086.html
https://www.cnblogs.com/LemonFive/p/11248248.html
[偏向锁论文](Eliminating Synchronization-Related Atomic Operations with Biased Locking and Bulk Rebiasing (oracle.com) )
锁消除 锁消除:Java编译器会自行优化实际上不需要加锁的代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Fork(1) @BenchmarkMode(Mode.AverageTime) @Warmup(iterations=3) @Measurement(iterations=5) @OutputTimeUnit(TimeUnit.NANOSECONDS) public class MyBenchmark { static int x = 0 ; @Benchmark public void a () throws Exception { x++; } @Benchmark public void b () throws Exception { Object o = new Object (); synchronized (o) { x++; } } }
a方法没有加锁和b方法加了锁的性能对比,二者性能差异不大,证明Java编译器底层对b方法进行了消除锁的优化
java -jar benchmarks.jar
1 2 3 Benchmark Mode Samples Score Score error Units c.i.MyBenchmark.a avgt 5 1.542 0.056 ns/op c.i.MyBenchmark.b avgt 5 1.518 0.091 ns/op
java -XX:-EliminateLocks -jar benchmarks.jar
1 2 3 Benchmark Mode Samples Score Score error Units c.i.MyBenchmark.a avgt 5 1.507 0.108 ns/op c.i.MyBenchmark.b avgt 5 16.976 1.572 ns/op
锁粗化
对相同对象多次加锁,导致线程发生多次重入,可以使用锁粗化方式来优化,这不同于之前讲的细分锁的粒度。
总结 1.Monitor是什么?
Monitor是一种重量级锁的数据结构,他有waitset等待队列,entrylist阻塞队列,owner锁的主人三种属性,waitset存储阻塞类型为wating,timed_waiting状态的线程,而entrylist则存储blocked状态的线程,owner存储锁的主人,即线程id
2.为什么需要重量级锁Monitor?
因为重量级锁Monitor可以实现线程访问共享资源的串行性,进而解决并发线程中的线程安全问题
3.如何使用重量级锁?
使用synchronized关键字配合重量级锁的相关功能api(如wait,notify,notifyAll)即可,需要深入理解synchronized关键字的原理,重量级锁Monitor的结构以及重量级锁的每一个功能api的实现原理才能合理的使用重量级锁
wait notify 原理之 wait / notify wait/notify是属于重量级锁Monitor的相关功能,所以其原理和重量级锁Monitor结构有很大的关联

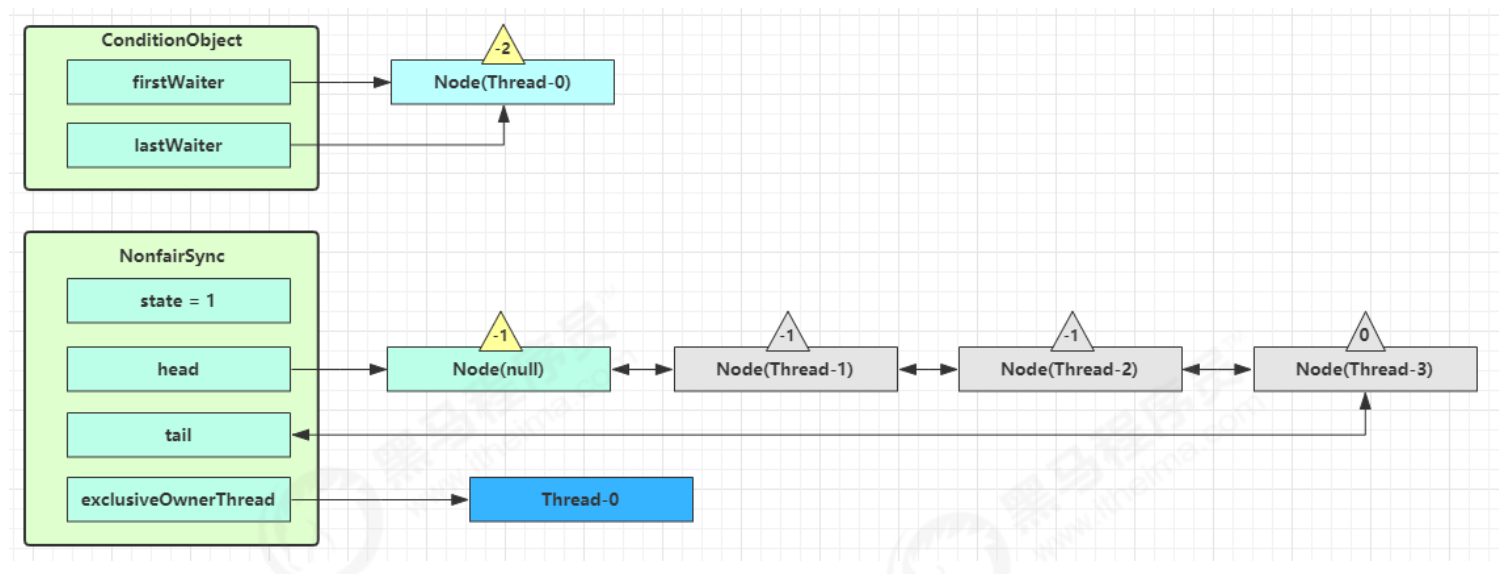
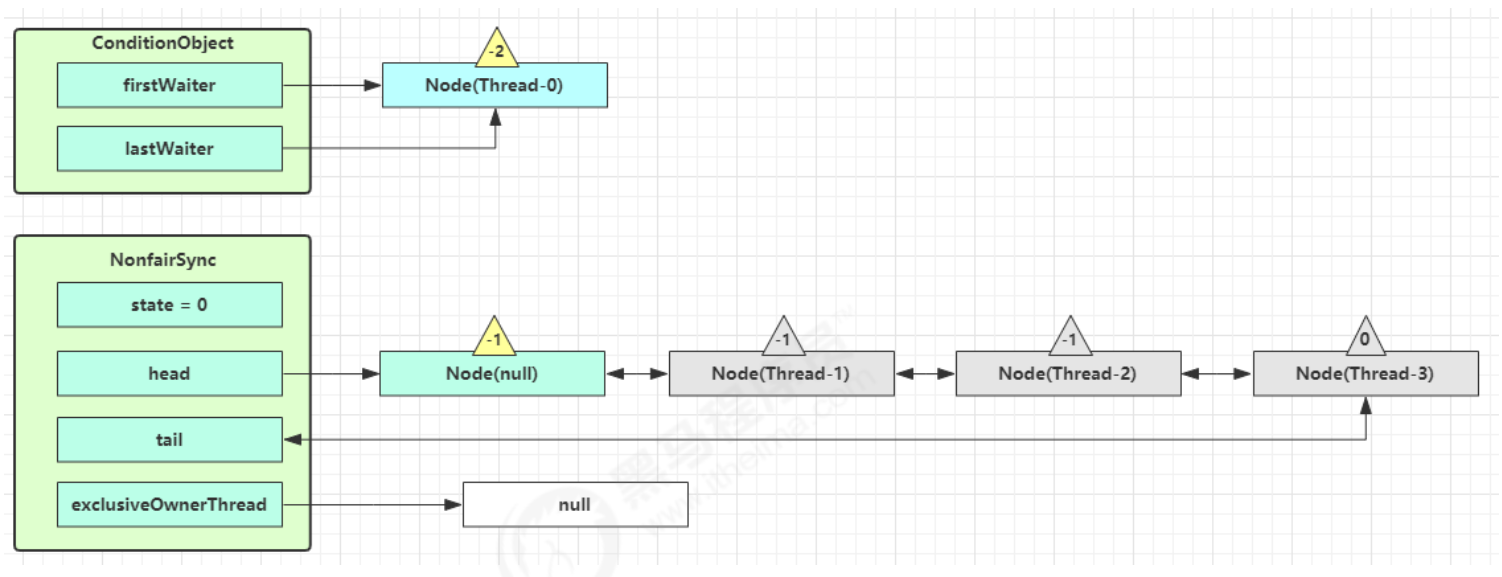
Owner 线程发现条件不满足,调用 wait 方法,即可进入 WaitSet等待队列变为 WAITING 状态
BLOCKED 和 WAITING 的线程都处于阻塞状态,不占用 CPU 时间片 BLOCKED 线程会在 Owner 线程释放锁时唤醒 WAITING 线程会在 Owner 线程调用 notify 或 notifyAll 时唤醒,但唤醒后并不意味者立刻获得锁,仍需进入 EntryList 重新竞争
API 介绍
obj.wait() 让进入 object 监视器的线程到 waitSet 等待 obj.notify() 在 object 上正在 waitSet 等待的线程中挑一个唤醒 obj.notifyAll() 让 object 上正在 waitSet 等待的线程全部唤醒
它们都是线程之间进行协作的手段,都属于 Object 对象的方法,且都需要获取了重量级锁资源之后才能调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 final static Object obj = new Object ();public static void main (String[] args) { new Thread (() -> { synchronized (obj) { log.debug("执行...." ); try { obj.wait(); } catch (InterruptedException e) { e.printStackTrace(); } log.debug("其它代码...." ); } }).start(); new Thread (() -> { synchronized (obj) { log.debug("执行...." ); try { obj.wait(); } catch (InterruptedException e) { e.printStackTrace(); } log.debug("其它代码...." ); } }).start(); sleep(2 ); log.debug("唤醒 obj 上其它线程" ); synchronized (obj) { obj.notify(); } }
notify 的一种结果
1 2 3 4 20:00:53.096 [Thread-0] c.TestWaitNotify - 执行.... 20:00:53.099 [Thread-1] c.TestWaitNotify - 执行.... 20:00:55.096 [main] c.TestWaitNotify - 唤醒 obj 上其它线程 20:00:55.096 [Thread-0] c.TestWaitNotify - 其它代码....
notifyAll 的结果
1 2 3 4 5 19:58:15.457 [Thread-0] c.TestWaitNotify - 执行.... 19:58:15.460 [Thread-1] c.TestWaitNotify - 执行.... 19:58:17.456 [main] c.TestWaitNotify - 唤醒 obj 上其它线程 19:58:17.456 [Thread-1] c.TestWaitNotify - 其它代码.... 19:58:17.456 [Thread-0] c.TestWaitNotify - 其它代码....
wait() 方法会释放对象的锁,进入 WaitSet 等待区,从而让其他线程就机会获取对象的锁。无限制等待,直到 notify 为止
wait(long n) 有时限的等待, 到 n 毫秒后结束等待,或是被 notify
wait notify 的正确用法 开始之前先看看
sleep(long n) 和 wait(long n) 的区别
sleep 是 Thread 方法,而 wait 是 Object 的方法
sleep 不需要强制和 synchronized 配合使用,但 wait 需要 和 synchronized 一起用
sleep 在睡眠的同时,不会释放对象锁的,但 wait 在等待的时候会释放对象锁 它们 状态 TIMED_WAITING
核心共同点:都会让出CPU的执行权
核心区别:sleep方法不会释放锁资源,而wait方法会释放锁资源
step 1 1 2 3 static final Object room = new Object ();static boolean hasCigarette = false ;static boolean hasTakeout = false ;
思考下面的解决方案好不好,为什么?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 new Thread (() -> { synchronized (room) { log.debug("有烟没?[{}]" , hasCigarette); if (!hasCigarette) { log.debug("没烟,先歇会!" ); sleep(2 ); } log.debug("有烟没?[{}]" , hasCigarette); if (hasCigarette) { log.debug("可以开始干活了" ); } } }, "小南" ).start(); for (int i = 0 ; i < 5 ; i++) { new Thread (() -> { synchronized (room) { log.debug("可以开始干活了" ); } }, "其它人" ).start(); } sleep(1 ); new Thread (() -> { hasCigarette = true ; log.debug("烟到了噢!" ); }, "送烟的" ).start();
输出
1 2 3 4 5 6 7 8 9 10 20:49:49.883 [小南] c.TestCorrectPosture - 有烟没?[false ] 20:49:49.887 [小南] c.TestCorrectPosture - 没烟,先歇会! 20:49:50.882 [送烟的] c.TestCorrectPosture - 烟到了噢! 20:49:51.887 [小南] c.TestCorrectPosture - 有烟没?[true ] 20:49:51.887 [小南] c.TestCorrectPosture - 可以开始干活了 20:49:51.887 [其它人] c.TestCorrectPosture - 可以开始干活了 20:49:51.887 [其它人] c.TestCorrectPosture - 可以开始干活了 20:49:51.888 [其它人] c.TestCorrectPosture - 可以开始干活了 20:49:51.888 [其它人] c.TestCorrectPosture - 可以开始干活了 20:49:51.888 [其它人] c.TestCorrectPosture - 可以开始干活了
其它干活的线程,都要一直阻塞,效率太低(就是因为sleep方法不会释放锁资源) 小南线程必须睡足 2s 后才能醒来,就算烟提前送到,也无法立刻醒来 (sleep方法缺乏notify的及时唤醒机制)
加了 synchronized (room) 后,就好比小南在里面反锁了门睡觉,烟根本没法送进门,main 没加 synchronized 就好像 main 线程是翻窗户进来的
解决方法,使用 wait - notify 机制
step 2 思考下面的实现行吗,为什么?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 new Thread (() -> { synchronized (room) { log.debug("有烟没?[{}]" , hasCigarette); if (!hasCigarette) { log.debug("没烟,先歇会!" ); try { room.wait(2000 ); } catch (InterruptedException e) { e.printStackTrace(); } } log.debug("有烟没?[{}]" , hasCigarette); if (hasCigarette) { log.debug("可以开始干活了" ); } } }, "小南" ).start(); for (int i = 0 ; i < 5 ; i++) { new Thread (() -> { synchronized (room) { log.debug("可以开始干活了" ); } }, "其它人" ).start(); } sleep(1 ); new Thread (() -> { synchronized (room) { hasCigarette = true ; log.debug("烟到了噢!" ); room.notify(); } }, "送烟的" ).start();
解决了其它干活的线程阻塞的问题 但如果有其它线程也在等待条件呢?
step 3 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 new Thread (() -> { synchronized (room) { log.debug("有烟没?[{}]" , hasCigarette); if (!hasCigarette) { log.debug("没烟,先歇会!" ); try { room.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } log.debug("有烟没?[{}]" , hasCigarette); if (hasCigarette) { log.debug("可以开始干活了" ); } else { log.debug("没干成活..." ); } } }, "小南" ).start(); new Thread (() -> { synchronized (room) { Thread thread = Thread.currentThread(); log.debug("外卖送到没?[{}]" , hasTakeout); if (!hasTakeout) { log.debug("没外卖,先歇会!" ); try { room.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } log.debug("外卖送到没?[{}]" , hasTakeout); if (hasTakeout) { log.debug("可以开始干活了" ); } else { log.debug("没干成活..." ); } } }, "小女" ).start(); sleep(1 ); new Thread (() -> { synchronized (room) { hasTakeout = true ; log.debug("外卖到了噢!" ); room.notify(); } }, "送外卖的" ).start();
输出
1 2 3 4 5 6 7 20:53:12.173 [小南] c.TestCorrectPosture - 有烟没?[false ] 20:53:12.176 [小南] c.TestCorrectPosture - 没烟,先歇会! 20:53:12.176 [小女] c.TestCorrectPosture - 外卖送到没?[false ] 20:53:12.176 [小女] c.TestCorrectPosture - 没外卖,先歇会! 20:53:13.174 [送外卖的] c.TestCorrectPosture - 外卖到了噢! 20:53:13.174 [小南] c.TestCorrectPosture - 有烟没?[false ] 20:53:13.174 [小南] c.TestCorrectPosture - 没干成活...
step 4 1 2 3 4 5 6 7 new Thread (() -> { synchronized (room) { hasTakeout = true ; log.debug("外卖到了噢!" ); room.notifyAll(); } }, "送外卖的" ).start();
输出
1 2 3 4 5 6 7 8 9 20:55:23.978 [小南] c.TestCorrectPosture - 有烟没?[false ] 20:55:23.982 [小南] c.TestCorrectPosture - 没烟,先歇会! 20:55:23.982 [小女] c.TestCorrectPosture - 外卖送到没?[false ] 20:55:23.982 [小女] c.TestCorrectPosture - 没外卖,先歇会! 20:55:24.979 [送外卖的] c.TestCorrectPosture - 外卖到了噢! 20:55:24.979 [小女] c.TestCorrectPosture - 外卖送到没?[true ] 20:55:24.980 [小女] c.TestCorrectPosture - 可以开始干活了 20:55:24.980 [小南] c.TestCorrectPosture - 有烟没?[false ] 20:55:24.980 [小南] c.TestCorrectPosture - 没干成活...
用 notifyAll 仅解决某个线程的唤醒问题,但使用 if + wait 判断仅有一次机会,一旦条件不成立,就没有重新判断的机会了
就比如案例中虽然正确唤醒送外卖的线程,但与此同时也会唤醒送烟的线程,并且其实送烟的线程此时还没有烟这个资源就被唤醒了,应该继续等待下一次的唤醒,但使用if+wait只有一次判断是否有送烟的资源,如果第一次唤醒没有烟的资源送过来,那后续就再也没有机会唤醒送烟的线程了
核心:实际上就是notifyAll会唤醒所有线程,导致除了真正获取到相应的资源的线程可以继续执行外,其他线程都是被虚假唤醒的,应再次进入等待状态(阻塞状态),等待唤醒,而If+wait只有一次判断资源和等待的机会,如果因为虚假唤醒了,就再也没有机会进入等待状态等待相应的资源再唤醒了
解决方法,用 while + wait,当条件不成立,再次 wait
step 5 将 if 改为 while
1 2 3 4 5 6 7 8 if (!hasCigarette) { log.debug("没烟,先歇会!" ); try { room.wait(); } catch (InterruptedException e) { e.printStackTrace(); } }
改动后
1 2 3 4 5 6 7 8 while (!hasCigarette) { log.debug("没烟,先歇会!" ); try { room.wait(); } catch (InterruptedException e) { e.printStackTrace(); } }
只有线程被唤醒才会接着while,不唤醒就是wait,所以不会有cpu空转
输出
1 2 3 4 5 6 7 8 20:58:34.322 [小南] c.TestCorrectPosture - 有烟没?[false ] 20:58:34.326 [小南] c.TestCorrectPosture - 没烟,先歇会! 20:58:34.326 [小女] c.TestCorrectPosture - 外卖送到没?[false ] 20:58:34.326 [小女] c.TestCorrectPosture - 没外卖,先歇会! 20:58:35.323 [送外卖的] c.TestCorrectPosture - 外卖到了噢! 20:58:35.324 [小女] c.TestCorrectPosture - 外卖送到没?[true ] 20:58:35.324 [小女] c.TestCorrectPosture - 可以开始干活了 20:58:35.324 [小南] c.TestCorrectPosture - 没烟,先歇会!
正确用法 1 2 3 4 5 6 7 8 9 10 11 12 synchronized (lock) { while (条件不成立) { lock.wait(); } } synchronized (lock) { lock.notifyAll(); }
总结 1.wait/notify/notifyAll是什么?
wait/notify/notifyAll是重量级锁的功能api,可以实现让当前运行线程释放锁,还可以唤醒正处于waiting状态的线程
2.为什么需要wait/notify?他的使用场景是什么?
让获取了锁资源但缺乏其他资源不能有效运行的线程及时的释放掉锁资源,让其他线程能够及时的获取锁资源执行相应的任务,大大提高了线程的并发性
3.如何使用wait/notify/notifyAll?
需要搭配synchronized关键字使用,而且必须获取了锁资源之后才能使用(也就是必须在synchronized同步代码内使用)
那为什么必须获取到锁资源才能调用这几个方法呢?
A.首先wait方法本身就是针对获取了锁资源但缺乏其他资源不能及时有效运行从而导致锁资源没有得到及时释放的场景,所以调用wait方法必须先获取锁资源才能释放锁资源呀
B.notify/notifyAll,从wait()原理上来理解,一旦调用了wait方法及时释放了锁资源,线程的状态就会变成Wating状态(也属于阻塞状态的一种),进入到等待队列WaitSet中,而等待队列WaitSet属于锁资源的一部分,如果你不先获取到锁资源,那么你怎么能获取到等待队列WaitSet,进而唤醒队列中的线程呢
4.注意细节:
调用了wait()方法一定要调用相应的notify/notifyAll方法唤醒线程,否则线程将一直阻塞下去,程序也会因为有非守护线程没执行完而一直不能结束
一句话概括注意细节:
wait和notify/notifyAll一定要成对出现,有多少个wait就要有多少个notify/notifyAll
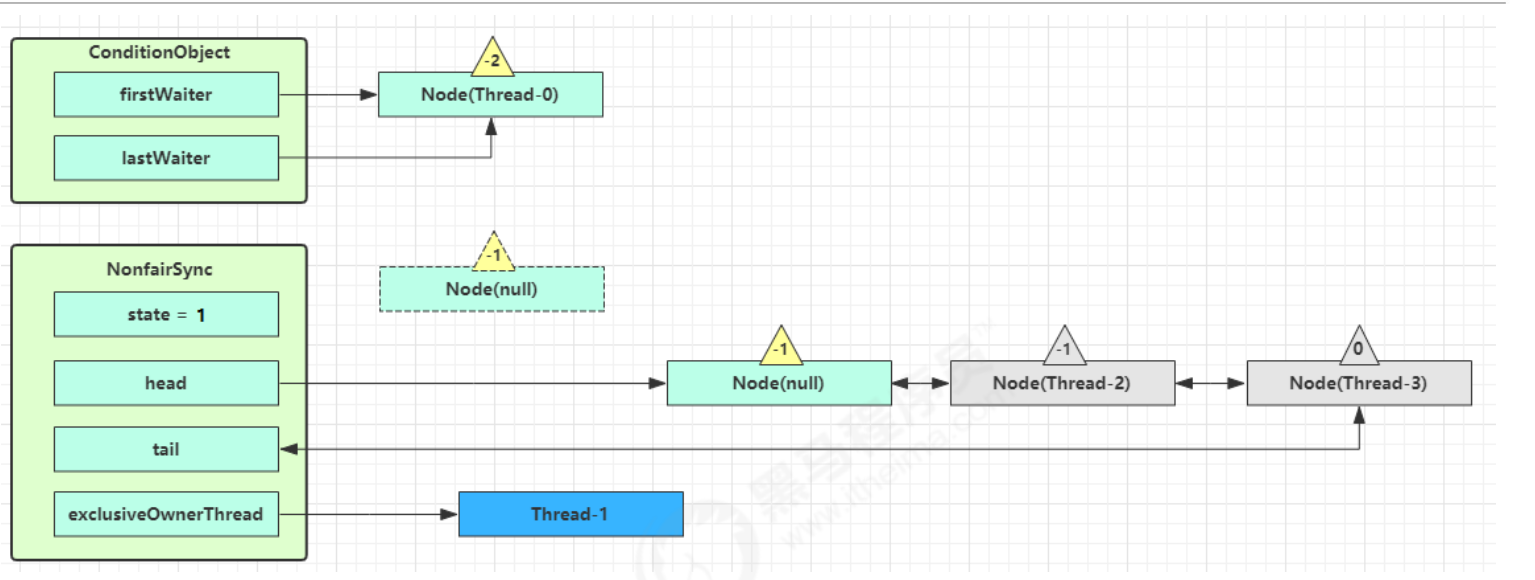
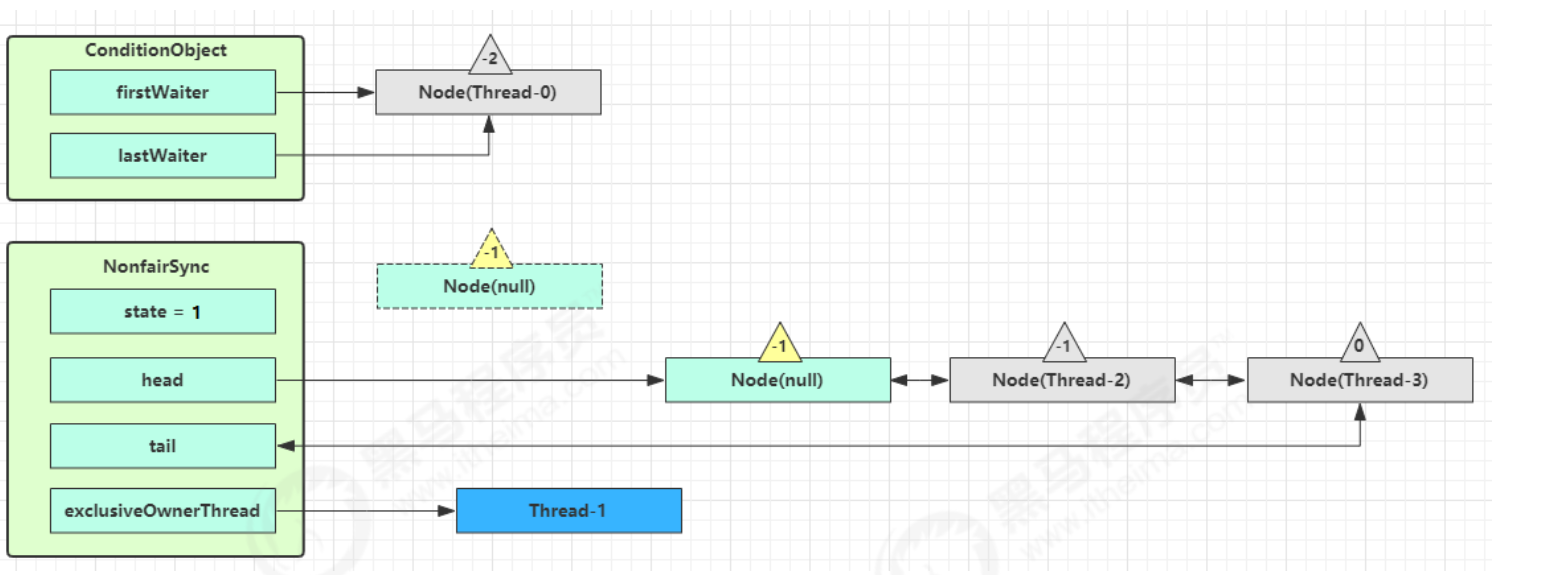
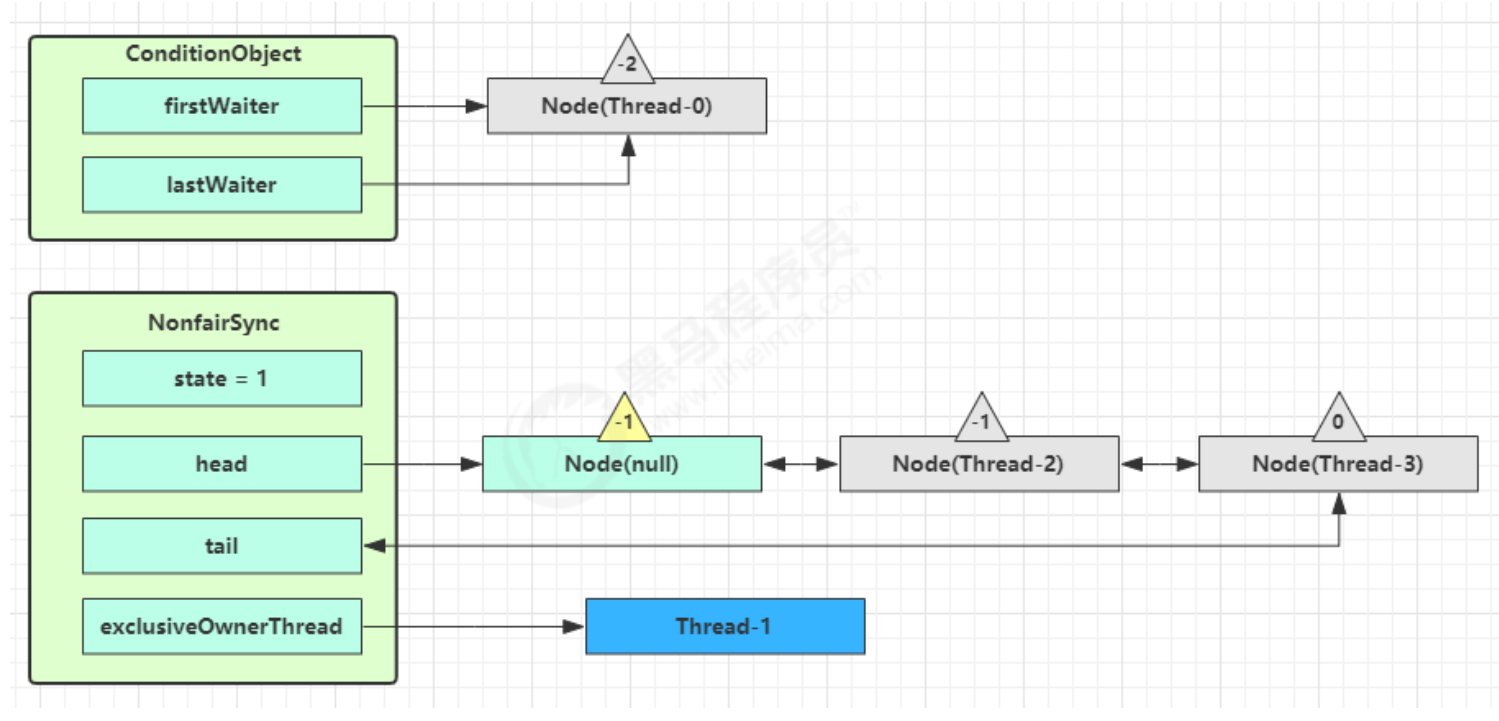
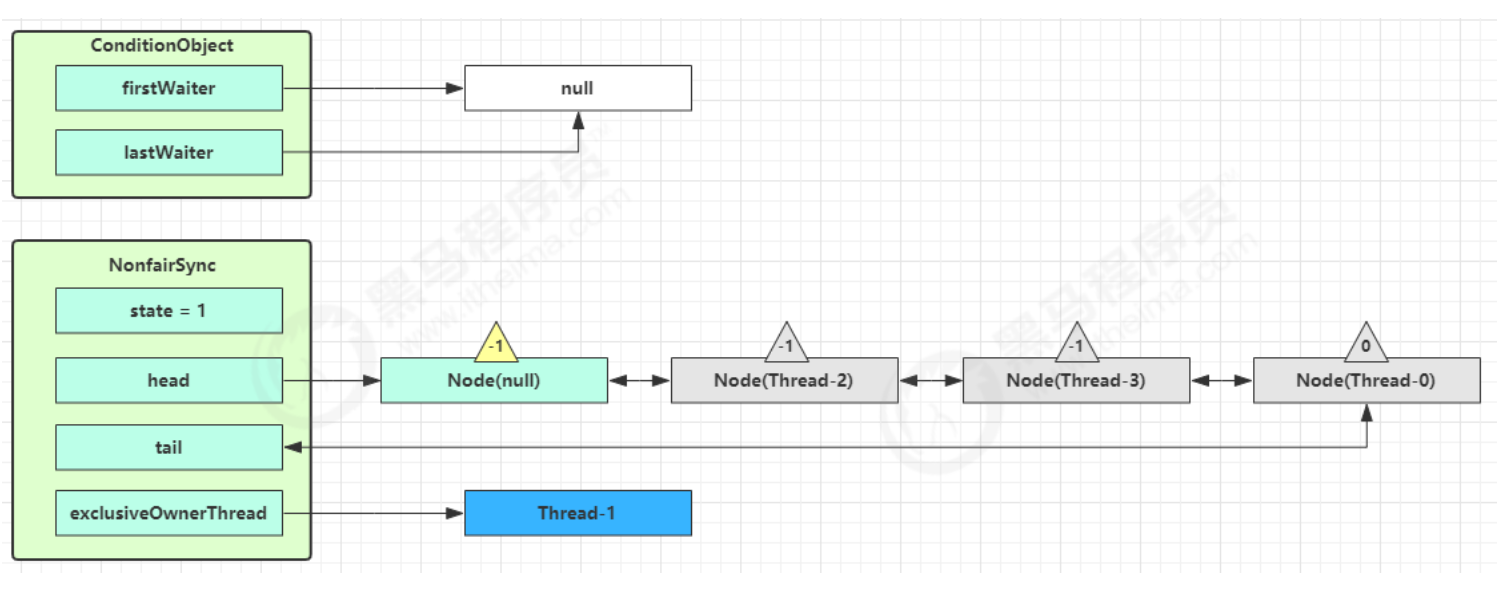
线程间的通信 保护性暂停模式通信 1.定义 即 Guarded Suspension,用在一个线程等待另一个线程的执行结果,实现线程之间相互传输结果(线程间的通信)
要点
有一个结果需要从一个线程传递到另一个线程,让他们关联同一个 GuardedObject(存储线程之间通信数据的存储空间)
如果有结果不断从一个线程到另一个线程那么可以使用消息队列(见生产者/消费者)
JDK 中,join 的实现、Future 的实现,采用的就是此模式
因为要等待另一方的结果,因此归类到同步模式
保护性暂停模式的特点:
1.线程与线程之间只能是一一对应关系 的
2.线程与线程之间的结果传输(通信)是同步的,为什么说是同步的呢?
因为生产者和消费者是一一对应关系的,生产者生产好消息后将消息设置在公共的数据存储空间中,消费者立马就可以获取
2.原理实现(无超时时间) 如果wait()没有设置超时时间,一定要调用notify/notifyAll方法手动唤醒正在等待的线程,否则等待的线程会一直阻塞下去
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class GuardedObject { private Object response; private final Object lock = new Object (); public Object get () { synchronized (lock) { while (response == null ) { try { lock.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } return response; } } public void complete (Object response) { synchronized (lock) { this .response = response; lock.notifyAll(); } } }
测试
一个线程等待另一个线程的执行结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public static void main (String[] args) { GuardedObject guardedObject = new GuardedObject (); new Thread (()->{ log.info("生产数据开始..." ); try { Thread.sleep(2000 ); } catch (InterruptedException e) { e.printStackTrace(); } String data = new String ("data" ); log.info("生产数据完成..." ); guardedObject.complete(data); },"t1" ).start(); new Thread (()->{ log.info("获取数据开始..." ); String data = (String) guardedObject.get(); log.info("获取数据完成...数据是" +data); },"t2" ).start(); }
执行结果
1 2 3 4 11:12:29.444 [t2] INFO com.czq.GuardedObject - 获取数据开始... 11:12:29.444 [t1] INFO com.czq.GuardedObject - 生产数据开始... 11:12:31.455 [t1] INFO com.czq.GuardedObject - 生产数据完成... 11:12:31.455 [t2] INFO com.czq.GuardedObject - 获取数据完成...数据是data
原理实现(有超时时间) 如果要控制超时时间呢
控制超时的核心点:
1.如何实时计算剩余的等待时间,因为每次虚假唤醒都会消耗一定的时间
2.设置了超时时间为什么就不需要主动唤醒了?主动唤醒和不主动的唤醒的区别是什么?
因为线程在到达超时时间后就会自动唤醒。
区别:
如果正常设置了唤醒,那就是线程生产完数据后能立即通知另一个线程获取数据,如果没有设置唤醒,另一个线程则等待超时时间到达后再获取数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 class GuardedObjectV2 { public Object get (long timeOut) { synchronized (lock){ long begin = System.currentTimeMillis(); long parseTime=0 ; while (response==null ){ long waitTime = timeOut-parseTime; log.debug("waitTime: {}" , waitTime); if (waitTime<0 ){ break ; } try { lock.wait(waitTime); } catch (InterruptedException e) { e.printStackTrace(); } parseTime = System.currentTimeMillis()-begin; } return response; } } public void complete (Object object) { synchronized (lock){ this .response = object; } } }
测试,没有超时
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public static void main (String[] args) { GuardedObject2 guardedObject = new GuardedObject2 (); new Thread (()->{ log.info("生产数据开始..." ); try { Thread.sleep(10 ); } catch (InterruptedException e) { e.printStackTrace(); } String data = new String ("data" ); log.info("生产数据完成..." ); guardedObject.complete(data); },"t1" ).start(); new Thread (()->{ log.info("获取数据开始..." ); String data = (String) guardedObject.get(20 ); log.info("获取数据完成...数据是" +data); },"t2" ).start(); }
输出
1 2 3 4 5 11:27:07.483 [t1] INFO com.czq.GuardedObject2 - 生产数据开始... 11:27:07.483 [t2] INFO com.czq.GuardedObject2 - 获取数据开始... 11:27:07.485 [t2] DEBUG com.czq.GuardedObject2 - waitTime: 20 11:27:07.501 [t1] INFO com.czq.GuardedObject2 - 生产数据完成... 11:27:07.517 [t2] INFO com.czq.GuardedObject2 - 获取数据完成...数据是data
测试超时
1 2 String data = (String) guardedObject.get(5 );
输出
1 2 3 4 5 6 11 :29 :29.730 [t1] INFO com.czq.GuardedObject2 - 生产数据开始...11 :29 :29.730 [t2] INFO com.czq.GuardedObject2 - 获取数据开始...11 :29 :29.732 [t2] DEBUG com.czq.GuardedObject2 - waitTime: 5 11 :29 :29.743 [t2] DEBUG com.czq.GuardedObject2 - waitTime: -6 11 :29 :29.743 [t1] INFO com.czq.GuardedObject2 - 生产数据完成...11 :29 :29.743 [t2] INFO com.czq.GuardedObject2 - 获取数据完成...数据是null
join方法的原理 是调用者轮询检查线程 alive 状态
等价于下面的代码,即join()方法的底层原理就是wait(long timeOut)
1 2 3 4 5 6 7 8 synchronized (t1) { while (t1.isAlive()) { t1.wait(0 ); } }
注意
join 体现的是【保护性暂停】模式,请参考源码解析
通过源码解析原理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public final void join () throws InterruptedException { join(0 ); } public final synchronized void join (long millis) throws InterruptedException { long base = System.currentTimeMillis(); long now = 0 ; if (millis < 0 ) { throw new IllegalArgumentException ("timeout value is negative" ); } if (millis == 0 ) { while (isAlive()) { wait(0 ); } } else { while (isAlive()) { long delay = millis - now; if (delay <= 0 ) { break ; } wait(delay); now = System.currentTimeMillis() - base; } } }
wait和join的区别 前提: wait方法和join方法都没有设置超时唤醒
1.因为join的底层就是wait,二者的原理基本一致,但有一处细微的区别,就是join方法会等待线程执行完才会自动唤醒,而wait方法只要拿到另一个线程的通信数据后就会自动唤醒,不需要等待线程执行完毕才唤醒
2.调用join()时不需要我们自己手动获取锁资源,手动调用wait/notify等方法,只要调用join()方法便有一条龙服务的功能,因为join()底层早已经帮我们封装好了(底层的实现是wait/notify..),而wait则需要我们手动获取了锁资源才能调用,所以调用起来join会比wait方便很多
引入第三方中间类降低线程之间的耦合 通俗解读场景:
如果是存在多个一一对应的生产者和消费者,生产者和消费者都是动态变化的,耦合度非常强,可以通过引入一个第三方的中间类实现生产者和消费者的解耦并管理线程之间存储的通信数据
新增 id 用来标识 Guarded Object
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 @Slf4j public class GuardedObject3 { private final Object lock = new Object (); private Object data = null ; private int id; public void setId (int id) { this .id = id; } public int getId () { return id; } public void complete (Object data) { synchronized (lock){ this .data = data; lock.notifyAll(); } } public Object get (long timeOut) { synchronized (lock){ long begin = System.currentTimeMillis(); long parseTime=0 ; while (data == null ){ long waitTime = timeOut-parseTime; log.info("waitTime....{}" ,waitTime); if (waitTime<0 ){ break ; } try { lock.wait(waitTime); } catch (InterruptedException e) { e.printStackTrace(); } parseTime = System.currentTimeMillis() - begin; } return data; } } }
中间解耦类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class MailBox { private static final Map<Integer,GuardedObject3> guardedObjects = new Hashtable <>(); private static int id=1 ; private static synchronized int generatedId () { return id++; } public static GuardedObject3 createGuardedObject3 () { GuardedObject3 guardedObject3 = new GuardedObject3 (); int id = generatedId(); guardedObject3.setId(id); guardedObjects.put(id,guardedObject3); return guardedObject3; } public static GuardedObject3 getGuardedObject3 (Integer id) { return guardedObjects.remove(id); } public static Set<Integer> getIds () { return guardedObjects.keySet(); } }
业务相关类
1 2 3 4 5 6 7 8 9 10 class People extends Thread { @Override public void run () { GuardedObject guardedObject = Mailboxes.createGuardedObject(); log.debug("开始收信 id:{}" , guardedObject.getId()); Object mail = guardedObject.get(5000 ); log.debug("收到信 id:{}, 内容:{}" , guardedObject.getId(), mail); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Postman extends Thread { private int id; private String mail; public Postman (int id, String mail) { this .id = id; this .mail = mail; } @Override public void run () { GuardedObject guardedObject = Mailboxes.getGuardedObject(id); log.debug("送信 id:{}, 内容:{}" , id, mail); guardedObject.complete(mail); } }
测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public static void main (String[] args) { for (int i = 0 ; i < 3 ; i++) { new Peoples ().start(); } try { Thread.sleep(1000 ); } catch (InterruptedException e) { e.printStackTrace(); } for (Integer id : MailBox.getIds()) { new Postmans (id,"内容" +id).start(); } }
某次运行结果
1 2 3 4 5 6 7 8 9 10 11 12 16 :20 :49.086 [Thread-1 ] DEBUG com.czq.Peoples - 开始收信 id:2 16 :20 :49.086 [Thread-0 ] DEBUG com.czq.Peoples - 开始收信 id:1 16 :20 :49.086 [Thread-2 ] DEBUG com.czq.Peoples - 开始收信 id:3 16 :20 :49.090 [Thread-1 ] INFO com.czq.GuardedObject3 - waitTime....2000 16 :20 :49.090 [Thread-2 ] INFO com.czq.GuardedObject3 - waitTime....2000 16 :20 :49.090 [Thread-0 ] INFO com.czq.GuardedObject3 - waitTime....2000 16 :20 :50.092 [Thread-3 ] DEBUG com.czq.Postmans - 送信 id:3 , 内容:内容3 16 :20 :50.092 [Thread-4 ] DEBUG com.czq.Postmans - 送信 id:2 , 内容:内容2 16 :20 :50.092 [Thread-5 ] DEBUG com.czq.Postmans - 送信 id:1 , 内容:内容1 16 :20 :50.092 [Thread-0 ] DEBUG com.czq.Peoples - 收到信 id:1 , 内容:内容1 16 :20 :50.092 [Thread-1 ] DEBUG com.czq.Peoples - 收到信 id:2 , 内容:内容2 16 :20 :50.092 [Thread-2 ] DEBUG com.czq.Peoples - 收到信 id:3 , 内容:内容3
现在最大的困惑是引入第三方解耦线程之间的耦合的作用怎么理解?感觉没有前后对比感受不到他的好处
暂时的理解:
最大的作用是**将生产者线程和消费者线程的强耦合转化成了二者与第三方类的弱耦合(解除了生产者和消费者之间的强耦合)**,因为生产者和消费者是动态变化的,如果二者耦合,耦合度会非常强,而第三方类是静态的,基本不会发生变化,那就是弱耦合
生产者消费者模式通信 1.定义 要点
与前面的保护性暂停模式中的 GuardObject 不同,不需要产生结果和消费结果的线程一一对应
消费队列可以用来平衡生产和消费的线程资源**(引入第三方中间类解耦的作用)**
生产者仅负责产生结果数据,不关心数据该如何处理,而消费者专心处理结果数据 (引入第三方中间类解耦的作用)
消息队列是有容量限制的,满时不会再加入数据,空时不会再消耗数据
JDK 中各种阻塞队列,采用的就是这种模式
保护性暂停模式和生产者消费者模式通信最大的区别是前者定义的线程只能一对一通信,后置可以实现一对多的通信
其次就是生产者消费者模式通信是异步的 ,因为生产者生产的消息需要在队列中排队等待 (一个生产者可以对应多个消费者,而队列中存储的可能是多个生产者生产的消息),消费不一定能立刻消费消息
2.实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 public class Message { private int id; private Object content; public Message (int id, String content) { this .id = id; this .content = content; } public int getId () { return id; } public Object getContent () { return content; } } package com.czq.two;import lombok.extern.slf4j.Slf4j;import java.util.LinkedList;@Slf4j public class MessageQueue { private final LinkedList<Message> queue; private int capacity; public MessageQueue (int capacity) { this .capacity = capacity; queue = new LinkedList <>(); } public void put (Message message) { synchronized (queue) { while (queue.size() == capacity){ try { log.debug("数据容器已满..." ); queue.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } queue.push(message); queue.notifyAll(); } } public Message take () { synchronized (queue) { while (queue.isEmpty()){ try { log.debug("数据容器为空..." ); queue.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } Message message = queue.poll(); queue.notifyAll(); return message; } } }
测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 @Slf4j public class Test { public static void main (String[] args) { MessageQueue messageQueue = new MessageQueue (2 ); for (int i = 0 ; i < 4 ; i++) { int id = i; new Thread (() -> { String response = "内容" +id; log.debug("try put message({})" , id); messageQueue.put(new Message (id, response)); }, "生产者" + i).start(); } try { Thread.sleep(3000 ); } catch (InterruptedException e) { e.printStackTrace(); } new Thread (() -> { while (true ) { Message message = messageQueue.take(); Object response = message.getContent(); log.debug("take message({}): [{}] lines" , message.getId(), response); } }, "消费者" ).start(); } }
某次运行结果
1 2 3 4 5 6 7 8 9 10 11 12 18:10:02.035 [生产者1] DEBUG com.czq.two.Test - try put message(1) 18:10:02.035 [生产者0] DEBUG com.czq.two.Test - try put message(0) 18:10:02.035 [生产者3] DEBUG com.czq.two.Test - try put message(3) 18:10:02.035 [生产者2] DEBUG com.czq.two.Test - try put message(2) 18:10:02.039 [生产者3] DEBUG com.czq.two.MessageQueue - 数据容器已满... 18:10:02.039 [生产者0] DEBUG com.czq.two.MessageQueue - 数据容器已满... 18:10:02.142 [生产者3] DEBUG com.czq.two.MessageQueue - 数据容器已满... 18:10:02.142 [消费者] DEBUG com.czq.two.Test - take message(2): [内容2] lines 18:10:02.142 [消费者] DEBUG com.czq.two.Test - take message(0): [内容0] lines 18:10:02.142 [消费者] DEBUG com.czq.two.Test - take message(3): [内容3] lines 18:10:02.142 [消费者] DEBUG com.czq.two.Test - take message(1): [内容1] lines 18:10:02.142 [消费者] DEBUG com.czq.two.MessageQueue - 数据容器为空...
线程间的通信总结 1.线程间的通信是什么?
这里的线程间的通信概念特指一个线程在等待另一个线程的执行结果 ,然后通过公共的存储空间实现结果的传输
2.为什么需要线程间的通信?
因为必然存在一个线程等待另一个线程的执行结果这样的业务场景 ,比如用户线程必须等待商家线程把交易金额算出来后才能付钱..
3.如何实现线程间的通信?
实现线程间通信的核心:
1.线程之间通过wait()和notify/notifyAll实现线程间的通信(通过wait方法实现线程之间的互相等待,通过notify/notifyAll放实现线程之间的互相唤醒)
2.线程之间使用一个公共的数据存储空间(GuardedObject和LinkedList等)存储线程之间的通信数据
疑问
为什么wait,notify/notifyAll是通信的核心之一?
因为wait,notify/notifyAll能够实现一个线程等待另一个线程的执行结果,待另一个线程产生执行结果后可以通过唤醒的方式通知原线程及时获取另一个线程的执行结果
Park & Unpark 基本使用 它们是 LockSupport 类中的方法
1 2 3 4 LockSupport.park(); LockSupport.unpark(暂停线程对象)
先 park 再 unpark
1 2 3 4 5 6 7 8 9 10 11 Thread t1 = new Thread (() -> { log.debug("start..." ); sleep(1 ); log.debug("park..." ); LockSupport.park(); log.debug("resume..." ); },"t1" ); t1.start(); sleep(2 ); log.debug("unpark..." ); LockSupport.unpark(t1);
输出
1 2 3 4 22:06:39.463 [t1] DEBUG com.czq.two.Test2 - start... 22:06:39.468 [t1] DEBUG com.czq.two.Test2 - park... 22:06:39.468 [main] DEBUG com.czq.two.Test2 - unpark... 22:06:39.468 [t1] DEBUG com.czq.two.Test2 - resume...
先 unpark 再 park
1 2 3 4 5 6 7 8 9 10 11 Thread t1 = new Thread (() -> { log.debug("start..." ); sleep(2 ); log.debug("park..." ); LockSupport.park(); log.debug("resume..." ); }, "t1" ); t1.start(); sleep(1 ); log.debug("unpark..." ); LockSupport.unpark(t1);
输出
1 2 3 4 22:07:08.845 [main] DEBUG com.czq.two.Test2 - unpark... 22:07:08.845 [t1] DEBUG com.czq.two.Test2 - start... 22:07:08.855 [t1] DEBUG com.czq.two.Test2 - park... 22:07:08.855 [t1] DEBUG com.czq.two.Test2 - resume...
特点 与 Object 的 wait & notify 相比
wait,notify 和 notifyAll 必须配合 Object Monitor 一起使用,而 park,unpark 不必
park & unpark 是以线程为单位来【阻塞】和【唤醒】线程,而 notify 只能随机唤醒一个等待线程,notifyAll 是唤醒所有等待线程,就不那么【精确】
park & unpark 可以先 unpark,而 wait & notify 不能先 notify
park和unpark的原理 每个线程都有自己的一个 Parker 对象(由C++编写,java中不可见),由三部分组成 _counter , _cond 和 _mutex 打个比喻
park方法原理
counter值为0的情况:
1.如果counter变量的值为0
2.则获取互斥锁让当前线程切换到阻塞状态并让当前线程进入到cond阻塞队列中等待
3.并再次设置counter值为0
counter值为1的情况:
1.如果counter变量的值为1
2.让线程继续正常执行下去并设置counter值为0
unpark方法原理
1.将counter变量的值从0置为1
2.唤醒cond阻塞队列中的线程让其继续执行
3.如果counter值本来就是1,那将会重复设置counter变量的值为1并且不需要唤醒阻塞队列中的线程
总结 1.Park &Unpark是什么?
是实现线程阻塞状态和运行状态互相转换的一种方式
2.为什么需要Park & Unpark?他的使用场景是什么?
Park & Unpark可以解决在线程成功获取到锁的资源后但缺乏其他资源而导致的线程不能得到有效运行和不能及时释放锁的问题(和wait/notify的使用场景类似)
3.怎么使用Park & Unpark?使用原理是什么?
park和unpark的原理与操作的PV操作原理非常像,park操作做信号量的减法(从1->0),如果已经是0则让线程阻塞。unpark操作做信号量的加法(从0->1),如果已经是1则不需要唤醒阻塞队列中的线程
4.park &unpark对比synchronized重量级锁和ReentrantLock重量级锁的等待唤醒机制有什么优势吗?
A.park & unpark支持唤醒指定的某个线程,这是synchronized重量级锁和ReentrantLock重量级锁实现不了的
B.park & unpark使用起来非常简单和灵活(因为他的原理是基于操作系统的PV操作),不像synchronized重量级锁实现起来非常的复杂 ,需要保证wait和notify成对出现,还要使用循环避免虚假唤醒和只有一次判断资源的情况,还需要保证加了锁必须要手动释放锁
即使是ReentrantLock重量级锁实现起来也和synchronized重量级锁类似,同样复杂 ,只是ReentrantLock重量级锁对synchronized锁做了些许优化罢了
重新理解线程状态转换
BLOCKED,WAITING,TIME_WAITING是三种不同的阻塞状态,虽然都是阻塞状态,但他们的类型不一样
假设有线程 Thread t
情况 1 NEW --> RUNNABLE
当调用 t.start() 方法时,由 NEW –> RUNNABLE
NEW状态代表只是在Java层面新建一个线程对象,但该线程对象还没有与操作系统的线程关联起来,还不是真正意义上的线程
NEW->RUNNABLE代表Java层面的线程对象成功与操作系统的线程关联起来了并且启动线程的运行
情况 2 RUNNABLE <--> WAITING/TIMED_WAITING t 线程 用 synchronized(obj) 获取了对象锁后
调用 obj.wait() 方法时,t 线程 从 RUNNABLE --> WAITING
调用 obj.notify() , obj.notifyAll() , t.interrupt() 时
阶段一:线程被notify之后不会直接参与竞争锁,因为唤醒他们的线程正在使用锁,根本就没有竞争锁的机会,所以线程被notify之后是直接从waitset等待队列进入entrylist阻塞队列,对应的状态就是从WAITING变为BLOCKED
阶段二:等待占有锁的线程释放锁后,阻塞队列entrylist中的线程就会竞争锁,如果竞争成功,线程的状态就会从WATING切换到RUNNABLE,如果失败则继续阻塞等待下一次的锁的竞争
如果obj.wait(long timeOut)带超时时间,超时之后同样是从waitset等待队列进入entrylist阻塞队列中,原理和没有超时基本是一致的,只是多个超时时间控制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public class TestWaitNotify { final static Object obj = new Object (); public static void main (String[] args) { new Thread (() -> { synchronized (obj) { log.debug("执行...." ); try { obj.wait(); } catch (InterruptedException e) { e.printStackTrace(); } log.debug("其它代码...." ); } },"t1" ).start(); new Thread (() -> { synchronized (obj) { log.debug("执行...." ); try { obj.wait(); } catch (InterruptedException e) { e.printStackTrace(); } log.debug("其它代码...." ); } },"t2" ).start(); sleep(0.5 ); log.debug("唤醒 obj 上其它线程" ); synchronized (obj) { obj.notifyAll(); } } }
情况 3 RUNNABLE <--> WAITING/TIMED_WAITING
当前线程 调用 t.join() 方法时,当前线程 从 RUNNABLE --> WAITING 注意是当前线程 在t 线程对象 的监视器上等待 如果t 线程 运行结束,或者调用了当前线程 的 interrupt() 时,当前线程从 WAITING --> RUNNABLEjoin方法底层就是wait,无论是有无超时时间,他们的状态转换原理和wait基本是一致的
细节:区分好t.wait()方法和t.join()方法阻塞的线程对象是谁,虽然二者都是阻塞当前正在运行的线程,但其实二者正在运行的线程对象是不一样的
比如t.wait()方法代表t线程就是当前正在运行的线程,而t.join()方法中t线程并不是当前正在运行的线程
情况 4 RUNNABLE <--> TIMED_WAITING
当前线程 调用 Thread.sleep(long n) ,当前线程 从 RUNNABLE --> TIMED_WAITING 当前线程 等待时间超过了 n 毫秒,当前线程 从 TIMED_WAITING --> RUNNABLE
在线程状态转换原理上和wait方法的区别:
wait(long n)会先进入到waitset等待队列中,直到锁释放才会进入到entrylist阻塞队列中竞争锁,而sleep方法是直接进入到entrylist阻塞队列中,不需要进入到waitset等待队列中
情况 5 RUNNABLE <--> TIMED_WAITING
当前线程 调用 LockSupport.parkNanos(long nanos) 或 LockSupport.parkUntil(long millis) 时,当前线程 从 RUNNABLE --> TIMED_WAITING 调用 LockSupport.unpark(目标线程) 或调用了线程 的 interrupt() ,或是等待超时,会让目标线程从 TIMED_WAITING--> RUNNABLE
情况 6 RUNNABLE <--> BLOCKED
t 线程 用 synchronized(obj) 获取了对象锁时如果竞争失败,从 RUNNABLE --> BLOCKED 持 obj 锁线程的同步代码块执行完毕,会唤醒该对象上所有 BLOCKED 的线程重新竞争,如果其中 t 线程 竞争 成功,从 BLOCKED --> RUNNABLE ,其它失败的线程仍然 BLOCKED
情况 7 RUNNABLE <--> TERMINATED
当前线程所有代码运行完毕,进入 TERMINATED
总结 线程状态的转换实际上把前面所有知识都串联起来了,这里面涉及重量级锁Monitor的原理,start(),wait(),join(),notify()/notifyAll(),park(),unpark()等方法的原理知识
1.调用线程的start()方法可以让线程从NEW->RUNNABLE
2.调用线程的sleep(),wait(),join(),park()方法让线程从RUNNABLE->WAITING/TIME_WAITING
3.调用线程的interrupt(),notify()/notifyAll(),unpark()让线程从WAITING/TIMED_WAITING->RUNNABLE
4.竞争重量级锁Mointor成功和失败则可以让线程在RUNNABE<–>BLOCKED两个状态之间切换
线程的活跃性 死锁 有这样的情况:一个线程需要同时获取多把锁,这时就容易发生死锁
核心理解:线程之间彼此都想获取对方手上的资源但又不想释放自己手上的资源,就会发生死锁现象
t1 线程 获得 A对象 锁,接下来想获取 B对象 的锁 t2 线程 获得 B对象 锁,接下来想获取 A对象 的锁 例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 Object A = new Object ();Object B = new Object ();Thread t1 = new Thread (() -> { synchronized (A) { log.debug("lock A" ); sleep(1 ); synchronized (B) { log.debug("lock B" ); log.debug("操作..." ); } } }, "t1" ); Thread t2 = new Thread (() -> { synchronized (B) { log.debug("lock B" ); sleep(0.5 ); synchronized (A) { log.debug("lock A" ); log.debug("操作..." ); } } }, "t2" ); t1.start(); t2.start();
结果
1 2 12:22:06.962 [t2] c.TestDeadLock - lock B 12:22:06.962 [t1] c.TestDeadLock - lock A
解决方式:
定位死锁 检测死锁可以使用 jconsole工具,或者使用 jps 定位进程 id,再用 jstack 定位死锁:
1 2 3 4 5 6 7 cmd > jps Picked up JAVA_TOOL_OPTIONS: -Dfile.encoding=UTF-8 12320 Jps 22816 KotlinCompileDaemon 33200 TestDeadLock // JVM 进程 11508 Main 28468 Launcher
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 cmd > jstack 33200 Picked up JAVA_TOOL_OPTIONS: -Dfile.encoding=UTF-8 2018-12-29 05:51:40 Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.91-b14 mixed mode): "DestroyJavaVM" [0x0000000000000000] java.lang.Thread.State: RUNNABLE "Thread-1" [0x000000001f54f000] java.lang.Thread.State: BLOCKED (on object monitor) at thread.TestDeadLock.lambda$main$1 (TestDeadLock.java:28) - waiting to lock <0x000000076b5bf1c0> (a java.lang.Object) - locked <0x000000076b5bf1d0> (a java.lang.Object) at thread.TestDeadLock$$Lambda$2 /883049899.run(Unknown Source) at java.lang.Thread.run(Thread.java:745) "Thread-0" [0x000000001f44f000] java.lang.Thread.State: BLOCKED (on object monitor) at thread.TestDeadLock.lambda$main$0 (TestDeadLock.java:15) - waiting to lock <0x000000076b5bf1d0> (a java.lang.Object) - locked <0x000000076b5bf1c0> (a java.lang.Object) at thread.TestDeadLock$$Lambda$1 /495053715.run(Unknown Source) at java.lang.Thread.run(Thread.java:745) // 略去部分输出 Found one Java-level deadlock: ============================= "Thread-1" : waiting to lock monitor 0x000000000361d378 (object 0x000000076b5bf1c0, a java.lang.Object), which is held by "Thread-0" "Thread-0" : waiting to lock monitor 0x000000000361e768 (object 0x000000076b5bf1d0, a java.lang.Object), which is held by "Thread-1" Java stack information for the threads listed above: =================================================== "Thread-1" : at thread.TestDeadLock.lambda$main$1 (TestDeadLock.java:28) - waiting to lock <0x000000076b5bf1c0> (a java.lang.Object) - locked <0x000000076b5bf1d0> (a java.lang.Object) at thread.TestDeadLock$$Lambda$2 /883049899.run(Unknown Source) at java.lang.Thread.run(Thread.java:745) "Thread-0" : at thread.TestDeadLock.lambda$main$0 (TestDeadLock.java:15) - waiting to lock <0x000000076b5bf1d0> (a java.lang.Object) - locked <0x000000076b5bf1c0> (a java.lang.Object) at thread.TestDeadLock$$Lambda$1 /495053715.run(Unknown Source) at java.lang.Thread.run(Thread.java:745) Found 1 deadlock.
避免死锁要注意加锁顺序
另外如果由于某个线程进入了死循环,导致其它线程一直等待,对于这种情况 linux 下可以通过 top 先定位到 CPU 占用高的 Java 进程,再利用 top -Hp 进程id 来定位是哪个线程,最后再用 jstack 排查
活锁 核心理解:线程彼此都在改变对方线程结束的运行条件(让其不能结束运行),那就会出现活锁现象
通俗点来说:两个线程都在扰乱对方的正常运行,比如一个人在给泳池加水,另一个人却一直在泳池放水,那这不就导致泳池永远都加不满水,也放不尽水,两人隔着无休止的捣乱
活锁出现在两个线程互相改变对方的结束条件,最后谁也无法结束,例如
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class TestLiveLock { static volatile int count = 10 ; static final Object lock = new Object (); public static void main (String[] args) { new Thread (() -> { while (count > 0 ) { sleep(0.2 ); count--; log.debug("count: {}" , count); } }, "t1" ).start(); new Thread (() -> { while (count < 20 ) { sleep(0.2 ); count++; log.debug("count: {}" , count); } }, "t2" ).start(); } }
解决方式:
错开线程的运行时间,使得一方不能改变另一方的结束条件。
将睡眠时间调整为随机数。
饥饿 很多教程中把饥饿定义为,一个线程由于优先级太低,始终得不到 CPU 调度执行,也不能够结束,饥饿的情况不易演示,讲读写锁时会涉及饥饿问题
下面我讲一下我遇到的一个线程饥饿的例子,先来看看使用顺序加锁的方式解决之前的死锁问题
顺序加锁的解决方案
说明:
顺序加锁可以解决死锁问题,但也会导致一些线程一直得不到锁,产生饥饿现象。
解决方式:ReentrantLock
总结 1.线程的活跃性是什么?
线程的活跃性是指线程一直处于运行状态而不能有效停止,导致线程活跃性的原因有死锁,活锁
2.为什么需要线程的活跃性?
深入理解死锁,活锁,可以预防出现此类问题而导致线程处于一直运行状态而不能得到有效的停止
3.如何使用线程的活跃性?
我们是预防死锁,活锁的出现,当然,如果你想要重现这些场景,你可以根据死锁,活锁的原理进行复现
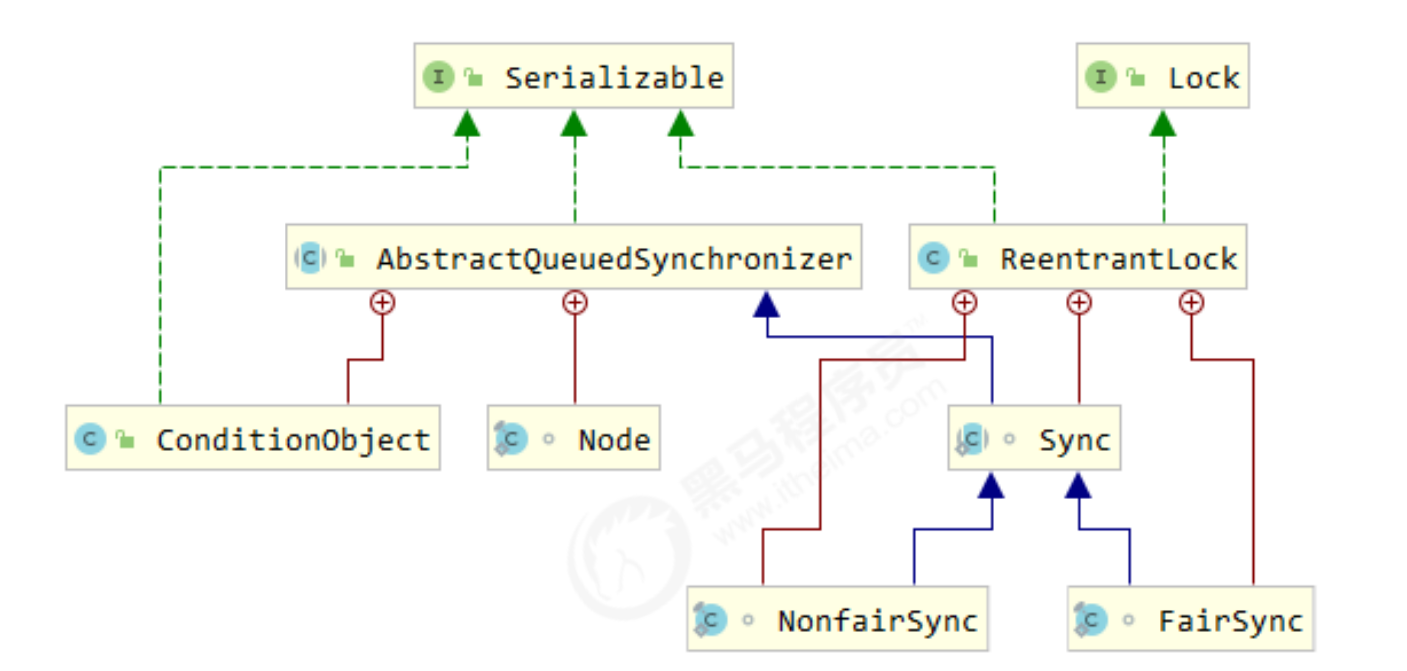
ReentrantLock 相对于 synchronized 它具备如下特点
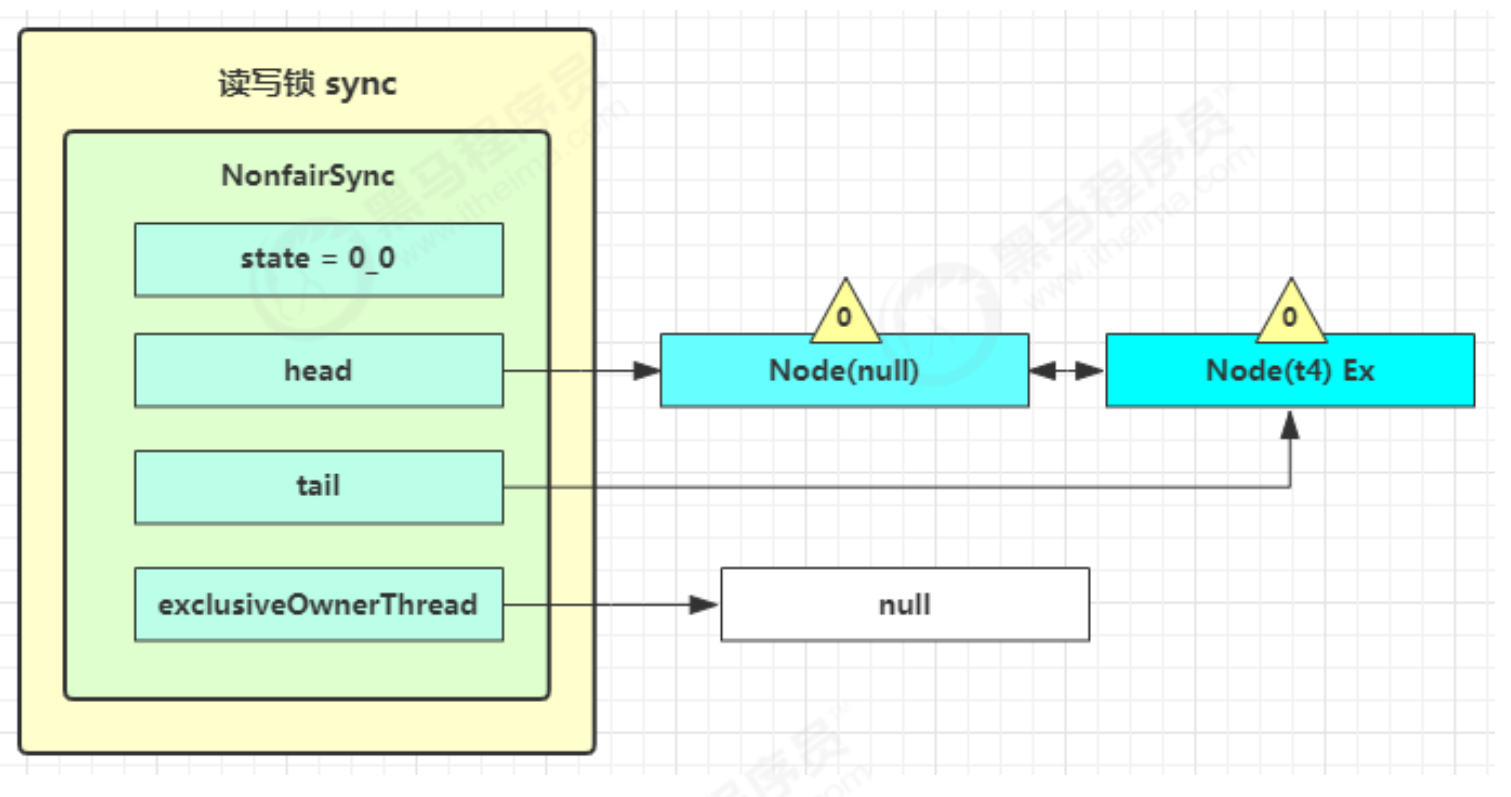
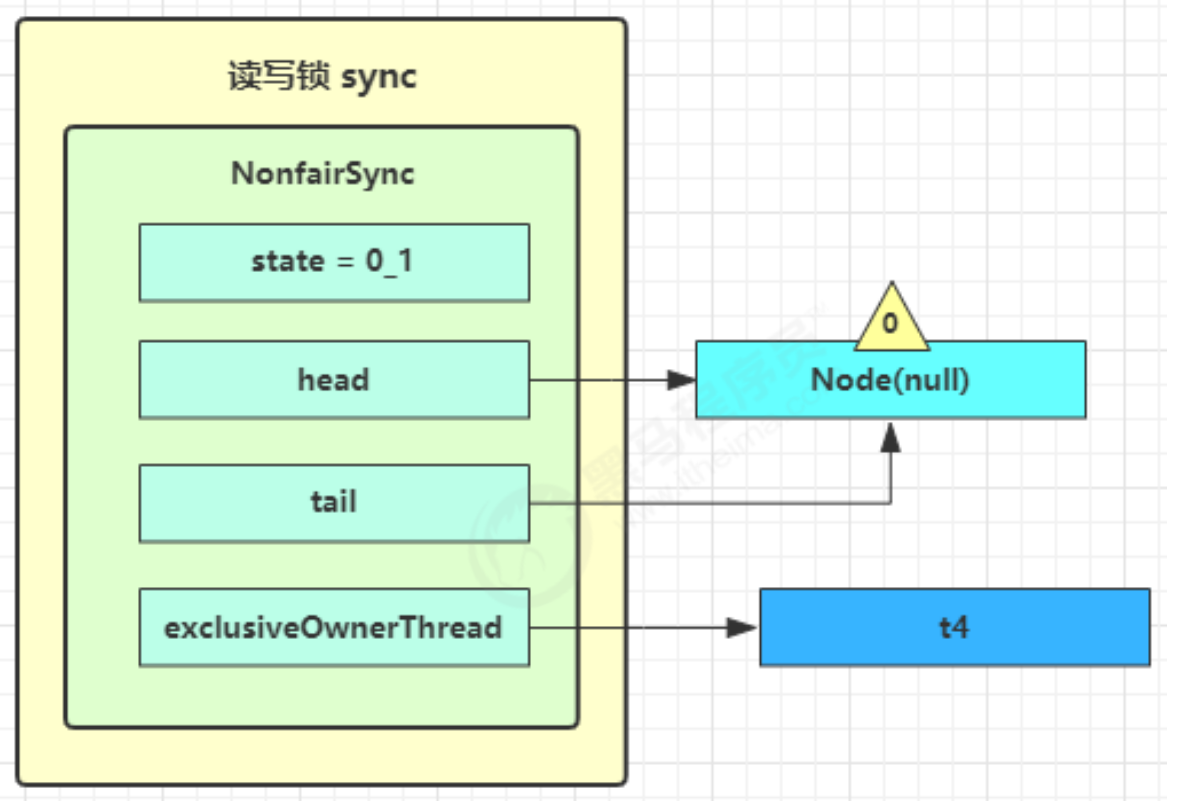
可中断 可以设置超时时间 可以设置为公平锁
支持多个条件变量
与 synchronized 一样,都支持可重入
基本语法
1 2 3 4 5 6 7 8 reentrantLock.lock(); try { } finally { reentrantLock.unlock(); }
可重入 可重入是指同一个线程如果首次获得了这把锁,那么因为它是这把锁的拥有者,因此有权利再次获取这把锁 如果是不可重入锁,那么第二次获得锁时,自己也会被锁挡住。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 static ReentrantLock lock = new ReentrantLock ();public static void main (String[] args) { method1(); } public static void method1 () { lock.lock(); try { log.debug("execute method1" ); method2(); } finally { lock.unlock(); } } public static void method2 () { lock.lock(); try { log.debug("execute method2" ); method3(); } finally { lock.unlock(); } } public static void method3 () { lock.lock(); try { log.debug("execute method3" ); } finally { lock.unlock(); } }
输出
1 2 3 17:59:11.862 [main] c.TestReentrant - execute method1 17:59:11.865 [main] c.TestReentrant - execute method2 17:59:11.865 [main] c.TestReentrant - execute method3
可打断 可打断指的是处于阻塞状态等待锁的线程可以被打断等待。注意lock.lockInterruptibly()和lock.trylock()方法是可打断的,lock.lock()不是。可打断的意义在于避免得不到锁的线程无限制地等待下去,防止死锁的一种方式
核心理解:可以打断因竞争锁失败而导致的线程阻塞状态,避免获取不到锁的线程无休止的阻塞等待下去。这恰恰是优化了synchronized因为获取锁失败而无休止的阻塞等待的缺陷
缺陷:
因为打断这种方式是由其他正在运行状态的线程对阻塞状态的线程进行打断,对于阻塞状态的线程而言是被动打断,仍然不能主动结束自己的打断状态,仍有一定的缺陷
示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 ReentrantLock lock = new ReentrantLock ();Thread t1 = new Thread (() -> { log.debug("启动..." ); try { lock.lockInterruptibly(); } catch (InterruptedException e) { e.printStackTrace(); log.debug("等锁的过程中被打断" ); return ; } try { log.debug("获得了锁" ); } finally { lock.unlock(); } }, "t1" ); lock.lock(); log.debug("获得了锁" ); t1.start(); try { sleep(1 ); t1.interrupt(); log.debug("执行打断" ); } finally { lock.unlock(); }
输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 18:02:40.520 [main] c.TestInterrupt - 获得了锁 18:02:40.524 [t1] c.TestInterrupt - 启动... 18:02:41.530 [main] c.TestInterrupt - 执行打断 java.lang.InterruptedException at java.util.concurrent.locks.AbstractQueuedSynchronizer.doAcquireInterruptibly(AbstractQueuedSynchr onizer.java:898) at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireInterruptibly(AbstractQueuedSynchron izer.java:1222) at java.util.concurrent.locks.ReentrantLock.lockInterruptibly(ReentrantLock.java:335) at cn.itcast.n4.reentrant.TestInterrupt.lambda$main$0 (TestInterrupt.java:17) at java.lang.Thread.run(Thread.java:748) 18:02:41.532 [t1] c.TestInterrupt - 等锁的过程中被打断
当然ReentrantLock也支持不可打断,调用的是lock.lock()方法api
注意如果是不可中断模式,那么即使使用了 interrupt 也不会让等待中断
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 ReentrantLock lock = new ReentrantLock ();Thread t1 = new Thread (() -> { log.debug("启动..." ); lock.lock(); try { log.debug("获得了锁" ); } finally { lock.unlock(); } }, "t1" ); lock.lock(); log.debug("获得了锁" ); t1.start(); try { sleep(1 ); t1.interrupt(); log.debug("执行打断" ); sleep(1 ); } finally { log.debug("释放了锁" ); lock.unlock(); }
输出
1 2 3 4 5 18:06:56.261 [main] c.TestInterrupt - 获得了锁 18:06:56.265 [t1] c.TestInterrupt - 启动... 18:06:57.266 [main] c.TestInterrupt - 执行打断 // 这时 t1 并没有被真正打断, 而是仍继续等待锁 18:06:58.267 [main] c.TestInterrupt - 释放了锁 18:06:58.267 [t1] c.TestInterrupt - 获得了锁
锁超时 核心理解:可以主动结束因为线程竞争锁失败而导致的阻塞状态,这是对打断(被动结束)方式的一种优化
有两种实现方式:
1.立即失败,只要线程竞争锁失败,线程不会进入阻塞状态等待锁的释放,而是会正常执行下去
2.超时失败:线程在设定时间内,多次重复竞争锁资源,在超出设定时间后,线程不会在等待,而是会正常执行下去
立刻失败
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ReentrantLock lock = new ReentrantLock ();Thread t1 = new Thread (() -> { log.debug("启动..." ); if (!lock.tryLock()) { log.debug("获取立刻失败,返回" ); return ; } try { log.debug("获得了锁" ); } finally { lock.unlock(); } }, "t1" ); lock.lock(); log.debug("获得了锁" ); t1.start(); try { sleep(2 ); } finally { lock.unlock(); }
输出
1 2 3 18:15:02.918 [main] c.TestTimeout - 获得了锁 18:15:02.921 [t1] c.TestTimeout - 启动... 18:15:02.921 [t1] c.TestTimeout - 获取立刻失败,返回
超时失败
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 ReentrantLock lock = new ReentrantLock ();Thread t1 = new Thread (() -> { log.debug("启动..." ); try { if (!lock.tryLock(1 , TimeUnit.SECONDS)) { log.debug("获取等待 1s 后失败,返回" ); return ; } } catch (InterruptedException e) { e.printStackTrace(); } try { log.debug("获得了锁" ); } finally { lock.unlock(); } }, "t1" ); lock.lock(); log.debug("获得了锁" ); t1.start(); try { sleep(2 ); } finally { lock.unlock(); }
输出
1 2 3 18:19:40.537 [main] c.TestTimeout - 获得了锁 18:19:40.544 [t1] c.TestTimeout - 启动... 18:19:41.547 [t1] c.TestTimeout - 获取等待 1s 后失败,返回
使用 tryLock 解决哲学家就餐问题
1 2 3 4 5 6 7 8 9 10 class Chopstick extends ReentrantLock { String name; public Chopstick (String name) { this .name = name; } @Override public String toString () { return "筷子{" + name + '}' ; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class Philosopher extends Thread { Chopstick left; Chopstick right; public Philosopher (String name, Chopstick left, Chopstick right) { super (name); this .left = left; this .right = right; } @Override public void run () { while (true ) { if (left.tryLock()) { try { if (right.tryLock()) { try { eat(); } finally { right.unlock(); } } } finally { left.unlock(); } } } } private void eat () { log.debug("eating..." ); Sleeper.sleep(1 ); } }
公平锁 ReentrantLock 默认是不公平的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 ReentrantLock lock = new ReentrantLock (false );lock.lock(); for (int i = 0 ; i < 500 ; i++) { new Thread (() -> { lock.lock(); try { System.out.println(Thread.currentThread().getName() + " running..." ); } finally { lock.unlock(); } }, "t" + i).start(); } Thread.sleep(1000 ); new Thread (() -> { System.out.println(Thread.currentThread().getName() + " start..." ); lock.lock(); try { System.out.println(Thread.currentThread().getName() + " running..." ); } finally { lock.unlock(); } }, "强行插入" ).start(); lock.unlock();
强行插入,有机会在中间输出
注意 :该实验不一定总能复现
1 2 3 4 5 6 7 8 9 10 11 12 t39 running... t40 running... t41 running... t42 running... t43 running... 强行插入 start... 强行插入 running... t44 running... t45 running... t46 running... t47 running... t49 running...
改为公平锁后
1 ReentrantLock lock = new ReentrantLock (true );
强行插入,总是在最后输出
1 2 3 4 5 6 7 8 9 10 t465 running... t464 running... t477 running... t442 running... t468 running... t493 running... t482 running... t485 running... t481 running... 强行插入 running...
公平锁一般没有必要,会降低并发度,后面分析原理时会讲解
条件变量 synchronized 中也有条件变量,就是我们讲原理时那个 waitSet 休息室,当条件不满足时进入 waitSet 等待
ReentrantLock 的条件变量比 synchronized 强大之处在于,它是支持多个条件变量的,这就好比
synchronized 是那些不满足条件的线程都在一间休息室(waitSet)等消息
而 ReentrantLock 支持多间休息室,有专门等烟的休息室、专门等早餐的休息室、唤醒时也是按休息室来唤 醒
核心理解:
synchronized的条件变量只有waitSet一个,导致线程调用wait()方法都是进入的同一个等待队列,唤醒线程调用notifyAll时就会导致很多虚假唤醒。而ReentrantLock支持多个条件变量,也就是在调用await()方法后支持进入多个不同的等待队列,就可以解决掉虚假唤醒的问题。
虚假唤醒问题是什么?
因为notifyAll唤醒了全部线程(因为所有线程都在一个waitSet中),但实质上很多线程所需要的资源并没有准备好但其却被唤醒了
为什么支持进入多个不同的等待队列就可以解决虚假唤醒问题呢?
如果支持多个条件变量,意味着锁可以有多个等待队列(可以理解为多个waitSet),那我们可以按照线程锁需要的资源去划分等待队列,自然就可以解决虚假唤醒问题了
细节:
解决了虚假唤醒问题并不意味着同一个waitSet队中的线程被唤醒后一定可以成功获取资源,因为虽然同一个waitSet等待队列中所需要的资源是一样的,但一个资源可以有多个线程去竞争,所以被唤醒后不一定就能成功获取到资源,这也就意味着我们需要用while不断的去获取资源而不是用if获取一次资源即可
使用要点
await 前需要获得锁
await 执行后,会释放锁,进入 conditionObject 等待
await 的线程被唤醒(或打断、或超时)取重新竞争 lock 锁
竞争 lock 锁成功后,从 await 后继续执行
核心理解:在使用方面和wait(),notify/notifyAll基本是一致的,只是其支持多个条件变量罢了
详细API 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public interface Condition { void await () throws InterruptedException; void awaitUninterruptibly () ; long awaitNanos (long nanosTimeout) throws InterruptedException; boolean await (long time, TimeUnit unit) throws InterruptedException; boolean awaitUntil (Date deadline) throws InterruptedException; void signal () ; void signalAll () ; }
例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 static ReentrantLock lock = new ReentrantLock ();static Condition waitCigaretteQueue = lock.newCondition();static Condition waitbreakfastQueue = lock.newCondition();static volatile boolean hasCigrette = false ;static volatile boolean hasBreakfast = false ;public static void main (String[] args) { new Thread (() -> { try { lock.lock(); while (!hasCigrette) { try { waitCigaretteQueue.await(); } catch (InterruptedException e) { e.printStackTrace(); } } log.debug("等到了它的烟" ); } finally { lock.unlock(); } }).start(); new Thread (() -> { try { lock.lock(); while (!hasBreakfast) { try { waitbreakfastQueue.await(); } catch (InterruptedException e) { e.printStackTrace(); } } log.debug("等到了它的早餐" ); } finally { lock.unlock(); } }).start(); sleep(1 ); sendBreakfast(); sleep(1 ); sendCigarette(); } private static void sendCigarette () { lock.lock(); try { log.debug("送烟来了" ); hasCigrette = true ; waitCigaretteQueue.signal(); } finally { lock.unlock(); } } private static void sendBreakfast () { lock.lock(); try { log.debug("送早餐来了" ); hasBreakfast = true ; waitbreakfastQueue.signal(); } finally { lock.unlock(); } }
输出
1 2 3 4 18:52:27.680 [main] c.TestCondition - 送早餐来了 18:52:27.682 [Thread-1] c.TestCondition - 等到了它的早餐 18:52:28.683 [main] c.TestCondition - 送烟来了 18:52:28.683 [Thread-0] c.TestCondition - 等到了它的烟
总结 1.ReentrantLock是什么?
ReentrantLock同样是一种重量级锁
2.为什么需要ReentrantLock锁?使用场景是什么?
ReentrantLock锁的出现就是解决重量级锁synchronized的缺点,最重要就是解决了synchronized锁不能打断因竞争锁失败而导致的线程阻塞状态,进而导致线程一直阻塞于此而不能得到有效的运行的问题。ReentrantLock锁提供了被动打断和主动打断两种优化方案
其次还解决了synchronized锁条件变量过于单一而导致的虚假唤醒问题,ReentrantLock锁是通过支持多个条件变量来实现的
3.如何使用ReentrantLock锁?
在使用方面,基本synchronized锁一致,注意ReentrantLock锁对synchronized锁的优化方法的api的使用即可
同步模式之顺序控制 概念:通过线程调度控制并发线程的执行顺序
固定运行顺序 比如,必须先 2 后 1 打印
wait notify 版
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 static final Object lock = new Object (); static boolean flag = false ; public static void main (String[] args) throws InterruptedException { Thread t1 = new Thread (()->{ LockSupport.park(); log.info("1" ); },"t1" ); t1.start(); Thread t2 = new Thread (()-> { log.info("2" ); LockSupport.unpark(t1); },"t2" ); t2.start(); }
Park Unpark 版
可以看到,实现上很麻烦:
首先,需要保证先 wait 再 notify,否则 wait 线程永远得不到唤醒。因此使用了『运行标记』来判断该不该 wait
第二,如果有些干扰线程错误地 notify 了 wait 线程,条件不满足时还要重新等待,使用了 while 循环来解决 此问题
最后,唤醒对象上的 wait 线程需要使用 notifyAll,因为『同步对象』上的等待线程可能不止一个
可以使用 LockSupport 类的 park 和 unpark 来简化上面的题目:
1 2 3 4 5 6 7 8 9 10 11 12 13 Thread t1 = new Thread (() -> { try { Thread.sleep(1000 ); } catch (InterruptedException e) { } LockSupport.park(); System.out.println("1" ); }); Thread t2 = new Thread (() -> { System.out.println("2" ); LockSupport.unpark(t1); }); t1.start(); t2.start();
park 和 unpark 方法比较灵活,他俩谁先调用,谁后调用无所谓。并且是以线程为单位进行『暂停』和『恢复』, 不需要『同步对象』和『运行标记』
交替输出 线程 1 输出 a 5 次,线程 2 输出 b 5 次,线程 3 输出 c 5 次。现在要求输出 abcabcabcabcabc 怎么实现
wait notify 版
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 static boolean t1Flag = false ; static boolean t2Flag = false ; static boolean t3Flag = false ; final static Object lock = new Object (); public static void main (String[] args) { Thread t3 = new Thread (()->{ for (int i = 0 ; i < 5 ; i++) { synchronized (lock){ while (!t3Flag){ try { lock.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } log.info("c" ); t1Flag = true ; t3Flag = false ; lock.notifyAll(); } } },"t3" ); Thread t2 = new Thread (()->{ for (int i = 0 ; i < 5 ; i++) { synchronized (lock){ while (!t2Flag){ try { lock.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } log.info("b" ); t3Flag = true ; t2Flag = false ; lock.notifyAll(); } } },"t2" ); t1Flag = true ; Thread t1 = new Thread (()->{ for (int i = 0 ; i < 5 ; i++) { synchronized (lock){ while (!t1Flag){ try { lock.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } log.info("a" ); t2Flag=true ; t1Flag=false ; lock.notifyAll(); } } },"t1" ); t1.start(); t2.start(); t3.start(); }
ReentrantLock锁的await和signalAll版
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 static boolean t1Flag = false ; static boolean t2Flag = false ; static boolean t3Flag = false ; public static void main (String[] args) throws InterruptedException { ReentrantLock lock = new ReentrantLock (); Condition t1Condition = lock.newCondition(); Condition t2Condition = lock.newCondition(); Condition t3Condition = lock.newCondition(); Thread t3 = new Thread (()->{ for (int i = 0 ; i < 5 ; i++) { lock.lock(); while (!t3Flag){ try { t3Condition.await(); } catch (InterruptedException e) { e.printStackTrace(); } } try { log.info("c" ); t1Flag = true ; t3Flag = false ; t1Condition.signalAll(); } finally { lock.unlock(); } } },"t3" ); Thread t2 = new Thread (()->{ for (int i = 0 ; i < 5 ; i++) { lock.lock(); while (!t2Flag){ try { t2Condition.await(); } catch (InterruptedException e) { e.printStackTrace(); } } try { log.info("b" ); t3Flag = true ; t2Flag = false ; t3Condition.signalAll(); } finally { lock.unlock(); } } },"t2" ); t1Flag = true ; Thread t1 = new Thread (()->{ for (int i = 0 ; i < 5 ; i++) { lock.lock(); while (!t1Flag){ try { t1Condition.await(); } catch (InterruptedException e) { e.printStackTrace(); } } try { log.info("a" ); t2Flag = true ; t1Flag = false ; t2Condition.signalAll(); } finally { lock.unlock(); } } },"t1" ); t1.start(); t2.start(); t3.start(); }
ReentrantLock锁这一版仅仅是优化了上一版仅有一个条件变量,会唤醒所有线程的小缺陷,因为他有多个条件变量,所以可以解决虚假唤醒问题
总结 1.同步模式之顺序控制是什么?
同步模式之顺序控制是指在线程并发过程中我们可以通过锁实现并发线程的串行执行并通过线程调度控制线程串行执行的执行顺序 。比如原来串行执行的顺序123,现在我通过线程调度可以变成312…
2.为什么需要同步模式之顺序控制?
因为我们不仅需要用锁解决线程并发安全问题,还需要控制并发线程的执行顺序才能达到我们想要的业务场景
3.如何实现同步模式之顺序控制?
实现的方式有很多种,常用的有wait/notify,await/signalAll,park/unpark。以下是我对控制并发线程的执行顺序的领悟
A.通过同步模式顺序控制让我更深刻领悟到仅依靠竞争锁成功与失败(synchronized和lock.lock())只能实现并发线程串行执行(串行执行就是不能让并发线程交叉执行,要一个线程执行完才能轮到另一个线程),但其并不能控制并发线程的串行执行顺序
B.比如串行的执行顺序可以是123,也可以是132,231,213,312,321…你如果不能控制并发线程的串行执行顺序那就很难达到想要的功能
C.要想实现控制串行线程的执行顺序,就需要配合锁的wait/notify,await/signalAll,park/unpark功能api实现,实质上这些api功能就是用来控制和调度线程的执行顺序的,那么他们是如何控制的呢?
D.他们可以实现即使线程成功获取到了锁资源但仍旧可以通过是否阻塞等待决定线程是否要让出锁资源,进而控制线程的执行顺序,核心就是一句话,线程竞争锁资源的顺序我们是无法控制的,但如果线程的执行顺序不满足我们的需求我们可以控制线程让出锁资源重新参与锁资源的竞争进而达到控制线程执行顺序的目的
本章小结 本章我们需要重点掌握 的是
分析多线程访问共享资源时,哪些代码片段属于临界区
使用 synchronized 互斥解决临界区的线程安全问题
掌握 synchronized 锁对象语法
掌握 synchronzied 加载成员方法和静态方法语法
掌握 wait/notify 同步方法
使用 lock 互斥解决临界区的线程安全问题
掌握 lock 的使用细节:可打断、锁超时、公平锁、条件变量
学会分析变量的线程安全性、掌握常见线程安全类的使用
线程安全类的方法是原子性的,但方法之间的组合要具体分析。
了解线程活跃性问题:死锁、活锁、饥饿。
应用方面
互斥 :使用 synchronized 或 Lock 达到共享资源互斥效果**(通过重量级锁保证线程的串行执行,保证线程执行的原子性,原子性就是一个线程执行完才能轮到下一个线程执行,也就是不能出现线程交叉执行的情况)**同步 :使用 wait/notify 或 Lock 的条件变量来达到线程间通信效果**(互斥效果只能保证线程串行执行,并不能保证线程串行执行的顺,可以使用同步来控制线程的执行顺序,还可以使用同步在线程间传递结果数据)**
原理方面
monitor、synchronized 、wait/notify 原理
synchronized 进阶原理
park & unpark 原理
模式方面
同步模式之保护性暂停(用于一对一对应关系的线程间传递结果数据)
异步模式之生产者消费者(用于多对多对应关系的线程间传递结果数据)
同步模式之顺序控制(用于控制串行执行的线程的执行顺序)
共享模型之内存 Java 内存模型 JMM 即 Java Memory Model,它定义了主存、工作内存抽象概念,底层对应着 CPU 寄存器、缓存、硬件内存、 CPU 指令优化等。
JMM的意义
计算机硬件底层的内存结构过于复杂,JMM的意义在于避免程序员直接管理计算机底层内存,用一些关键字synchronized、volatile等可以方便的管理内存。
JMM 体现在以下几个方面
原子性 - 保证指令不会受到线程上下文切换的影响**(上面的共享模型之管程已经将的很详细了)**
可见性 - 保证指令不会受 cpu 缓存的影响
有序性 - 保证指令不会受 cpu 指令并行优化**(指令重排)**的影响
可见性 概念:一个线程对主存中数据的修改对另一个线程是不可见的,原因在于另一个线程在读取数据时经过JMM编译器优化,直接从CPU高速缓存中读取了,所以读取不到主存中已经被修改的数据(不可见)
退不出的循环 先来看一个现象,main 线程对 run 变量的修改对于 t 线程不可见,导致了 t 线程无法停止:
1 2 3 4 5 6 7 8 9 10 11 static boolean run = true ;public static void main (String[] args) throws InterruptedException { Thread t = new Thread (()->{ while (run){ } }); t.start(); sleep(1 ); run = false ; }
为什么呢?分析一下:
初始状态, t 线程刚开始从主内存读取了 run 的值到工作内存。
因为 t 线程要频繁从主内存中读取 run 的值,JIT 编译器会将 run 的值缓存至自己工作内存中的高速缓存中, 减少对主存中 run 的访问,提高效率
1 秒之后,main 线程修改了 run 的值,并同步至主存,而 t 是从自己工作内存中的高速缓存中读取这个变量 的值,结果永远是旧值
解决方法 volatile(易变关键字)
它可以用来修饰成员变量和静态成员变量,他可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取 它的值,线程操作 volatile 变量都是直接操作主存
可见性 vs 原子性 核心的一句话:可见性并不能保证原子性,也就是可见性并不能阻止线程的交叉运行(更底层的说法是并不能阻止线程指令的交叉运行)
前面例子体现的实际就是可见性,它保证的是在多个线程之间,一个线程对 volatile 变量的修改对另一个线程可 见, 不能保证原子性,仅用在一个写线程,多个读线程的情况: 上例从字节码理解是这样的:
1 2 3 4 5 6 getstatic run // 线程 t 获取 run true getstatic run // 线程 t 获取 run true getstatic run // 线程 t 获取 run true getstatic run // 线程 t 获取 run true putstatic run // 线程 main 修改 run 为 false , 仅此一次 getstatic run // 线程 t 获取 run false
比较一下之前我们将线程安全时举的例子:两个线程一个 i++ 一个 i– ,只能保证看到最新值,不能解决指令交错
1 2 3 4 5 6 7 8 9 // 假设i的初始值为0 getstatic i // 线程2-获取静态变量i的值 线程内i=0 getstatic i // 线程1-获取静态变量i的值 线程内i=0 iconst_1 // 线程1-准备常量1 iadd // 线程1-自增 线程内i=1 putstatic i // 线程1-将修改后的值存入静态变量i 静态变量i=1 iconst_1 // 线程2-准备常量1 isub // 线程2-自减 线程内i=-1 putstatic i // 线程2-将修改后的值存入静态变量i 静态变量i=-1
关于synchronized重量级锁为什么能保证指令执行的可见性和有序性解析,其中有序性在特定场景下是不能保证的
A.能保证可见性是因为JMM编译器规定在加锁时(包括代码块的一切变量)只能从主存中读取数据,而不能从缓存中读取数据,解锁时必须将数据刷新到主存当中,而不是刷新到缓存中
B.能保证有序性是因为synchronized锁保证了代码块内的代码操作肯定是单线程操作,而JMM编译器对指令重排的优化就规定指令重排是不能影响结果的,但这个规定实际上是单线程下能保障不影响结果,多线程下不能保障的,而synchronized锁包裹的操作必然是单线程操作,所以可以保障有序性
C.但如果synchronized锁的同步代码块并没有完全包括操作变量数据,那代表着在没有包裹的变量数据区域内,是存在多线程操作,自然不能保障指令执行的有序性
注意
synchronized 语句块既可以保证代码块的原子性,也同时保证代码块内变量的可见性。但缺点是 synchronized 是属于重量级操作,性能相对更低 。
JMM关于synchronized的两条规定:
1)线程解锁前,必须把共享变量的最新值刷新到主内存中
2)线程加锁时,将清空工作内存中共享变量的值,从而使用共享变量时需要从主内存中重新获取最新的值
(注意:加锁与解锁需要是同一把锁)
通过以上两点,可以看到synchronized能够实现可见性。同时,由于synchronized具有同步锁,所以它也具有原子性
如果在前面示例的死循环中加入 System.out.println() 会发现即使不加 volatile 修饰符,线程 t 也能正确看到 对 run 变量的修改了,想一想为什么?(println方法中有synchronized代码块保证了可见性)
synchronized关键字不能阻止指令重排,但在一定程度上能保证有序性(如果共享变量没有逃逸出同步代码块的话)。因为在单线程的情况下指令重排不影响结果,相当于保障了有序性
模式之两阶段终止 Two Phase Termination
在一个线程 T1 中如何“优雅”终止线程 T2?这里的【优雅】指的是给 T2 一个料理后事的机会。
1.错误思路
使用线程对象的 stop() 方法停止线程
stop 方法会真正杀死线程,如果这时线程锁住了共享资源,那么当它被杀死后就再也没有机会释放锁, 其它线程将永远无法获取锁
使用 System.exit(int) 方法停止线程
目的仅是停止一个线程,但这种做法会让整个程序都停止
2.两阶段终止模式 利用 isInterrupted
interrupt 可以打断正在执行的线程,无论这个线程是在 sleep,wait,还是正常运行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class TPTInterrupt { private Thread thread; public void start () { thread = new Thread (() -> { while (true ) { Thread current = Thread.currentThread(); if (current.isInterrupted()) { log.debug("料理后事" ); break ; } try { Thread.sleep(1000 ); log.debug("将结果保存" ); } catch (InterruptedException e) { current.interrupt(); } } },"监控线程" ); thread.start(); } public void stop () { thread.interrupt(); } }
调用
1 2 3 4 5 TPTInterrupt t = new TPTInterrupt ();t.start(); Thread.sleep(3500 ); log.debug("stop" ); t.stop();
结果
1 2 3 4 5 11:49:42.915 c.TwoPhaseTermination [监控线程] - 将结果保存 11:49:43.919 c.TwoPhaseTermination [监控线程] - 将结果保存 11:49:44.919 c.TwoPhaseTermination [监控线程] - 将结果保存 11:49:45.413 c.TestTwoPhaseTermination [main] - stop 11:49:45.413 c.TwoPhaseTermination [监控线程] - 料理后事
利用volatile修饰的停止标记 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 private static volatile boolean stop; public static void main (String[] args) throws InterruptedException { new Thread (()->{ while (true ){ if (stop){ log.info("打断标记来咯!结束运行线程" ); break ; } } }).start(); Thread.sleep(100 ); stop = true ; }
结果
1 18:54:09.543 [Thread-0] INFO com.czq.three.Test - 打断标记来咯!结束运行线程
两阶段终止模式是用来优化的停止一个线程的运行的,现在来对比两种实现方式,interrupt()打断方式和volatile关键字可见性性方式
对比之前需要明确的一点是优雅的停止线程运行的核心都是设置一个停止运行的标志位,并且volatile关键字的作用只是用来保障停止运行的标志位数据对所有线程可见,他本身并不是停止运行的标志位
对比
interrupt()打断方式较为麻烦,因为他存在重置打断标志位的问题,需要重复设置打断标记位,而volatile的方式通过保证停止标记位可见性的方式可以读取最新的停止标志位的数据从而停止线程的运行,较为方便,只需要给变量加一个volatile关键字即可
模式之 Balking 1.定义 Balking (犹豫)模式用在一个线程发现另一个线程或本线程已经做了某一件相同的事,那么本线程就无需再做 了,直接结束返回
通俗点来理解Balk模式的作用:就是用来解决多线程下的判断问题,如果为true则直接返回,false则继续执行
典型的应用案例是单例模式,判断单例对象是否已经创建好了,如果已经创建好则不需要继续执行下去,直接返回即可,否则需要继续执行下去,创建单例对象
volatile关键字的作用
保证了在多线程交叉运行的情况下能读取最新的数据,线程可以根据读取的数据可以判断是否要继续执行下去,但仍需要配合synchronized重量级锁解决原子性问题才能实现balking犹豫模式
2.实现 例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 private static Thread thread; private static volatile boolean bulk = false ; public static void main (String[] args) { starting(); starting(); } public static void starting () { synchronized (Test2.class){ if (bulk){ return ; } bulk = true ; } thread = new Thread (()->{ log.info("监控线程执行拉!" ); }); thread.start(); }
当前端页面多次点击按钮调用 start 时
输出
1 19 :05 :03.141 [Thread-0 ] INFO com.czq.three.Test2 - 监控线程执行拉!
对比一下保护性暂停模式:保护性暂停模式用在一个线程等待另一个线程的执行结果,当条件不满足时线程等待
其实两个模式都是用于线程通信的,保护性暂停模式是用于在线程间传输结果数据,而balkin模式是用来在线程间传递是否要重复执行的信号,如果一个线程已经执行过了通过标记变量即可给另一个线程传递执行信号,只是通信解决的问题不一样
有序性 **JVM 会在不影响正确性的前提下,可以调整语句的执行顺序(指令重排)**,思考下面一段代码
1 2 3 4 5 static int i;static int j;i = ...; j = ...;
可以看到,至于是先执行 i 还是 先执行 j ,对最终的结果不会产生影响。所以,上面代码真正执行时,既可以是
也可以是
这种特性称之为『指令重排』,多线程下『指令重排』会影响正确性。为什么要有重排指令这项优化呢? 从 CPU 执行指令的原理来理解一下吧
指令级并行执行的原理 名词 Clock Cycle Time
主频的概念大家接触的比较多,而 CPU 的 Clock Cycle Time(时钟周期时间),等于主频的倒数,意思是 CPU 能 够识别的最小时间单位,比如说 4G 主频的 CPU 的 Clock Cycle Time 就是 0.25 ns,作为对比,我们墙上挂钟的 Cycle Time 是 1s
例如,运行一条加法指令一般需要一个时钟周期时间
CPI
有的指令需要更多的时钟周期时间,所以引出了 CPI (Cycles Per Instruction)指令平均时钟周期数
IPC
IPC(Instruction Per Clock Cycle) 即 CPI 的倒数,表示每个时钟周期能够运行的指令数
CPU 执行时间
程序的 CPU 执行时间,即我们前面提到的 user + system 时间,可以用下面的公式来表示
1 程序 CPU 执行时间 = 指令数 * CPI * Clock Cycle Time
指令重排序优化 事实上,现代处理器会设计为一个时钟周期完成一条执行时间最长的 CPU 指令。为什么这么做呢?可以想到指令 还可以再划分成一个个更小的阶段 ,例如,每条指令都可以分为: 取指令 - 指令译码 - 执行指令 - 内存访问 - 数据写回 这 5 个阶段
术语参考 :
instruction fetch (IF)
instruction decode (ID)
execute (EX)
memory access (MEM)
register write back (WB)
在不改变程序结果的前提下,这些指令的各个阶段可以通过重排序 和组合 来实现指令级并行 ,这一技术在 80’s 中 叶到 90’s 中叶占据了计算架构的重要地位
提示 :
分阶段,分工是提升效率的关键!
指令重排的前提是,重排指令不能影响结果 ,例如
1 2 3 4 5 6 7 int a = 10 ; int b = 20 ; System.out.println( a + b ); int a = 10 ; int b = a - 5 ;
参考 :
Scoreboarding and the Tomasulo algorithm (which is similar to scoreboarding but makes use of register renaming )are two of the most common techniques for implementing out-of-order execution and instruction-level parallelism.
支持流水线的处理器 现代 CPU 支持多级指令流水线 ,例如支持同时执行 取指令 - 指令译码 - 执行指令 - 内存访问 - 数据写回 的处理 器,就可以称之为五级指令流水线 。这时 CPU 可以在一个时钟周期内,同时运行五条指令的不同阶段(相当于一 条执行时间最长的复杂指令),IPC = 1,本质上,流水线技术并不能缩短单条指令的执行时间,但它变相地提高了 指令地吞吐率
提示 :
奔腾四(Pentium 4)支持高达 35 级流水线,但由于功耗太高被废弃
小总结
所以为什么会出现指令重排序呢?
1.因为通过指令重排序和组合可以实现指令并行(严格来说是并发)执行,大大提高单位时间内指令的执行效率和指令的吞吐量(指令并行技术的核心就是指令流水线技术)
2.将指令的执行细分成更小的执行阶段,让自可以在多个不同的指令执行阶段中切换执行,大大提高单位时间内的指令执行效率和吞吐量**(必须先切分更细小的阶段,才能让cpu更灵活的在不同的指令执行阶段中切换,从而大大提高cpu的利用率)**
通俗点来理解:
比如一个人要做煮饭,烧水,煮菜三件事,如果不将每一件事情切分成更小的执行单位,那么就意味着我们必须先要煮完饭才能烧水,烧完水才能煮菜,但实际上煮饭只要前期下好米,后面都是等待时间 ,烧水同样是加好水打完火就是等待时间了,煮菜也类似,那么人在这些等待时间中实际上是空闲的,不就浪费了人这个资源吗?
如果我们将煮饭,烧水,煮菜切分更细小的执行单位,意味着我们可以在下好米后,等待饭煮好的时间取烧水,在等待烧好水的时间段取煮菜,这不就把人的等待时间(空闲时间)利用好了,大大提高了人这个资源的利用率,提高了单位时间内工作的吞吐量(单位时间内可以完成更多的工作)
所以指令流水线技术其实也就是将生活中的思想应用到程序上罢了(并发技术也是这个原理,所以为什么要把进程切分更细小的线程工作单位,这也是重要的原因之一,因为其可以大大提高计算机共享资源的利用率,不仅仅是cpu资源,还有内存,缓存…)
诡异的结果 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 int num = 0 ;boolean ready = false ;public void actor1 (I_Result r) { if (ready) { r.r1 = num + num; } else { r.r1 = 1 ; } } public void actor2 (I_Result r) { num = 2 ; ready = true ; ready = true ; num = 2 ; }
I_Result 是一个对象,有一个属性 r1 用来保存结果,问,可能的结果有几种?
有同学这么分析
情况1:线程1 先执行,这时 ready = false,所以进入 else 分支结果为 1
情况2:线程2 先执行 num = 2,但没来得及执行 ready = true,线程1 执行,还是进入 else 分支,结果为1
情况3:线程2 执行到 ready = true,线程1 执行,这回进入 if 分支,结果为 4(因为 num 已经执行过了)
但我告诉你,结果还有可能是 0 😁😁😁,信不信吧!
这种情况下是:线程2 执行 ready = true,切换到线程1,进入 if 分支,相加为 0,再切回线程2 执行 num = 2
相信很多人已经晕了 😵😵😵
这种现象叫做指令重排,是 JIT 编译器在运行时的一些优化,这个现象需要通过大量测试才能复现:
借助 java 并发压测工具 jcstress https://wiki.openjdk.java.net/display/CodeTools/jcstress
1 2 3 mvn archetype:generate -DinteractiveMode=false -DarchetypeGroupId=org.openjdk.jcstress - DarchetypeArtifactId=jcstress-java-test-archetype -DarchetypeVersion=0.5 -DgroupId=cn.itcast - DartifactId=ordering -Dversion=1.0
创建 maven 项目,提供如下测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @JCStressTest @Outcome(id = {"1", "4"}, expect = Expect.ACCEPTABLE, desc = "ok") @Outcome(id = "0", expect = Expect.ACCEPTABLE_INTERESTING, desc = "!!!!") @State public class ConcurrencyTest { int num = 0 ; boolean ready = false ; @Actor public void actor1 (I_Result r) { if (ready) { r.r1 = num + num; } else { r.r1 = 1 ; } } @Actor public void actor2 (I_Result r) { num = 2 ; ready = true ; } }
执行
1 2 mvn clean install java -jar target/jcstress.jar
会输出我们感兴趣的结果,摘录其中一次结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 *** INTERESTING tests Some interesting behaviors observed. This is for the plain curiosity. 2 matching test results. [OK] test.ConcurrencyTest (JVM args: [-XX:-TieredCompilation]) Observed state Occurrences Expectation Interpretation 0 1,729 ACCEPTABLE_INTERESTING !!!! 1 42,617,915 ACCEPTABLE ok 4 5,146,627 ACCEPTABLE ok [OK] test.ConcurrencyTest (JVM args: []) Observed state Occurrences Expectation Interpretation 0 1,652 ACCEPTABLE_INTERESTING !!!! 1 46,460,657 ACCEPTABLE ok 4 4,571,072 ACCEPTABLE ok
可以看到,出现结果为 0 的情况有 638 次,虽然次数相对很少,但毕竟是出现了。
解决方法 volatile 修饰的变量,可以禁用指令重排
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @JCStressTest @Outcome(id = {"1", "4"}, expect = Expect.ACCEPTABLE, desc = "ok") @Outcome(id = "0", expect = Expect.ACCEPTABLE_INTERESTING, desc = "!!!!") @State public class ConcurrencyTest { int num = 0 ; volatile boolean ready = false ; @Actor public void actor1 (I_Result r) { if (ready) { r.r1 = num + num; } else { r.r1 = 1 ; } } @Actor public void actor2 (I_Result r) { num = 2 ; ready = true ; } }
结果为:
1 2 3 *** INTERESTING tests Some interesting behaviors observed. This is for the plain curiosity. 0 matching test results.
volatile的原理 volatile 的底层实现原理是内存屏障 ,Memory Barrier(Memory Fence)
对 volatile 变量的写指令后会加入写屏障 对 volatile 变量的读指令前会加入读屏障
如何保证可见性
写屏障(sfence)保证在该屏障之前的,对共享变量的改动,都同步到主存当中
public void actor2(I_Result r) {
num = 2;
ready = true; // ready 是 volatile 赋值带写屏障
// 写屏障
}
1 2 3 4 5 6 7 8 9 10 11 12 13 - 而读屏障(lfence)保证在该屏障之后,对共享变量的读取,加载的是主存中最新数据 - ```java public void actor1(I_Result r) { // 读屏障 // ready 是 volatile 读取值带读屏障 if(ready) { r.r1 = num + num; } else { r.r1 = 1; } }
能保证可见性的核心在于无论读写操作都是操作主存而非缓存
如何保证有序性
写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后
public void actor2(I_Result r) {
num = 2;
ready = true; // ready 是 volatile 赋值带写屏障
// 写屏障
}
1 2 3 4 5 6 7 8 9 10 11 12 13 - 读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前 - ```java public void actor1(I_Result r) { // 读屏障 // ready 是 volatile 读取值带读屏障 if(ready) { r.r1 = num + num; } else { r.r1 = 1; } }
还是那句话,不能解决指令交错:
写屏障仅仅是保证之后的读能够读到最新的结果,但不能保证读跑到它前面去
而有序性的保证也只是保证了本线程内相关代码不被重排序
从图示案例可以清晰看出,volatile关键字并不能阻止指令的交叉运行,也就是并不能保证线程指令执行的原子性
典型的没有保障指令执行的有序性的案例
双检锁实现单例设计模式
double-checked locking的 问题 以著名的 double-checked locking 单例模式为例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Singleton { private static volatile Singleton instance; private Singleton () { } public static Singleton getInstance () { if (instance == null ){ synchronized (Singleton.class){ if (instance== null ){ instance= new Singleton (); } } } return instance; } }
以上的实现特点是:
懒惰实例化
首次使用 getInstance() 才使用 synchronized 加锁,后续使用时无需加锁
有隐含的,但很关键的一点:第一个 if 使用了 INSTANCE 变量,是在同步块之外
但在多线程环境下,上面的代码是有问题的,getInstance 方法对应的字节码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 0: getstatic 3: ifnonnull 37 6: ldc 8: dup 9: astore_0 10: monitorenter 11: getstatic 14: ifnonnull 27 17: new 20: dup 21: invokespecial 24: putstatic 27: aload_0 28: monitorexit 29: goto 37 32: astore_1 33: aload_0 34: monitorexit 35: aload_1 36: athrow 37: getstatic 40: areturn
其中
17 表示创建对象,将对象引用入栈 // new Singleton
20 表示复制一份对象引用 // 引用地址
21 表示利用一个对象引用,调用构造方法
24 表示利用一个对象引用,赋值给 static INSTANCE
也许 jvm 会优化为:先执行 24,再执行 21。如果两个线程 t1,t2 按如下时间序列执行:
关键在于 0: getstatic 这行代码在 monitor 控制之外,它就像之前举例中不守规则的人,可以越过 monitor 读取 INSTANCE 变量的值
这时 t1 还未完全将构造方法执行完毕,如果在构造方法中要执行很多初始化操作,那么 t2 拿到的是将是一个未初 始化完毕的单例
对 INSTANCE 使用 volatile 修饰即可,可以禁用指令重排,但要注意在 JDK 5 以上的版本的 volatile 才会真正有效
问题解析通俗版:
instance= new Singleton();包含两个操作,一是调用对象构造方法初始化对象,第二个是将对象的引用地址赋值给变量;如果指令重排将这两个操作的执行交换了,那么在多线程环境,其他线程拿到的对象引用有可能就是一个假的引用,因为此时对象并没有执行完构造函数,调用该对象的相关功能就必然出现异常
double-checked locking 解决 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public final class Singleton { private Singleton () { } private static volatile Singleton INSTANCE = null ; public static Singleton getInstance () { if (INSTANCE == null ) { synchronized (Singleton.class) { if (INSTANCE == null ) { INSTANCE = new Singleton (); } } } return INSTANCE; } }
字节码上看不出来 volatile 指令的效果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 // -------------------------------------> 加入对 INSTANCE 变量的读屏障 0: getstatic 3: ifnonnull 37 6: ldc 8: dup 9: astore_0 10: monitorenter -----------------------> 保证原子性、可见性 11: getstatic 14: ifnonnull 27 17: new 20: dup 21: invokespecial 24: putstatic // -------------------------------------> 加入对 INSTANCE 变量的写屏障 27: aload_0 28: monitorexit ------------------------> 保证原子性、可见性 29: goto 37 32: astore_1 33: aload_0 34: monitorexit 35: aload_1 36: athrow 37: getstatic 40: areturn
如上面的注释内容所示,读写 volatile 变量时会加入内存屏障(Memory Barrier(Memory Fence)),保证下面 两点:
可见性
写屏障(sfence)保证在该屏障之前的 t1 对共享变量的改动,都同步到主存当中
而读屏障(lfence)保证在该屏障之后 t2 对共享变量的读取,加载的是主存中最新数据
有序性
写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后
读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前
更底层是读写变量时使用 lock 指令来多核 CPU 之间的可见性与有序性
从图中可以清晰的看出,加了volatile关键字保证了有序性之后,对象的赋值操作必然是在对象执行构造函数之后才会赋值,也就是不会出现二者的指令重排序现在,进而实现了指令的有序性
happens-before happens-before 规定了对共享变量的写操作对其它线程的读操作可见,它是可见性与有序性的一套规则总结 ,抛 开以下 happens-before 规则,JMM 并不能保证一个线程对共享变量的写,对于其它线程对该共享变量的读可见
等于是总结了对操作共享变量支持可见性和有序性的规律总结,也可以说是攻略
对于这七种规律要以理解为主,不要死记硬背,理解后无论是出现什么情况,都可以自己分析明白
线程解锁 m 之前对变量的写,对于接下来对 m 加锁的其它线程对该变量的读可见(synchronized关键字的可见性、监视器规则)
1 2 3 4 5 6 7 8 9 10 11 12 static int x;static Object m = new Object ();new Thread (()->{ synchronized (m) { x = 10 ; } },"t1" ).start(); new Thread (()->{ synchronized (m) { System.out.println(x); } },"t2" ).start();
线程对 volatile 变量的写,对接下来其它线程对该变量的读可见(volatile关键字的可见性、volatile规则)
1 2 3 4 5 6 7 volatile static int x;new Thread (()->{ x = 10 ; },"t1" ).start(); new Thread (()->{ System.out.println(x); },"t2" ).start();
线程 start 前对变量的写,对该线程开始后对该变量的读可见(程序顺序规则+线程启动规则)
1 2 3 4 5 static int x;x = 10 ; new Thread (()->{ System.out.println(x); },"t2" ).start();
线程结束前对变量的写,对其它线程得知它结束后的读可见(比如其它线程调用 t1.isAlive() 或 t1.join()等待 它结束)(线程终止规则)
1 2 3 4 5 6 7 static int x;Thread t1 = new Thread (()->{ x = 10 ; },"t1" ); t1.start(); t1.join(); System.out.println(x);
线程 t1 打断 t2(interrupt)前对变量的写,对于其他线程得知 t2 被打断后对变量的读可见(通过 t2.interrupted 或 t2.isInterrupted)(线程中断机制)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 static int x;public static void main (String[] args) { Thread t2 = new Thread (()->{ while (true ) { if (Thread.currentThread().isInterrupted()) { System.out.println(x); break ; } } },"t2" ); t2.start(); new Thread (()->{ sleep(1 ); x = 10 ; t2.interrupt(); },"t1" ).start(); while (!t2.isInterrupted()) { Thread.yield (); } System.out.println(x); }
对变量默认值(0,false,null)的写,对其它线程对该变量的读可见
具有传递性,如果 x hb-> y 并且 y hb-> z 那么有 x hb-> z ,配合 volatile 的防指令重排,有下面的例子
1 2 3 4 5 6 7 8 9 10 volatile static int x;static int y;new Thread (()->{ y = 10 ; x = 20 ; },"t1" ).start(); new Thread (()->{ System.out.println(x); },"t2" ).start();
变量都是指成员变量或静态成员变量
参考: 第17页
在JMM中有一个很重要的概念对于我们了解JMM有很大的帮助,那就是happens-before规则。happens-before规则非常重要,它是判断数据是否存在竞争、线程是否安全的主要依据。JSR-133S使用happens-before概念阐述了两个操作之间的内存可见性。在JMM中,如果一个操作的结果需要对另一个操作可见,那么这两个操作则存在happens-before关系。
那什么是happens-before呢?在JSR-133中,happens-before关系定义如下:
如果一个操作happens-before另一个操作,那么意味着第一个操作的结果对第二个操作可见,而且第一个操作的执行顺序将排在第二个操作的前面。
两个操作之间存在happens-before关系,并不意味着Java平台的具体实现必须按照happens-before关系指定的顺序来执行。如果重排序之后的结果,与按照happens-before关系来执行的结果一致,那么这种重排序并不非法(也就是说,JMM允许这种重排序)
happens-before规则如下:
程序顺序规则:一个线程中的每一个操作,happens-before于该线程中的任意后续操作。
监视器规则:对一个锁的解锁,happens-before于随后对这个锁的加锁。
volatile规则:对一个volatile变量的写,happens-before于任意后续对一个volatile变量的读。
传递性:若果A happens-before B,B happens-before C,那么A happens-before C。
线程启动规则:Thread对象的start()方法,happens-before于这个线程的任意后续操作。
线程终止规则:线程中的任意操作,happens-before于该线程的终止监测。我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值等手段检测到线程已经终止执行。
线程中断操作:对线程interrupt()方法的调用,happens-before于被中断线程的代码检测到中断事件的发生,可以通过Thread.interrupted()方法检测到线程是否有中断发生。
对象终结规则:一个对象的初始化完成,happens-before于这个对象的finalize()方法的开始。
参考链接:happens-before规则解析 - 知乎 (zhihu.com)
习题 balking 模式习题 希望 doInit() 方法仅被调用一次,下面的实现是否有问题,为什么?
1 2 3 4 5 6 7 8 9 10 11 12 public class TestVolatile { volatile boolean initialized = false ; void init () { if (initialized) { return ; } doInit(); initialized = true ; } private void doInit () { } }
线程安全单例习题 单例模式有很多实现方法,饿汉、懒汉、静态内部类、枚举类,试分析每种实现下获取单例对象(即调用 getInstance)时的线程安全,并思考注释中的问题
饿汉式:类加载就会导致该单实例对象被创建
懒汉式:类加载不会导致该单实例对象被创建,而是首次使用该对象时才会创建
实现1(饿汉式):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public final class Singleton implements Serializable { private Singleton () {} private static final Singleton INSTANCE = new Singleton (); public static Singleton getInstance () { return INSTANCE; } public Object readResolve () { return INSTANCE; } }
实现2(枚举类):
1 2 3 4 5 6 7 8 9 enum Singleton { INSTANCE; }
实现3(synchronized方法):
1 2 3 4 5 6 7 8 9 10 11 12 public final class Singleton { private Singleton () { } private static Singleton INSTANCE = null ; public static synchronized Singleton getInstance () { if ( INSTANCE != null ){ return INSTANCE; } INSTANCE = new Singleton (); return INSTANCE; } }
实现4:DCL+volatile
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public final class Singleton { private Singleton () { } private static volatile Singleton INSTANCE = null ; public static Singleton getInstance () { if (INSTANCE != null ) { return INSTANCE; } synchronized (Singleton.class) { if (INSTANCE != null ) { return INSTANCE; } INSTANCE = new Singleton (); return INSTANCE; } } }
实现5(内部类初始化):
1 2 3 4 5 6 7 8 9 10 11 public final class Singleton { private Singleton () { } private static class LazyHolder { static final Singleton INSTANCE = new Singleton (); } public static Singleton getInstance () { return LazyHolder.INSTANCE; } }
本章小结 本章重点讲解了 JMM 中的
可见性 - 由 JVM 缓存优化引起
有序性 - 由 JVM 指令重排序优化引起
happens-before 规则
原理方面
模式方面
两阶段终止模式的 volatile 改进
同步模式之 balking
共享模型之无锁 问题提出 (应用之互斥) 有如下需求,保证 account.withdraw 取款方法的线程安全
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 package cn.itcast;import java.util.ArrayList;import java.util.List;interface Account { Integer getBalance () ; void withdraw (Integer amount) ; static void demo (Account account) { List<Thread> ts = new ArrayList <>(); long start = System.nanoTime(); for (int i = 0 ; i < 1000 ; i++) { ts.add(new Thread (() -> { account.withdraw(10 ); })); } ts.forEach(Thread::start); ts.forEach(t -> { try { t.join(); } catch (InterruptedException e) { e.printStackTrace(); } }); long end = System.nanoTime(); System.out.println(account.getBalance() + " cost: " + (end-start)/1000_000 + " ms" ); } }
原有实现并不是线程安全的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class AccountUnsafe implements Account { private Integer balance; public AccountUnsafe (Integer balance) { this .balance = balance; } @Override public Integer getBalance () { return balance; } @Override public void withdraw (Integer amount) { balance -= amount; } }
执行测试代码
1 2 3 public static void main (String[] args) { Account.demo(new AccountUnsafe (10000 )); }
某次的执行结果
为什么不安全 withdraw 方法
1 2 3 public void withdraw (Integer amount) { balance -= amount; }
原因:Integer虽然是不可变类,其方法是线程安全的,但是以上操作涉及到了多个方法的组合,是不能阻止线程交叉运行的,所以是线程不安全的
解决思路-锁 (悲观互斥)首先想到的是给 Account 对象加锁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class AccountUnsafe implements Account { private Integer balance; public AccountUnsafe (Integer balance) { this .balance = balance; } @Override public synchronized Integer getBalance () { return balance; } @Override public synchronized void withdraw (Integer amount) { balance -= amount; } }
结果为
解决思路-无锁 (乐观重试)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class AccountSafe implements Account { private AtomicInteger balance; public AccountSafe (Integer balance) { this .balance = new AtomicInteger (balance); } @Override public Integer getBalance () { return balance.get(); } @Override public void withdraw (Integer amount) { while (true ) { int prev = balance.get(); int next = prev - amount; if (balance.compareAndSet(prev, next)) { break ; } } } }
执行测试代码
1 2 3 public static void main (String[] args) { Account.demo(new AccountSafe (10000 )); }
某次的执行结果
CAS 与 volatile 前面看到的 AtomicInteger 的解决方法,内部并没有用锁来保护共享变量的线程安全,那么它是如何实现的呢?
无锁实现共享变量的线程安全性的核心是CAS操作,而CAS操作的核心思想是比较并交换和不断重试机制,具体过程如下
1.通过比较确认本线程操作的数据是否是原来的数据,如果不是原来的数据意味着该数据已经被其他线程修改过,意味着存在线程交叉运行的情况,即有可能会出现线程安全问题,所以此次操作只能以失败告终,只能不断的重试,直到比较的结果是原来的数据,才不会出现线程安全问题
2.需要注意的是即使比较的结果是原来的数据也并不意味着该数据没有被其他线程修改过,因为有可能其他线程的修改结果和原数据的结果是一致的,所以CAS操作并不能感知到共享数据是否被其他线程修改过,这也是典型的CAS操作的ABA问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public void withdraw (Integer amount) { while (true ) { while (true ) { int prev = balance.get(); int next = prev - amount; if (balance.compareAndSet(prev, next)) { break ; } } } }
其中的关键是 compareAndSet ,它的简称就是 CAS (也有 Compare And Swap 的说法),它必须是原子操作。
注意
其实 CAS 的底层是 lock cmpxchg 指令(X86 架构),在单核 CPU 和多核 CPU 下都能够保证【比较-交 换】的原子性。
在多核状态下,某个核执行到带 lock 的指令时,CPU 会让总线锁住,当这个核把此指令执行完毕,再 开启总线。这个过程中不会被线程的调度机制所打断,保证了多个线程对内存操作的准确性,是原子 的。
volatile 获取共享变量时,为了保证该变量的可见性,需要使用 volatile 修饰。
它可以用来修饰成员变量和静态成员变量,他可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取 它的值,线程操作 volatile 变量都是直接操作主存。即一个线程对 volatile 变量的修改,对另一个线程可见。
注意
volatile 仅仅保证了共享变量的可见性,让其它线程能够看到最新值,但不能解决指令交错问题(不能保证原 子性)
CAS 必须借助 volatile 才能读取到共享变量的最新值来实现【比较并交换】的效果
为什么无锁效率高
无锁情况下,即使重试失败,线程始终在高速运行,没有停歇,类似于自旋。而 synchronized 会让线程在没有获得锁的时候,发生上下文切换,进入阻塞。线程的上下文切换是费时的,在重试次数不是太多时,无锁的效率高于有锁。
线程就好像高速跑道上的赛车,高速运行时,速度超快,一旦发生上下文切换,就好比赛车要减速、熄火, 等被唤醒又得重新打火、启动、加速… 恢复到高速运行,代价比较大
但无锁情况下,因为线程要保持运行,需要额外 CPU 的支持,CPU 在这里就好比高速跑道,没有额外的跑 道,线程想高速运行也无从谈起,虽然不会进入阻塞,但由于没有分到时间片,仍然会进入可运行状态,还 是会导致上下文切换。所以总的来说,当线程数小于等于cpu核心数时,使用无锁方案是很合适的,因为有足够多的cpu让线程运行。当线程数远多于cpu核心数时,无锁效率相比于有锁就没有太大优势,因为依旧会发生上下文切换
线程上下文切换的成本可以结合计组的中断执行原理来理解 ,线程上下文切换需要保存操作现场,此过程会耗费很多资源,其次在恢复操作现场时,也会耗费很多资源
CAS 的特点 结合 CAS 和 volatile 可以实现无锁并发,适用于线程数少、多核 CPU 的场景下 。
CAS 是基于乐观锁的思想 :最乐观的估计,不怕别的线程来修改共享变量,就算改了也没关系,我吃亏点再 重试呗
synchronized 是基于悲观锁的思想 :最悲观的估计,得防着其它线程来修改共享变量,我上了锁你们都别想 改,我改完了解开锁,你们才有机会。
CAS 体现的是无锁并发、无阻塞并发,请仔细体会这两句话的意思
因为没有使用 synchronized,所以线程不会陷入阻塞,这是效率提升的因素之一
但如果竞争激烈,可以想到重试必然频繁发生,反而效率会受影响
原子整数 J.U.C 并发包提供了:
AtomicBoolean
AtomicInteger
AtomicLong
以 AtomicInteger 为例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 AtomicInteger i = new AtomicInteger (0 );System.out.println(i.getAndIncrement()); System.out.println(i.incrementAndGet()); System.out.println(i.decrementAndGet()); System.out.println(i.getAndDecrement()); System.out.println(i.getAndAdd(5 )); System.out.println(i.addAndGet(-5 )); System.out.println(i.getAndUpdate(p -> p - 2 )); System.out.println(i.updateAndGet(p -> p + 2 )); System.out.println(i.getAndAccumulate(10 , (p, x) -> p + x)); System.out.println(i.accumulateAndGet(-10 , (p, x) -> p + x));
说明:
原子引用 为什么需要原子引用类型?
AtomicReference
AtomicMarkableReference
AtomicStampedReference
实际开发的过程中我们使用的不一定是int、long等基本数据类型,也有可能时BigDecimal这样的类型,这时就需要用到原子引用作为容器 。原子引用设置值使用的是unsafe.compareAndSwapObject()方法。原子引用中表示数据的类型需要重写equals()方法。
有如下方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public interface DecimalAccount { BigDecimal getBalance () ; void withdraw (BigDecimal amount) ; static void demo (DecimalAccount account) { List<Thread> ts = new ArrayList <>(); for (int i = 0 ; i < 1000 ; i++) { ts.add(new Thread (() -> { account.withdraw(BigDecimal.TEN); })); } ts.forEach(Thread::start); ts.forEach(t -> { try { t.join(); } catch (InterruptedException e) { e.printStackTrace(); } }); System.out.println(account.getBalance()); } }
试着提供不同的 DecimalAccount 实现,实现安全的取款操作
不安全实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class DecimalAccountUnsafe implements DecimalAccount { BigDecimal balance; public DecimalAccountUnsafe (BigDecimal balance) { this .balance = balance; } @Override public BigDecimal getBalance () { return balance; } @Override public void withdraw (BigDecimal amount) { BigDecimal balance = this .getBalance(); this .balance = balance.subtract(amount); } }
安全实现-使用锁 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class DecimalAccountSafeLock implements DecimalAccount { private final Object lock = new Object (); BigDecimal balance; public DecimalAccountSafeLock (BigDecimal balance) { this .balance = balance; } @Override public BigDecimal getBalance () { return balance; } @Override public void withdraw (BigDecimal amount) { synchronized (lock) { BigDecimal balance = this .getBalance(); this .balance = balance.subtract(amount); } } }
安全实现-使用 CAS 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class DecimalAccountSafeCas implements DecimalAccount { AtomicReference<BigDecimal> ref; public DecimalAccountSafeCas (BigDecimal balance) { ref = new AtomicReference <>(balance); } @Override public BigDecimal getBalance () { return ref.get(); } @Override public void withdraw (BigDecimal amount) { while (true ) { BigDecimal prev = ref.get(); BigDecimal next = prev.subtract(amount); if (ref.compareAndSet(prev, next)) { break ; } } } }
测试代码
1 2 3 DecimalAccount.demo(new DecimalAccountUnsafe(new BigDecimal("10000" ))); DecimalAccount.demo(new DecimalAccountSafeLock(new BigDecimal("10000" ))); DecimalAccount.demo(new DecimalAccountSafeCas(new BigDecimal("10000" )));
运行结果
1 2 3 4310 cost: 425 ms 0 cost: 285 ms 0 cost: 274 ms
ABA 问题及解决 概念: CAS操作并不能感知共享数据是否被其他线程修改过,因为可能修改的数据值和原线程操作的数据值是一致的,此时是完全感知不到共享数据是被修改过的
如果想要解决ABA问题,可以给操作的共享数据加一个版本号或者加一个boolean值标识其是否被其他线程修改过即可
ABA 问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 static AtomicReference<String> ref = new AtomicReference <>("A" );public static void main (String[] args) throws InterruptedException { log.debug("main start..." ); String prev = ref.get(); other(); sleep(1 ); log.debug("change A->C {}" , ref.compareAndSet(prev, "C" )); } private static void other () { new Thread (() -> { log.debug("change A->B {}" , ref.compareAndSet(ref.get(), "B" )); }, "t1" ).start(); sleep(0.5 ); new Thread (() -> { log.debug("change B->A {}" , ref.compareAndSet(ref.get(), "A" )); }, "t2" ).start(); }
输出
1 2 3 4 11:29:52.325 c.Test36 [main] - main start... 11:29:52.379 c.Test36 [t1] - change A->B true 11:29:52.879 c.Test36 [t2] - change B->A true 11:29:53.880 c.Test36 [main] - change A->C true
主线程仅能判断出共享变量的值与最初值 A 是否相同,不能感知到这种从 A 改为 B 又 改回 A 的情况,如果主线程 希望:
只要有其它线程【动过了】共享变量,那么自己的 cas 就算失败,这时,仅比较值是不够的,需要再加一个版本号
AtomicStampedReference
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 static AtomicStampedReference<String> ref = new AtomicStampedReference <>("A" , 0 );public static void main (String[] args) throws InterruptedException { log.debug("main start..." ); String prev = ref.getReference(); int stamp = ref.getStamp(); log.debug("版本 {}" , stamp); other(); sleep(1 ); log.debug("change A->C {}" , ref.compareAndSet(prev, "C" , stamp, stamp + 1 )); } private static void other () { new Thread (() -> { log.debug("change A->B {}" , ref.compareAndSet(ref.getReference(), "B" , ref.getStamp(), ref.getStamp() + 1 )); log.debug("更新版本为 {}" , ref.getStamp()); }, "t1" ).start(); sleep(0.5 ); new Thread (() -> { log.debug("change B->A {}" , ref.compareAndSet(ref.getReference(), "A" , ref.getStamp(), ref.getStamp() + 1 )); log.debug("更新版本为 {}" , ref.getStamp()); }, "t2" ).start(); }
输出为
1 2 3 4 5 6 7 15:41:34.891 c.Test36 [main] - main start... 15:41:34.894 c.Test36 [main] - 版本 0 15:41:34.956 c.Test36 [t1] - change A->B true 15:41:34.956 c.Test36 [t1] - 更新版本为 1 15:41:35.457 c.Test36 [t2] - change B->A true 15:41:35.457 c.Test36 [t2] - 更新版本为 2 15:41:36.457 c.Test36 [main] - change A->C false
AtomicStampedReference 可以给原子引用加上版本号,追踪原子引用整个的变化过程,如: A -> B -> A -> C ,通过AtomicStampedReference,我们可以知道,引用变量中途被更改了几次。
但是有时候,并不关心引用变量更改了几次,只是单纯的关心是否更改过 ,所以就有了AtomicMarkableReference
AtomicMarkableReference
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 static AtomicMarkableReference<String> ref = new AtomicMarkableReference <>("A" ,true ); public static void main (String[] args) throws InterruptedException { log.debug("main start..." ); String prev = ref.getReference(); boolean marked = ref.isMarked(); other(); Thread.sleep(10 ); log.info("marked:{}" ,marked); log.debug("change A->C {}" , ref.compareAndSet(prev, "C" ,true ,false )); } private static void other () throws InterruptedException { new Thread (() -> { boolean marked = ref.isMarked(); String pre = ref.getReference(); log.info("marked:{}" ,marked); log.debug("change A->B {}" , ref.compareAndSet(pre, "B" ,true ,false )); }, "t1" ).start(); Thread.sleep(1 ); new Thread (() -> { boolean marked = ref.isMarked(); String pre = ref.getReference(); log.info("marked:{}" ,marked); log.debug("change B->A {}" , ref.compareAndSet(pre, "A" ,true ,false )); }, "t2" ).start(); }
输出
1 2 3 4 5 6 7 14:35:57.761 [main] DEBUG com.czq.four.Test3 - main start... 14:35:57.805 [t1] INFO com.czq.four.Test3 - marked:true 14:35:57.806 [t1] DEBUG com.czq.four.Test3 - change A->B true 14:35:57.807 [t2] INFO com.czq.four.Test3 - marked:false 14:35:57.807 [t2] DEBUG com.czq.four.Test3 - change B->A false 14:35:57.817 [main] INFO com.czq.four.Test3 - marked:true 14:35:57.817 [main] DEBUG com.czq.four.Test3 - change A->C false
实际上大多数情况ABA问题并不会影响CAS操作的正确性,因为即使发生了ABA问题,也就是共享数据让其他线程修改过,但他们的修改结果和原线程操作的数据结果是一致的,所以并不会影响CAS操作的正确性
原子数组
AtomicIntegerArray
AtomicLongArray
AtomicReferenceArray
有如下方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 private static <T> void demo ( Supplier<T> arraySupplier, Function<T, Integer> lengthFun, BiConsumer<T, Integer> putConsumer, Consumer<T> printConsumer ) { List<Thread> ts = new ArrayList <>(); T array = arraySupplier.get(); int length = lengthFun.apply(array); for (int i = 0 ; i < length; i++) { ts.add(new Thread (() -> { for (int j = 0 ; j < 10000 ; j++) { putConsumer.accept(array, j%length); } })); } ts.forEach(t -> t.start()); ts.forEach(t -> { try { t.join(); } catch (InterruptedException e) { e.printStackTrace(); } }); printConsumer.accept(array); }
不安全的数组
1 2 3 4 5 6 demo( ()->new int [10 ], (array)->array.length, (array, index) -> array[index]++, array-> System.out.println(Arrays.toString(array)) );
结果
1 [9870, 9862, 9774, 9697, 9683, 9678, 9679, 9668, 9680, 9698]
安全的数组
1 2 3 4 5 6 demo( ()-> new AtomicIntegerArray (10 ), (array) -> array.length(), (array, index) -> array.getAndIncrement(index), array -> System.out.println(array) );
结果
1 [10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000]
字段更新器
AtomicReferenceFieldUpdater // 域 字段
AtomicIntegerFieldUpdater
AtomicLongFieldUpdater 利用字段更新器,可以针对对象的某个域(Field)进行原子操作,只能配合 volatile 修饰的字段使用,否则会出现异常
1 Exception in thread "main" java.lang.IllegalArgumentException: Must be volatile type
前面的原子引用进行CAS操作时针对是对象的地址值进行操作,而无法针对对象里的内容(属性)进行CAS操作,那么字段更新器其就是针对这一点而出现的解决方案,可以针对对象的某个属性进行CAS操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class Test5 { private volatile int field; public static void main (String[] args) { AtomicIntegerFieldUpdater fieldUpdater = AtomicIntegerFieldUpdater.newUpdater(Test5.class, "field" ); Test5 test5 = new Test5 (); fieldUpdater.compareAndSet(test5, 0 , 10 ); System.out.println(test5.field); fieldUpdater.compareAndSet(test5, 10 , 20 ); System.out.println(test5.field); fieldUpdater.compareAndSet(test5, 10 , 30 ); System.out.println(test5.field); } }
输出
原子累加器 jdk专门设计的了一个原子累加器LongAdder,比原子整数累加的性能足足提高了10倍有余
累加器性能比较 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 private static <T> void demo (Supplier<T> adderSupplier, Consumer<T> action) { T adder = adderSupplier.get(); long start = System.nanoTime(); List<Thread> ts = new ArrayList <>(); for (int i = 0 ; i < 40 ; i++) { ts.add(new Thread (() -> { for (int j = 0 ; j < 500000 ; j++) { action.accept(adder); } })); } ts.forEach(t -> t.start()); ts.forEach(t -> { try { t.join(); } catch (InterruptedException e) { e.printStackTrace(); } }); long end = System.nanoTime(); System.out.println(adder + " cost:" + (end - start)/1000_000 ); }
比较 AtomicLong 与 LongAdder
1 2 3 4 5 6 for (int i = 0 ; i < 5 ; i++) { demo(() -> new LongAdder (), adder -> adder.increment()); } for (int i = 0 ; i < 5 ; i++) { demo(() -> new AtomicLong (), adder -> adder.getAndIncrement()); }
输出
1 2 3 4 5 6 7 8 9 10 1000000 cost:43 1000000 cost:9 1000000 cost:7 1000000 cost:7 1000000 cost:7 1000000 cost:31 1000000 cost:27 1000000 cost:28 1000000 cost:24 1000000 cost:22
性能提升的原因很简单,就是在有竞争时,设置多个累加单元,Therad-0 累加 Cell[0],而 Thread-1 累加 Cell[1]… 最后将结果汇总。这样它们在累加时操作的不同的 Cell 变量,因此减少了 CAS 重试失败,从而提高性能
性能提升的核心理解
需要明确的一点是,CAS操作性能之所以低的原因是共享资源在多线程竞争环境下需要不断的重试,直到CAS操作执行成功为止,实质上不断的重试是在不断的消耗cpu资源,性能自然低下,而原子累加器通过将一个加法的数据拆分n份数据,每个线程单独操作他的数据进行累加,最后再进行合并,这样就会不会出现多线程操作共享资源出现竞争的情况,进而避免了不断重试的机制,大大提高了累加执行的性能
源码之 LongAdder LongAdder 是并发大师 @author Doug Lea (大哥李)的作品,设计的非常精巧
LongAdder 类有几个关键域
1 2 3 4 5 6 7 transient volatile Cell[] cells;transient volatile long base;transient volatile int cellsBusy;
CAS锁 实践上不推荐使用CAS锁解决线程安全问题,因为可能会出现一些不可控的问题,底层源码是做了全面的考虑的,所以不会有这些问题,但个人不建议使用**(了解即可)**
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 private AtomicInteger state = new AtomicInteger (0 );public void lock () { while (true ){ if (state.compareAndSet(0 ,1 )) { break ; } } } public void unlock () { state.set(0 ); }
其中 Cell 即为累加单元
1 2 3 4 5 6 7 8 9 10 11 12 @sun .misc.Contendedstatic final class Cell { volatile long value; Cell(long x) { value = x; } final boolean cas (long prev, long next) { return UNSAFE.compareAndSwapLong(this , valueOffset, prev, next); } }
防止缓存行伪共享 概念: 避免不同CPU核心操作的是内存地址上连续但实际上操作的是不同的数据而造成的牵一发而动全身的数据一致性问题,进而提高多核CPU的执行性能**(因为可以在一定程度上减少了数据同步造成的资源消耗)**
得从缓存说起
缓存与内存的速度比较
因为 CPU 与 内存的速度差异很大,需要靠预读数据至缓存来提升效率。
而**缓存以缓存行为单位,每个缓存行对应着一块内存(缓存和内存的映射关系)**,一般是 64 byte(8 个 long)
缓存的加入会造成数据副本的产生,即同一份数据会缓存在不同核心的缓存行中
CPU 要保证数据的一致性,如果某个 CPU 核心更改了数据,其它 CPU 核心对应的整个缓存行必须失效
因为 Cell 是数组形式,在内存中是连续存储的,一个 Cell 为 24 字节(16 字节的对象头和 8 字节的 value),因 此缓存行可以存下 2 个的 Cell 对象。这样问题来了:
Core-0(即第一个CPU核心) 要修改 Cell[0]
Core-1(即第二个CPU核心) 要修改 Cell[1]
无论谁修改成功,都会导致对方 Core 的缓存行失效 ,比如Core-0 中Cell[0]=6000, Cell[1]=8000要累加Cell[0]=6001, Cell[1]=8000 ,这时会让 Core-1 的缓存行失效
@sun.misc.Contended 用来解决这个问题,它的原理是在使用此注解的对象或字段的前后各增加 128 字节大小的 padding,从而让 CPU 将对象预读至缓存时占用不同的缓存行,这样,不会造成对方缓存行的失效
小总结
问题:
因CPU的与内存的速度差异极大,通过引入多级缓存方案解决,但引入多级缓存又会导致不同CPU核心之间的缓存数据一致性问题,如果是不同的CPU核心操作缓存同一块内存数据,那数据一致性的问题自然无法优化,但如果是不同的CPU核心操作的是内存地址上连续但不同的内存数据,也会造成其他CPU核心失效,失效的原因就是因为操作的数据在内存地址上是连续的,会作为一个整体被CPU核心读入到缓存行当中,只要修改地址上任意一个数据,那么整条连续的缓存数据都需要和其他CPU核心的缓存进行同步,以及和内存数据进行同步,非常浪费资源
解决方案
缓存行在缓存内存地址上连续的数据时,保证只缓存CPU核心想要读取的数据,而不会因为其内存上地址连续的原因进而把其他数据也缓存进来,如何保证呢?那就是在缓存好CPU核心想要读取的数据后,我们就在缓存数据前后个增加128字节的padding数据,保证缓存行不会因为地址连续而缓存了内存地址上连续的其他数据
累加器执行流程源码解析 add方法源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public void add (long x) { Cell[] as; long b, v; int m; Cell a; if ((as = cells) != null || !casBase(b = base, b + x)) { boolean uncontended = true ; if ( as == null || (m = as.length - 1 ) < 0 || (a = as[getProbe() & m]) == null || !(uncontended = a.cas(v = a.value, v + x)) ) { longAccumulate(x, null , uncontended); } } }
add 流程图
总结 :
如果已经有了累加数组或给base累加发生了竞争导致失败
如果累加数组没有创建或者累加数组长度为1或者当前线程还没有对应的cell或者累加cell失败
否者说明累加成功,退出。
否则累加成功
longAccumulate方法源码解析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 final void longAccumulate (long x, LongBinaryOperator fn, boolean wasUncontended) { int h; if ((h = getProbe()) == 0 ) { ThreadLocalRandom.current(); h = getProbe(); wasUncontended = true ; } boolean collide = false ; for (;;) { Cell[] as; Cell a; int n; long v; if ((as = cells) != null && (n = as.length) > 0 ) { if ((a = as[(n - 1 ) & h]) == null ) { if (cellsBusy == 0 ) { Cell r = new Cell (x); if (cellsBusy == 0 && casCellsBusy()) { boolean created = false ; try { Cell[] rs; int m, j; if ((rs = cells) != null && (m = rs.length) > 0 && rs[j = (m - 1 ) & h] == null ) { rs[j] = r; created = true ; } } finally { cellsBusy = 0 ; } if (created) break ; continue ; } } collide = false ; } else if (!wasUncontended) wasUncontended = true ; else if (a.cas(v = a.value, ((fn == null ) ? v + x : fn.applyAsLong(v, x)))) break ; else if (n >= NCPU || cells != as) collide = false ; else if (!collide) collide = true ; else if (cellsBusy == 0 && casCellsBusy()) { continue ; } h = advanceProbe(h); } else if (cellsBusy == 0 && cells == as && casCellsBusy()) { boolean init = false ; try { if (cells == as) { Cell[] rs = new Cell [2 ]; rs[h & 1 ] = new Cell (x); cells = rs; init = true ; } } finally { cellsBusy = 0 ; } if (init) break ; } else if (casBase(v = base, ((fn == null ) ? v + x : fn.applyAsLong(v, x)))) break ; } }
longAccumulate 流程图
cells未创建 条件分支执行流程图
cell未创建 条件分支执行流程图
cell已创建 条件分支执行流程图
每个线程刚进入 longAccumulate 时,会尝试对应一个 cell 对象(找到一个坑位)
总结:
先判断当前线程有没有对应的Cell
如果没有,随机生成一个值,这个值与当前线程绑定,通过这个值的取模运算定位当前线程Cell的位置。
进入for循环
获取最终结果通过 sum 方法
1 2 3 4 5 6 7 8 9 10 11 public long sum () { Cell[] as = cells; Cell a; long sum = base; if (as != null ) { for (int i = 0 ; i < as.length; ++i) { if ((a = as[i]) != null ) sum += a.value; } } return sum; }
无锁实现的缺陷
ABA问题 。CAS需要在操作值的时候检查内存值是否发生变化,没有发生变化才会更新内存值。但是如果内存值原来是A,后来变成了B,然后又变成了A,那么CAS进行检查时会发现值没有发生变化,但是实际上是有变化的。ABA问题的解决思路就是在变量前面添加版本号,每次变量更新的时候都把版本号加一,这样变化过程就从“A-B-A”变成了“1A-2B-3A”
循环时间长开销大 。CAS操作如果长时间不成功,会导致其一直自旋,给CPU带来非常大的开销
3.只能保证一个共享变量的原子操作 。对一个共享变量执行操作时,CAS能够保证原子操作,但是对多个共享变量操作时,CAS是无法保证操作的原子性的。Java从1.5开始JDK提供了AtomicReference类来保证引用对象之间的原子性,可以把多个变量放在一个对象里来进行CAS操作
举例说明:一旦遇到多个共享变量的操作时,需要同时操作多个原子对象时,操作就会变得非常复杂和麻烦,线程的安全性就难以实现,典型的案例就是后面线程安全集合CurrentHashMap实现统计26个字母的数量的案例,足足26个共享变量,使用无锁实现非常难以控制
4.虽然CAS操作本身是原子性的,但是多个线程之间仍然可能会发生并发读写竞争,导致数据不一致的问题。例如,如果一个线程正在读取某个共享变量的值,同时另外一个线程正在修改该变量的值,那么第一个线程读到的值就可能跟实际的值不一致。核心原因是CAS操作只能让写线程彼此互相感知,而读操作是不需要修改数据的,自然不需要CAS操作,就导致了读写线程彼此是不能互相感知的。
小总结
1.无锁实现对比有锁实现虽然能够大幅度提高并发线程的效率,但是他并不能保障读写并发的数据一致性问题。对比有锁来说,无锁的好处具体体现在读读并发,读写并发两种并发操作类型读操作是不受影响的,并且读写并发不用切换线程上下文,从而达到大幅度提高线程并发的效果。
2.但有锁也能实现这样的效果,使用读写分离的思想即可,但是不如无锁实现的读读并发,读写并发的效率高,因为无锁实现的读操作是不受限制的,不需要像有锁实现那样需要加锁。当然无锁实现这样做的代价是牺牲了读写并发的数据一致性。
3.所以具体选用有锁实现还是无锁实现,有锁实现选择那种方案都要根据你的需求来,没有哪一种方案是十全十美的
Unsafe 概述 Unsafe 对象提供了非常底层的,操作内存、线程的方法 ,Unsafe 对象不能直接调用,只能通过反射获得。jdk8直接调用Unsafe.getUnsafe()获得的unsafe不能用
CAS的底层就是用Unsafe实现的,因为CAS的比较并交换是CPU指令级来保证原子性的,所以需要直接操作计算机底层的内存和线程资源,当然Java语言并没有提供操作计算机底层资源的操作,所以Unsafe底层是用C++来实现的,因为C++可以直接操作计算机底层的内存,线程等资源
反射获取 Unsafe对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class UnsafeAccessor { static Unsafe unsafe; static { try { Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe" ); theUnsafe.setAccessible(true ); unsafe = (Unsafe) theUnsafe.get(null ); } catch (NoSuchFieldException | IllegalAccessException e) { throw new Error (e); } } static Unsafe getUnsafe () { return unsafe; } }
Unsafe对象的方法
1 2 3 4 5 6 7 public final native boolean compareAndSwapObject (Object var1, long var2, Object var4, Object var5) ;public final native boolean compareAndSwapInt (Object var1, long var2, int var4, int var5) ;public final native boolean compareAndSwapLong (Object var1, long var2, long var4, long var6) ;
细节
Unsafe对象对某一个对象的属性进行CAS操作时涉及到一个偏移量的概念,偏移量是该属性相对该对象的内存偏移地址,可以帮助我们准确的定位到该属性的内存空间,但是经过测试发现不同对象的同一个属性,他们的偏移量是一致的,所以偏移量应该是属于类的概念,而不是属于对象的概念,当然具体的细节得等后续学习JVM时了解对象的内存存储模型时才能知道
Unsafe 实现CAS 操作 CAS 操作的核心思想就是比较并交换,无论是那种原子类型(原子整数,原子引用,原子数组…),核心都是比较并交换,只是操作的数据类型不一致而已
unsafe实现字段更新 1 2 3 4 5 @Data class Student { volatile int id; volatile String name; }
1 2 3 4 5 6 7 8 9 10 11 12 Unsafe unsafe = UnsafeAccessor.getUnsafe();Field id = Student.class.getDeclaredField("id" );Field name = Student.class.getDeclaredField("name" );long idOffset = UnsafeAccessor.unsafe.objectFieldOffset(id);long nameOffset = UnsafeAccessor.unsafe.objectFieldOffset(name);Student student = new Student ();UnsafeAccessor.unsafe.compareAndSwapInt(student, idOffset, 0 , 20 ); UnsafeAccessor.unsafe.compareAndSwapObject(student, nameOffset, null , "张三" ); System.out.println(student);
输出
unsafe模拟实现原子整数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class MyAtomicInteger { volatile int value; final static Unsafe unsafe; final static long valueOffset; static { unsafe = Test.getUnsafe(); try { valueOffset = unsafe.objectFieldOffset(MyAtomicInteger.class.getDeclaredField("value" )); } catch (NoSuchFieldException e) { e.printStackTrace(); throw new RuntimeException (); } } public int getValue () { return value; } public boolean compareAndSet (int pre,int next) { while (true ){ if (unsafe.compareAndSwapInt(this ,valueOffset,pre,next)){ return true ; } } }
测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public static void main (String[] args) throws InterruptedException { MyAtomicInteger myAtomicInteger = new MyAtomicInteger (); new Thread (()->{ myAtomicInteger.compareAndSet(0 ,1 ); }).start(); new Thread (()->{ myAtomicInteger.compareAndSet(myAtomicInteger.getValue(),2 ); }).start(); Thread.sleep(10 ); System.out.println(myAtomicInteger.getValue()); }
本章小结
CAS 与 volatile
API
原子整数
原子引用
原子数组
字段更新器
原子累加器
Unsafe 原理方面
共享模型之不可变 日期转换的问题 问题提出 下面的代码在运行时,由于 SimpleDateFormat 不是线程安全的
1 2 3 4 5 6 7 8 9 10 SimpleDateFormat sdf = new SimpleDateFormat ("yyyy-MM-dd" );for (int i = 0 ; i < 10 ; i++) { new Thread (() -> { try { log.debug("{}" , sdf.parse("1951-04-21" )); } catch (Exception e) { log.error("{}" , e); } }).start(); }
有很大几率出现 java.lang.NumberFormatException 或者出现不正确的日期解析结果,例如:
思路 - 同步锁 这样虽能解决问题,但带来的是性能上的损失 ,并不算很好:
1 2 3 4 5 6 7 8 9 10 11 12 SimpleDateFormat sdf = new SimpleDateFormat ("yyyy-MM-dd" );for (int i = 0 ; i < 50 ; i++) { new Thread (() -> { synchronized (sdf) { try { log.debug("{}" , sdf.parse("1951-04-21" )); } catch (Exception e) { log.error("{}" , e); } } }).start(); }
思路 - 不可变 如果一个对象在不能够修改其内部状态(属性),那么它就是线程安全的,因为不存在并发修改啊! 这样的对象在 Java 中有很多,例如在 Java 8 后,提供了一个新的日期格式化类:
1 2 3 4 5 6 7 DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy-MM-dd" );for (int i = 0 ; i < 10 ; i++) { new Thread (() -> { LocalDate date = dtf.parse("2018-10-01" , LocalDate::from); log.debug("{}" , date); }).start(); }
可以看 DateTimeFormatter 的文档:
不可变对象,实际是另一种避免竞争的方式。
不可变设计 String类的设计 另一个大家更为熟悉的 String 类也是不可变的,以它为例,说明一下不可变设计的要素
1 2 3 4 5 6 7 8 9 10 public final class String implements java .io.Serializable, Comparable<String>, CharSequence { private final char value[]; private int hash; }
说明:
将类声明为final,避免被带外星方法的子类继承,从而破坏了不可变性
将字符数组设置private,不提供给外部类访问,自然无法修改字符数组中的内容
将字符数组声明为final,避免其引用被修改
hash虽然不是final的,但是其只有在调用hash()方法的时候才被赋值,除此之外再无别的方法修改
final 的使用 发现该类、类中所有属性都是 final 的
属性用 final 修饰保证了该属性是只读的,不能修改
类用 final 修饰保证了该类中的方法不能被覆盖,防止子类无意间破坏不可变性
保护性拷贝 但有同学会说,使用字符串时,也有一些跟修改相关的方法啊,比如 substring 等,那么下面就看一看这些方法是 如何实现的,就以 substring 为例:
1 2 3 4 5 6 7 8 9 10 11 public String ng (int beginIndex) { if (beginIndex < 0 ) { throw new StringIndexOutOfBoundsException (beginIndex); } int subLen = value.length - beginIndex; if (subLen < 0 ) { throw new StringIndexOutOfBoundsException (subLen); } return (beginIndex == 0 ) ? this : new String (value, beginIndex, subLen); }
发现其内部是调用 String 的构造方法创建了一个新字符串,再进入这个构造看看,是否对 final char[] value 做出 了修改:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public String (char value[], int offset, int count) { if (offset < 0 ) { throw new StringIndexOutOfBoundsException (offset); } if (count <= 0 ) { if (count < 0 ) { throw new StringIndexOutOfBoundsException (count); } if (offset <= value.length) { this .value = "" .value; return ; } } if (offset > value.length - count) { throw new StringIndexOutOfBoundsException (offset + count); } this .value = Arrays.copyOfRange(value, offset, offset+count); }
结果发现也没有,构造新字符串对象时,会生成新的 char[] value,对内容进行复制 。这种通过创建副本对象来避 免共享的手段称之为【保护性拷贝(defensive copy)】
享元模式 前情提要:
因为不可变类的设计会导致创建大量的对象资源,耗费的空间资源非常多。那些设计不可变类的人就想到了一种优化方法,既然每次都会创建一个新的对象,那我能不能复用这些已创建的对象资源呢?答案是可以的,这种方案就是使用著名的享元设计模式来实现的
定义:
运用共享技术来有效地支持大量细粒度对象的复用 ,它通过共享已经存在的对象来大幅度减少需要创建的对象数量、避免大量相似对象的开销 ,从而提高系统资源的利用率
享元模式的核心思想:复用共享资源(池化复用),避免共享资源重复创建而导致的浪费
体现 包装类
每种类型的包装类都有对应的常量池复用对应的包装类对象
在JDK中 Boolean,Byte,Short,Integer,Long,Character 等包装类提供了 valueOf 方法,例如 Long 的 valueOf 会缓存 -128~127 之间的 Long 对象,在这个范围之间会重用对象,大于这个范围,才会新建 Long 对 象:
1 2 3 4 5 6 7 public static Long valueOf (long l) { final int offset = 128 ; if (l >= -128 && l <= 127 ) { return LongCache.cache[(int )l + offset]; } return new Long (l); }
注意 :
Byte, Short, Long 缓存的范围都是 -128~127
Character 缓存的范围是 0~127
Integer的默认范围是 -128~127
最小值不能变
但最大值可以通过调整虚拟机参数 -Djava.lang.Integer.IntegerCache.high 来改变
Boolean 缓存了 TRUE 和 FALSE
String 串池 (不可变、线程安全)
详见jvm
BigDecimal BigInteger (不可变、线程安全)
一部分数字使用了享元模式进行了缓存。
手动实现一个连接池 例如:一个线上商城应用,QPS 达到数千,如果每次都重新创建和关闭数据库连接,性能会受到极大影响。 这时 预先创建好一批连接,放入连接池。一次请求到达后,从连接池获取连接,使用完毕后再还回连接池,这样既节约 了连接的创建和关闭时间,也实现了连接的重用,不至于让庞大的连接数压垮数据库。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 @Slf4j public class Pool { private int poosSize; private Connection[] connections; private AtomicIntegerArray states; public Pool (int poosSize) { this .poosSize = poosSize; connections = new Connection [poosSize]; for (int i = 0 ; i < poosSize; i++) { connections[i] = new MockConnection ("连接" +(i+1 )); } states = new AtomicIntegerArray (new int [poosSize]); } public Connection getConnection () { while (true ){ for (int i = 0 ; i < states.length(); i++) { if (states.get(i) == 0 ){ if (states.compareAndSet(i,0 ,1 )) { log.debug("get{}" ,connections[i]); return connections[i]; } } } synchronized (this ){ try { log.debug("wait...." ); this .wait(); } catch (InterruptedException e) { e.printStackTrace(); } } } } public void free (Connection connection) { for (int i = 0 ; i < connections.length; i++) { if (connections[i] == connection) { states.set(i,0 ); synchronized (this ){ log.debug("free {}" ,connection); this .notifyAll(); } break ; } } } }
使用连接池:
1 2 3 4 5 6 7 8 9 10 11 12 Pool pool = new Pool (2 );for (int i = 0 ; i < 5 ; i++) { new Thread (() -> { Connection conn = pool.borrow(); try { Thread.sleep(new Random ().nextInt(1000 )); } catch (InterruptedException e) { e.printStackTrace(); } pool.free(conn); }).start(); }
以上实现没有考虑:
连接的动态增长与收缩
连接保活(可用性检测)
等待超时处理
分布式 hash
对于关系型数据库,有比较成熟的连接池实现,例如c3p0, druid等 对于更通用的对象池,可以考虑使用apache commons pool,例如redis连接池可以参考jedis中关于连接池的实现
final原理 设置final 变量的原理 理解了 volatile 原理,再对比 final 的实现就比较简单了
1 2 3 public class TestFinal { final int a = 20 ; }
字节码
1 2 3 4 5 6 7 0: aload_0 1: invokespecial 4: aload_0 5: bipush 20 7: putfield <-- 写屏障 10: return
发现 final 变量的赋值也会通过 putfield 指令来完成,同样在这条指令之后也会加入写屏障,这样对final变量的写入不会重排序到构造方法之外,保证在其它线程读到 它的值时不会出现为 0 的情况。普通变量不能保证这一点了**(写操作前会加入写屏障保证可见性和有序性)**
读取final变量原理 有以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public class TestFinal { final static int A = 10 ; final static int B = Short.MAX_VALUE+1 ; final int a = 20 ; final int b = Integer.MAX_VALUE; final void test1 () { final int c = 30 ; new Thread (()->{ System.out.println(c); }).start(); final int d = 30 ; class Task implements Runnable { @Override public void run () { System.out.println(d); } } new Thread (new Task ()).start(); } } class UseFinal1 { public void test () { System.out.println(TestFinal.A); System.out.println(TestFinal.B); System.out.println(new TestFinal ().a); System.out.println(new TestFinal ().b); new TestFinal ().test1(); } } class UseFinal2 { public void test () { System.out.println(TestFinal.A); } }
反编译UseFinal1中的test方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 public test () V L0 LINENUMBER 31 L0 GETSTATIC java/lang/System.out : Ljava/io/PrintStream; BIPUSH 10 INVOKEVIRTUAL java/io/PrintStream.println (I)V L1 LINENUMBER 32 L1 GETSTATIC java/lang/System.out : Ljava/io/PrintStream; LDC 32768 INVOKEVIRTUAL java/io/PrintStream.println (I)V L2 LINENUMBER 33 L2 GETSTATIC java/lang/System.out : Ljava/io/PrintStream; NEW cn/itcast/n5/TestFinal DUP INVOKESPECIAL cn/itcast/n5/TestFinal.<init> ()V INVOKEVIRTUAL java/lang/Object.getClass ()Ljava/lang/Class; POP BIPUSH 20 INVOKEVIRTUAL java/io/PrintStream.println (I)V L3 LINENUMBER 34 L3 GETSTATIC java/lang/System.out : Ljava/io/PrintStream; NEW cn/itcast/n5/TestFinal DUP INVOKESPECIAL cn/itcast/n5/TestFinal.<init> ()V INVOKEVIRTUAL java/lang/Object.getClass ()Ljava/lang/Class; POP LDC 2147483647 INVOKEVIRTUAL java/io/PrintStream.println (I)V L4 LINENUMBER 35 L4 NEW cn/itcast/n5/TestFinal DUP INVOKESPECIAL cn/itcast/n5/TestFinal.<init> ()V INVOKEVIRTUAL cn/itcast/n5/TestFinal.test1 ()V L5 LINENUMBER 36 L5 RETURN L6 LOCALVARIABLE this Lcn/itcast/n5/UseFinal1; L0 L6 0 MAXSTACK = 3 MAXLOCALS = 1 }
可以看见,jvm对final变量的访问做出了优化:另一个类中的方法调用final变量是,不是从final变量所在类中获取(共享内存),而是直接复制一份到方法栈栈帧中的操作数栈中(工作内存),这样可以提升效率,是一种优化
总结:
对于较小的static final变量:复制一份到操作数栈中
对于较大的static final变量:复制一份到当前类的常量池中
对于非静态final变量,优化同上
核心的优化思想是如果使用final修饰变量,那底层将会在所有使用该变量的地方copy一份,避免其成为共享变量,就不需要使用各种耗费性能的手段解决线程安全问题,自然性能会得到很大的提升
final总结 final关键字的好处:
(1)final关键字提高了性能。JVM和Java应用都会缓存final变量
(2)final变量可以安全的在多线程环境下进行共享,而不需要额外的同步开销
(3)使用final关键字,JVM会对方法、变量及类进行优化
关于final的重要知识点
1、final关键字可以用于成员变量、本地变量、方法以及类
2、final成员变量必须在声明的时候初始化或者在构造器中初始化,否则就会报编译错误
3、你不能够对final变量再次赋值
4、本地变量必须在声明时赋值
5、在匿名类中所有变量都必须是final变量(为了保证二者数据的一致性,因为是通过拷贝机制复制值的,如果二者任意一个值发生改变,另一个值是感知不到的,那就会发生数据一致性问题,导致程序运行出错)
6、final方法不能被重写
7、final类不能被继承
8、final关键字不同于finally关键字,后者用于异常处理
9、final关键字容易与finalize()方法搞混,后者是在Object类中定义的方法,是在垃圾回收之前被JVM调用的方法
10、接口中声明的所有变量本身是final的
11、final和abstract这两个关键字是反相关的,final类就不可能是abstract的
12、final方法在编译阶段绑定,称为静态绑定(static binding)
13、没有在声明时初始化final变量的称为空白final变量(blank final variable),它们必须在构造器中初始化,或者调用this()初始化。不这么做的话,编译器会报错“final变量(变量名)需要进行初始化”
14、将类、方法、变量声明为final能够提高性能,这样JVM就有机会进行估计,然后优化
15、按照Java代码惯例,final变量就是常量,而且通常常量名要大写
16、对于集合对象声明为final指的是引用不能被更改,但是你可以向其中增加,删除或者改变内容
参考链接:Java中final实现原理的深入分析(附示例)-java教程-PHP中文网
无状态 在 web 阶段学习时,设计 Servlet 时为了保证其线程安全,都会有这样的建议,不要为 Servlet 设置成员变量,这 种没有任何成员变量的类是线程安全的
因为成员变量保存的数据也可以称为状态信息,因此没有成员变量就称之为【无状态】
无状态的意思就是没有成员变量也没有静态变量自然就没有共享资源,没有共享资源自然就不会发生线程安全问题
共享模型之工具 进程是什么?线程是什么?进程和线程的关系是什么?
进程是操作系统资源分配的基本单位,进程是程序运行的实例,线程是CPU任务调度的基本单位,那为什么资源分配的基本单位不能是线程呢?任务调度的基本单位不能是线程呢?
答案早期进程确实是任务调度的基本单位,CPU也是通过调度进程来完成任务的,但后面发现单进程效率和性能更低了,就向着多进程执行程序的方向前进,但后面又发现多进程的话,进程的通信成本非常高,进行的上下文切换成本也非常高,为什么成本非常高呢?因为创建一个进程所需要的系统资源是巨大的,而且每个进程是独立分配一份资源,没有共享资源,通信成本自然高,而且创建一个进程需要耗费巨大的资源,那你切换进程的上下文,需要切换的资源,重新加载的资源就是巨大的,自然进程的上下文也会耗费巨大的资源
主要的原因是创建进程是非常耗费资源的,而且又是独立分配资源,自然通信成本高,进程上下文切换成本高,提高进程的并发性成本就更高,所以科学家就研究出了一个更细小的可执行单位,线程,线程因为共享进程资源,导致其成本相较于进程大大降低,也正因为其共享资源,所以线程之间的通信成本也更低,自然而然线程的成本更低,并发性能还能更好,所以进程就专心做资源分配和管理的基本单位啦,具体进程中的任务就给成本更低,性能更好的线程啦
进程的上下文又是什么呢?线程的上下文又是什么呢?
进程的上下文就是进程运行所需要的环境支持,线程的上下文就是线程运行所需要的环境支持,具体是什么支持可以自行去网上搜索,我这里就不一一罗列了
CPU和进程的关系是什么?
CPU属于系统资源的一种,操作系统将CPU资源分配给进程,进程是资源分配的基本单位,也可以直接通俗的把进程看作是资源的容器
CPU与线程的关系又是什么?
实质上操作系统将CPU资源是分配给进程中的线程,因为线程才是任务调度的基本单位,而线程本身也归属于进程,所以也可以说操作系统将CPU资源分配了进程
内核是什么?内核的作用是什么?
内核是提供应用程序和硬件之间的桥梁,让应用程序可以屏蔽硬件的实现细节,通过内核中统一提供的接口来访问系统资源,既保护了系统资源的安全又让应用程序可以简单高效的利用系统资源,而不用让应用程序自己去搞懂硬件设备的细节
用户态和内核态是什么?为什么要区分用户态和内核态
为了更好区分应用程序的空间和系统程序的空间,操作系统的内核分为两种状态,一种是用户态,供应用程序进行访问和调用,另一种是内核态,供系统程序进行访问和调用。这样做的好处是更好的保护系统资源,让计算机处于一个更安全更可靠的环境上,应用程序的权限较少,如果要访问系统资源,用户态需要关联内核态的相关资源,发起系统调用方可调用系统资源
并发和并行的理解 并发和并行都是多任务处理的概念,但它们有着本质的区别
并发指的是在一段时间内同时处理多个任务,这些任务之间可能会相互干扰或者依赖。例如,在一个操作系统中,可能会同时运行多个应用程序,每个应用程序都独立运行,但是它们共享计算机的资源,如CPU、内存等。在并发处理中,并不需要同时执行每个任务,而是通过时间分片的方式轮流执行各个任务,让用户感觉好像所有任务都在同时执行。
而并行则指的是同时执行多个任务,这些任务之间没有相互干扰或者依赖关系。例如,在一个拥有多个CPU核心的计算机系统中,可以将多个不同的任务分配给不同的CPU核心同时执行。在并行处理中,每个任务被分配给不同的处理单元进行处理,从而提高了整个系统的处理能力。
因此,可以说并发强调的是多个任务在时间上的交错执行,而并行则强调多个任务在空间上的同时执行
多线程的理解 多线程的作用和意义 多线程的主要作用和意义是提高程序的并发性和性能,通过同时处理多个任务,最大限度地利用系统资源,加快程序的执行速度。多线程可以分为两种类型:CPU密集型任务和IO密集型任务 。在CPU密集型任务的情况下,单线程会花费很长时间来完成计算,而多线程则可以把任务分成多个子任务,利用多个CPU核心同时执行,提高计算效率,进而提高程序的性能
在IO密集型任务的情况下,单线程可能会花费很长时间在等待IO操作完成上,而多线程则可以将IO操作和计算任务分开,利用IO操作的等待时间,同时执行其他任务,充分利用系统资源,提高程序的性能。然而,使用多线程也会带来一些成本,比如线程管理和同步、锁和互斥、上下文切换等开销。因此,在使用多线程时,需要仔细权衡多线程的作用和带来的成本,综合考虑因素,以达到最优的应用效果
多线程的作用和意义核心总结:多线程是通过最大限度利用系统资源,从而达到提高程序的执行效率和性能的目的
最大限度利用系统资源 那么最大限度利用系统资源,这里的资源主要指什么呢?
从多线程的两种类型来理解:CPU密集型任务和IO密集型任务
后者是在IO任务执行时,CPU其实是不需要参与的,处于空闲状态,而且CPU的执行速度和IO的执行速度差距巨大,如果让CPU等待IO任务执行完,那么CPU就空闲了很久了,所以可以利用多线程切换CPU的控制权,充分利用CPU空闲等待的时间,大大提高CPU资源的利用率,实质上也是不能让CPU闲着
答案很明显了,系统资源主要指的是CPU资源和内存资源 ,CPU资源上面已经解释过了。接下来简单解释一下内存,任何数据要想使用都是要加载到内存中的,都是需要相应的磁盘空间去存储的,所以内存资源也是非常关键的系统资源
多线程主要耗费的资源(成本) 1.CPU资源:由于多线程需要在不同的时间片上进行调度和执行,因此多线程会占用一定的CPU资源,尤其对于计算密集型的任务,需要尽可能利用CPU资源提高计算效率
2.内存资源:每个线程都需要分配一定的内存空间,用于存储线程的上下文信息、栈空间、状态等。多线程的内存占用量随着线程数量的增加而增加,因此需要注意线程数目的控制
3.线程上下文切换资源:多个线程之间的切换需要保存当前线程的上下文信息并恢复下一个线程的上下文信息,这个过程称之为上下文切换。上下文切换需要消耗一定的CPU时间和内存空间,如果线程数目过多或者切换频繁,会导致系统性能下降
4.线程管理成本:系统需要维护一个线程池来管理所有的线程,包括线程的创建、销毁、调度、同步、互斥等操作。线程管理的开销随着线程数量的增加而增加,需要注意合理管理线程,以避免开销过大
5.锁和同步成本:多线程需要共享同一个资源或者变量时,需要采取锁或其他同步机制,以避免出现竞争和不一致的现象。锁和同步机制需要消耗额外的计算资源和内存空间,同时容易引起死锁、卡顿等问题
如何权衡多线程的作用和其带来的成本
在权衡好多线程的作用和其带来的成本时,需要考虑以下因素:
1.任务类型:任务类型是选择使用多线程还是单线程的重要条件之一
如果任务是CPU密集型任务,则可以尝试使用多线程来提高执行效率。如果任务是IO密集型任务,则需要根据具体情况来进行选择,可能需要通过采用异步IO等机制来提升效率
2.多线程耗费的资源和成本(上文有详解)
综上所述,在使用多线程实现程序时,需要根据任务类型、多线程带来的性能提升以及相应的成本消耗等因素进行综合评估和规划,以达到最优的程序效率和可靠性
至于具体如何权衡好多线程的作用以及其相应带来的成本,这个得大量的实践经验才能熟知
多线程和并发并行的关系又是什么?
想必读完前面你已经能清楚的知道,并发并行都是处理多任务的概念,那么多线程本身就能同一时间段处理多个任务,所以说多线程是实现并发并行的一种技术方案
多进程和多线程对比 多进程和多线程都是实现并发的方式,它们各有优缺点。下面我们来分别介绍它们的特点和比较
多进程
多线程
总结
核心:要将CPU,进程,线程三个概念串联起来,才能更好的理解并发并行,多线程的概念
究竟三者的关系是什么?三者分别的作用和意义又是什么?
线程池 自定义线程池
步骤1:自定义拒绝策略接口
1 2 3 4 5 6 7 8 9 10 @FunctionalInterface interface RejectPolicy <T>{ void reject (BlockingQueue<T> queue,T task) ; }
A.在任务队列满时可以让调用者自行选择拒绝任务的策略,使用策略模式而非if-else实现,可以大大提高程序的扩展性,降低代码的侵入性
步骤2:自定义任务队列(阻塞队列)
阻塞队列是用来在线程池没有空闲线程处理任务时,暂时存储任务数据 ,使用队列结构实现是因为任务消息的生产和任务消息的消费是一个入口一个出口,符合队列解构的先进先出的数据特点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 @Slf4j public class BlockingQueue <T> { private Deque<T> queue = new ArrayDeque <>(); private ReentrantLock lock = new ReentrantLock (); private Condition fullCondition = lock.newCondition(); private Condition emptyCondition = lock.newCondition(); private int capacity; public BlockingQueue (int capacity) { this .capacity = capacity; } public T take () { lock.lock(); try { while (queue.isEmpty()){ try { emptyCondition.await(); } catch (InterruptedException e) { e.printStackTrace(); } } T t = queue.removeFirst(); fullCondition.signalAll(); return t; } finally { lock.unlock(); } } public T poll (long timeOut, TimeUnit unit) { lock.lock(); try { long nanos = unit.toNanos(timeOut); while (queue.isEmpty()){ try { if (nanos<=0 ){ return null ; } nanos = emptyCondition.awaitNanos(nanos); } catch (InterruptedException e) { e.printStackTrace(); } } T t = queue.removeFirst(); fullCondition.signalAll(); return t; } finally { lock.unlock(); } } public void put (T task) { lock.lock(); try { while (queue.size() == capacity){ try { log.debug("等待加入任务队列{}..." , task); fullCondition.await(); } catch (InterruptedException e) { e.printStackTrace(); } } log.debug("task {} 加入任务队列" , task); queue.addLast(task); emptyCondition.signalAll(); }finally { lock.unlock(); } } public boolean offer (T task,long timeOut,TimeUnit unit) { lock.lock(); long nanos = unit.toNanos(timeOut); try { while (queue.size() == capacity){ try { if (nanos<=0 ){ return false ; } log.debug("等待加入任务队列{}..." , task); nanos = fullCondition.awaitNanos(nanos); } catch (InterruptedException e) { e.printStackTrace(); } } log.debug("task {} 加入任务队列" , task); queue.addLast(task); emptyCondition.signalAll(); return true ; }finally { lock.unlock(); } } public void tryPut (RejectPolicy<T> rejectPolicy, T task) { lock.lock(); try { if (queue.size() == capacity){ rejectPolicy.reject(this ,task); }else { log.debug("task {} 加入任务队列" , task); queue.addLast(task); emptyCondition.signalAll(); } }finally { lock.unlock(); } } }
A.ReentrantLock锁保证存储和获取任务队列中的任务元素时的线程安全性,不使用synchronized锁的原因是因为其只有一个条件变量,会有虚假唤醒问题
B.使用emptyCondition和fullCondition两个条件变量来平衡生产者和消费者的工作效率(线程间的通信),如果生产者效率太高,导致任务队列达到容量上限,则生产者线程切换成阻塞等待状态并且唤醒消费者线程消费任务,消费者同理
C.如何实现带超时时间的存储任务元素和获取任务元素版本
步骤3:自定义线程池
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 @Slf4j class ThreadPool { private BlockingQueue<Runnable> taskQueue; private int coreSize; private int timeOut; private TimeUnit unit; private HashSet<Worker> workers = new HashSet <>(); private RejectPolicy<Runnable> rejectPolicy; public void execute (Runnable task) { synchronized (workers) { if (workers.size()<coreSize){ Worker worker = new Worker (task); log.debug("新增worker{},task{}" ,worker,task); workers.add(worker); worker.start(); }else { taskQueue.tryPut(rejectPolicy,task); } } } public ThreadPool (int coreSize, int timeOut, TimeUnit unit,int queueCapacity,RejectPolicy<Runnable> rejectPolicy) { this .coreSize = coreSize; this .timeOut = timeOut; this .unit = unit; taskQueue = new BlockingQueue <>(queueCapacity); this .rejectPolicy = rejectPolicy; } class Worker extends Thread { private Runnable task; public Worker (Runnable task) { this .task = task; } @Override public void run () { while (task!=null ){ try { log.debug("正在执行...{}" ,task); task.run(); } catch (Exception e) { e.printStackTrace(); }finally { task = taskQueue.poll(timeOut,unit); } } synchronized (workers) { log.debug("worker 被移除{}" ,this ); workers.remove(this ); } } } }
A.线程池分配线程去执行任务时会出现线程安全问题,使用synchronized同步代码块解决
B.线程只能启动一次,也就是线程走完他的生命周期后就无法复用了,那这里的线程池是如何复用线程的呢?他是这样设计的:只要任务队列中还有任务,就让线程不断的获取任务并执行任务,直到任务队列中没有任务时才会让线程结束运行,在这个过程中,线程资源在每多执行一次任务时就是复用了一次,实际上已经复用了很多次了
C.任务队列满时的拒绝任务策略设计(策略模式实现)
D.在任务队列空时,线程空闲时,等待获取任务的超时时间控制,超过超时时间仍没有任务消费时,线程结束运行
步骤4:编写测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class ThreadPoolTest { public static void main (String[] args) { ThreadPool threadPool = new ThreadPool (1 ,10 , TimeUnit.MILLISECONDS,1 ,(queue,task)->{ task.run(); }); for (int i = 0 ; i < 4 ; i++) { int j = i; threadPool.execute(()->{ try { Thread.sleep(1000 ); } catch (InterruptedException e) { e.printStackTrace(); } log.debug("" +j); }); } } }
美团大佬写的关于自定义线程池的技术文章
Java线程池实现原理及其在美团业务中的实践 - 美团技术团队 (meituan.com)
ThreadPoolExecutor JDK线程池的类图解构
说明:
ScheduledThreadPoolExecutor是带调度**(定时器的任务调度)**的线程池
ThreadPoolExecutor是不带调度的线程池
线程池状态 ThreadPoolExecutor 使用 int 的高 3 位来表示线程池状态,低 29 位表示线程数量
状态名
高3位
接收新任务
处理阻塞队列任务
说明
RUNNING
111
Y
Y
SHUTDOWN
000
N
Y
不会接收新任务,但会处理阻塞队列剩余 任务
STOP
001
N
N
会中断正在执行的任务,并抛弃阻塞队列 任务
TIDYING
010
任务全执行完毕,活动线程为 0 即将进入 终结
TERMINATED
011
终结状态
从数字上比较,TERMINATED > TIDYING > STOP > SHUTDOWN > RUNNING(第一位符号位是1,是负数,所以排在最后)
这些信息存储在一个原子变量 ctl 中,目的是将线程池状态与线程个数合二为一,这样就可以用一次 cas 原子操作 进行赋值,如果用两个变量分别表示线程状态和线程数量,就要进行两次CAS操作
1 2 3 4 ctl.compareAndSet(c, ctlOf(targetState, workerCountOf(c)))); private static int ctlOf (int rs, int wc) { return rs | wc; }
构造方法 1 2 3 4 5 6 7 public ThreadPoolExecutor (int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
corePoolSize 核心线程数目 (最多保留的线程数)
maximumPoolSize 最大线程数目
keepAliveTime 生存时间 - 针对救急线程**(救急线程数 = 最大线程数-核心线程数 )** 也可以称为非核心线程数
unit 时间单位 - 针对救急线程
workQueue 阻塞队列
threadFactory 线程工厂 - 可以为线程创建时起个好名字,用来区别不同的线程池不同的线程,方便定位线程中的问题
handler 拒绝策略
工作方式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 graph LR subgraph 阻塞队列 size=2 t3(任务3) t4(任务4) end subgraph 线程池c-2,m=3 ct1(核心线程1) ct2(核心线程2) mt1(救急线程1) ct1 --> t1(任务1) ct2 --> t2(任务2) end t1(任务1) style ct1 fill:#ccf,stroke:#f66,stroke-width:2px style ct2 fill:#ccf,stroke:#f66,stroke-width:2px style mt1 fill:#ccf,stroke:#f66,stroke-width:2px,stroke-dasharray:5,5
线程池中刚开始没有线程,当一个任务提交给线程池后,线程池会创建一个新线程来执行任务。
当线程数达到 corePoolSize 并没有线程空闲,这时再加入任务,新加的任务会被加入workQueue 队列排 队,直到有空闲的线程
如果队列选择了有界队列,那么任务超过了队列大小时,会创建 maximumPoolSize - corePoolSize 数目的线程来救急
如果线程到达 maximumPoolSize 仍然有新任务这时会执行拒绝策略 。拒绝策略 jdk 提供了 4 种实现,其它 著名框架也提供了实现
AbortPolicy 让调用者抛出 RejectedExecutionException 异常,这是默认策略
CallerRunsPolicy 让调用者运行任务
DiscardPolicy 放弃本次任务
DiscardOldestPolicy 放弃队列中最早的任务,本任务取而代之
Dubbo 的实现,在抛出 RejectedExecutionException 异常之前会记录日志,并 dump 线程栈信息,方 便定位问题
Netty 的实现,是创建一个新线程来执行任务
ActiveMQ 的实现,带超时等待(60s)尝试放入队列,类似我们之前自定义的拒绝策略
PinPoint 的实现,它使用了一个拒绝策略链,会逐一尝试策略链中每种拒绝策略
当高峰过去后,超过corePoolSize 的救急线程如果一段时间没有任务做,需要结束节省资源,这个时间由 keepAliveTime 和 unit 来控制
根据这个构造方法,JDK Executors 类中提供了众多工厂方法来创建各种用途的线程池。
核心的参数只有三个:核心线程数,最大线程数,任务队列
首先你得明确知道的一点是,线程是操作系统非常宝贵的资源,频繁的创建和销毁非常耗费系统的资源,那么就凭这一点就注定了线程数是不可能无限的创建的,一定是要在系统资源合理承担范围内制定要创建的线程数
一旦超出这个线程数量,系统有可能会崩溃,或者出现各种各样的异常,所以到达最大线程数时一定是要拒绝任务。当然很多情况几个线程池也没有到达系统所能承担的最大线程数量,但是我们需要指定这个需求所需要的核心线程数以及的最大线程数,尽可能的最合理和最大化利用线程资源
核心线程数和最大线程数:一定要根据实际的需求去制定每个线程池真正需要的线程数量是多少而设置核心线程数以及最大线程数
任务队列:当任务数超过核心线程数处理的速度时,就需要任务队列暂存任务,等待核心线程数空闲时再处理(排队的过程)
个人对于线程池7个参数的理解问题
1.没有理解非核心线程数的作用和意义
在某些场景下,任务量非常大但是这种场景持续的时间是非常是短暂的,如果超过了饭店所能容纳的客流量,那么饭店会先让客人排队,客人后续其实都是能吃上饭的,只是排队时间久一点,如果排队的客流量也超出了排队的人数上限,也就是饭店知道大概排队多少人,直到晚上关店是可以把这些客流量完全消化掉的,但是一旦排队数量超过上限,那就是不紧急加人手和地方是忙不过来的,这种时候就是救急工人**(非核心线程)**出场的时候了。如果你一开始就聘请救急工人救场,其实是浪费资源了,因为饭店是完全可以消化掉这部分排队的客流量的,你请了工人只是把消化这部分客流量的时间提前了,对于饭店方来说没有任何意义,还徒增了人力成本
B.没有理解任务队列对线程池的作用和意义
线程池通俗的理解 线程池就是一群工人去干活,没活干得话就先休息,有活分配就去干活。工人的数量是有限的
分配任务的人
干活的人
问题:
A.工人群体
jdk自带的四种常见的线程池 newFixedThreadPool 源码解析
1 2 3 4 5 public static ExecutorService newFixedThreadPool (int nThreads) { return new ThreadPoolExecutor (nThreads, nThreads, 0L , TimeUnit.MILLISECONDS, new LinkedBlockingQueue <Runnable>()); }
内部调用了:ThreadPoolExecutor的一个构造方法
1 2 3 4 5 6 7 8 public ThreadPoolExecutor (int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) { this (corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, Executors.defaultThreadFactory(), defaultHandler); }
默认工厂以及默认构造线程的方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 DefaultThreadFactory() { SecurityManager s = System.getSecurityManager(); group = (s != null ) ? s.getThreadGroup() : Thread.currentThread().getThreadGroup(); namePrefix = "pool-" + poolNumber.getAndIncrement() + "-thread-" ; } public Thread newThread (Runnable r) { Thread t = new Thread (group, r, namePrefix + threadNumber.getAndIncrement(), 0 ); if (t.isDaemon()) t.setDaemon(false ); if (t.getPriority() != Thread.NORM_PRIORITY) t.setPriority(Thread.NORM_PRIORITY); return t; }
默认拒绝策略:抛出异常
1 private static final RejectedExecutionHandler defaultHandler = new AbortPolicy ();
特点
核心线程数 == 最大线程数(没有救急线程被创建),因此也无需超时时间
阻塞队列是无界的,可以放任意数量的任务
评价 适用于任务量已知,相对耗时的任务**(相对耗时不太理解)**
newCachedThreadPool 1 2 3 4 5 public static ExecutorService newCachedThreadPool () { return new ThreadPoolExecutor (0 , Integer.MAX_VALUE, 60L , TimeUnit.SECONDS, new SynchronousQueue <Runnable>()); }
特点
核心线程数是 0, 最大线程数是 Integer.MAX_VALUE,救急线程的空闲生存时间是 60s,
意味着全部都是救急线程(60s 后可以回收)
救急线程可以无限创建
队列采用了 SynchronousQueue 实现特点是,它没有容量,没有线程来取是放不进去的(一手交钱、一手交货)
实现存储任务和消费任务的同步性,不存在暂存任务的情况,如果没有空闲的线程可以消费任务消息,那我就阻塞等待一个新的线程创建并消费任务消息,生产消息和消费消息是同步的,没有暂存任务的阻塞队列机制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public static void main (String[] args) throws InterruptedException { SynchronousQueue<Integer> integers = new SynchronousQueue <>(); new Thread (()->{ try { log.debug("put..." ); integers.put(1 ); log.debug("putted..." ); } catch (InterruptedException e) { e.printStackTrace(); } }).start(); new Thread (()->{ log.debug("put2..." ); try { integers.put(2 ); } catch (InterruptedException e) { e.printStackTrace(); } log.debug("putted2..." ); }).start(); Thread.sleep(1000 ); integers.poll(); log.debug("take1 ..." ); integers.poll(); log.debug("take2..." ); }
输出
1 2 3 4 5 6 17:51:58.451 [Thread-0] DEBUG com.czq.six.TestSynchronousQueue - put... 17:51:58.451 [Thread-1] DEBUG com.czq.six.TestSynchronousQueue - put2... 17:51:59.453 [main] DEBUG com.czq.six.TestSynchronousQueue - take1 ... 17:51:59.453 [Thread-1] DEBUG com.czq.six.TestSynchronousQueue - putted2... 17:51:59.453 [main] DEBUG com.czq.six.TestSynchronousQueue - take2... 17:51:59.453 [Thread-0] DEBUG com.czq.six.TestSynchronousQueue - putted...
评价 整个线程池表现为线程数会根据任务量不断增长,没有上限,当任务执行完毕,空闲 1分钟后释放线 程。 适合任务数比较密集,但每个任务执行时间较短的情况
newSingleThreadExecutor 1 2 3 4 5 6 public static ExecutorService newSingleThreadExecutor () { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor (1 , 1 , 0L , TimeUnit.MILLISECONDS, new LinkedBlockingQueue <Runnable>())); }
使用场景:
**希望多个任务排队执行(在多线程的环境下实现任务的串行执行)**。线程数固定为 1,任务数多于 1 时,会放入无界队列排队。任务执行完毕,这唯一的线程 也不会被释放
与自己直接创建一个线程执行的区别:
自己创建一个单线程串行执行任务,如果任务执行失败而终止那么没有任何补救措施,而线程池还会新建一 个线程,保证池的正常工作
Executors.newSingleThreadExecutor() 线程个数始终为1,不能修改**(线程池的安全性可以得到保证)**
FinalizableDelegatedExecutorService 应用的是装饰器模式 ,在调用构造方法时将ThreadPoolExecutor对象传给了内部的ExecutorService接口。只对外暴露了 ExecutorService 接口,因此不能调用 ThreadPoolExecutor 中特有的方法,也不能重新设置线程池的大小
Executors.newFixedThreadPool(1) 初始时为1,以后还可以修改
对外暴露的是 ThreadPoolExecutor 对象,可以强转后调用 setCorePoolSize 等方法进行修改
提交任务 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void execute (Runnable command) ;<T> Future<T> submit (Callable<T> task) ; <T> List<Future<T>> invokeAll (Collection<? extends Callable<T>> tasks) throws InterruptedException; <T> List<Future<T>> invokeAll (Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException; <T> T invokeAny (Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException; <T> T invokeAny (Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException;
测试submit
1 2 3 4 5 6 7 8 9 10 11 private static void method1 (ExecutorService executorService) throws InterruptedException, ExecutionException { Future<String> future = executorService.submit(()->{ log.debug("running" ); Thread.sleep(1000 ); return "ok" ; }); String result = future.get(); log.debug("get {}" ,result); }
测试结果
1 2 17:59:40.981 [pool-1-thread-1] DEBUG com.czq.six.TestSubmit - running 17:59:41.984 [main] DEBUG com.czq.six.TestSubmit - ok
测试invokeAll
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 private static void method2 (ExecutorService executorService) throws InterruptedException { List<Future<String>> futureList = executorService.invokeAll(Arrays.asList( () -> { log.debug("1" ); Thread.sleep(200 ); return "1" ; }, () -> { log.debug("2" ); Thread.sleep(1000 ); return "2" ; }, () -> { log.debug("3" ); Thread.sleep(500 ); return "3" ; } )); futureList.forEach(future->{ try { String result = future.get(); log.debug("result:{}" ,result); } catch (InterruptedException | ExecutionException e) { e.printStackTrace(); } }); }
测试结果
1 2 3 4 5 6 18 :00 :20.351 [pool-1 -thread-2 ] DEBUG com.czq.six.TestSubmit - 2 18 :00 :20.351 [pool-1 -thread-1 ] DEBUG com.czq.six.TestSubmit - 1 18 :00 :20.560 [pool-1 -thread-1 ] DEBUG com.czq.six.TestSubmit - 3 18 :00 :21.359 [main] DEBUG com.czq.six.TestSubmit - result:1 18 :00 :21.361 [main] DEBUG com.czq.six.TestSubmit - result:2 18 :00 :21.361 [main] DEBUG com.czq.six.TestSubmit - result:3
测试invokeAny
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 private static void method3 (ExecutorService executorService) throws InterruptedException, ExecutionException { String result = executorService.invokeAny(Arrays.asList( () -> { log.debug("1" ); Thread.sleep(1500 ); return "1" ; }, () -> { log.debug("2" ); Thread.sleep(1000 ); return "2" ; }, () -> { log.debug("3" ); Thread.sleep(500 ); return "3" ; } )); log.debug("result:{}" ,result); }
测试结果
1 2 3 4 18:01:21.282 [pool-1-thread-1] DEBUG com.czq.six.TestSubmit - 1 18:01:21.282 [pool-1-thread-2] DEBUG com.czq.six.TestSubmit - 2 18:01:22.285 [pool-1-thread-2] DEBUG com.czq.six.TestSubmit - 3 18:01:22.285 [main] DEBUG com.czq.six.TestSubmit - result:2
关闭线程池 shutdown
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public void shutdown () { final ReentrantLock mainLock = this .mainLock; mainLock.lock(); try { checkShutdownAccess(); advanceRunState(SHUTDOWN); interruptIdleWorkers(); onShutdown(); } finally { mainLock.unlock(); } tryTerminate(); }
shutdownNow
1 2 3 4 5 6 7 List<Runnable> shutdownNow () ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public List<Runnable> shutdownNow () { List<Runnable> tasks; final ReentrantLock mainLock = this .mainLock; mainLock.lock(); try { checkShutdownAccess(); advanceRunState(STOP); interruptWorkers(); tasks = drainQueue(); } finally { mainLock.unlock(); } tryTerminate(); return tasks; }
其他方法
1 2 3 4 5 6 7 boolean isShutdown () ;boolean isTerminated () ;boolean awaitTermination (long timeout, TimeUnit unit) throws InterruptedException;
测试shutdown、shutdownNow、awaitTermination
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public static void main (String[] args) { ExecutorService executorService = Executors.newFixedThreadPool(2 ); executorService.submit(()->{ log.debug("1" ); Thread.sleep(1000 ); log.debug("take 1 finished" ); return "1" ; }); executorService.submit(()->{ log.debug("2" ); Thread.sleep(1000 ); log.debug("take 2 finished" ); return "2" ; }); executorService.submit(()->{ log.debug("3" ); Thread.sleep(1000 ); log.debug("take 3 finished" ); return "3" ; }); log.debug("other..." ); List<Runnable> tasks = executorService.shutdownNow(); log.debug("blockingQueue tasks {}" ,tasks); }
shutdown是优雅的结束线程池,会将线程池中的任务全部执行完毕再结束,而shutdownNow是暴力结束,会立即终止所有正在运行的任务,阻塞队列中的任务也不会被执行,而是直接返回交由调用者处理
工作线程模式之 Worker Thread 定义
让有限的工作线程(Worker Thread)来轮流异步处理无限多的任务。也可以将其归类为分工模式 ,它的典型实现 就是线程池,也体现了经典设计模式中的享元模式。
例如,海底捞的服务员(线程),轮流处理每位客人的点餐(任务),如果为每位客人都配一名专属的服务员,那 么成本就太高了(对比另一种多线程设计模式:Thread-Per-Message)
注意,不同任务类型应该使用不同的线程池,这样能够避免饥饿,并能提升效率
例如,如果一个餐馆的工人既要招呼客人(任务类型A),又要到后厨做菜(任务类型B)显然效率不咋地,分成 服务员(线程池A)与厨师(线程池B)更为合理,当然你能想到更细致的分工
饥饿
固定大小线程池会有饥饿现象。饥饿现象就是没有空闲的线程资源可以执行任务,导致其他依赖该任务的执行结果的线程也陷入阻塞状态,最后导致线程资源无法释放的现象,恶行循环
原因
原因版本1
核心的原因在于线程资源并非单一职责的专门处理某种任务类型,而是可以处理多种任务类型,从而引发了线程资源互相依赖但又不愿意释放手上的线程资源,就会导致越来越多的线程陷入阻塞状态,直到最后没有可用的线程资源(和死锁产生的原因非常类似)
原因版本2
核心原因就是线程资源不是单一职责的专门处理某种任务类型,否则即使任务之间存在依赖关系,但线程资源并不存在依赖关系,执行完相应的任务后就可以正常释放线程资源,即使线程资源不足也可以排队等候线程资源释放再执行,并不会出现线程资源无法释放的现象
两个工人是同一个线程池中的两个线程
他们要做的事情是:为客人点餐和到后厨做菜,这是两个阶段的工作
客人点餐:必须先点完餐,等菜做好,上菜,在此期间处理点餐的工人必须等待
后厨做菜:做菜就完事了
比如工人A 处理了点餐任务,接下来它要等着 工人B 把菜做好,然后上菜,他俩也配合的蛮好
但现在同时来了两个客人,这个时候工人A 和工人B 都去处理点餐了,这时没人做饭了,饥饿
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public class TestDeadLock { static final List<String> MENU = Arrays.asList("地三鲜" , "宫保鸡丁" , "辣子鸡丁" , "烤鸡翅" ); static Random RANDOM = new Random (); static String cooking () { return MENU.get(RANDOM.nextInt(MENU.size())); } public static void main (String[] args) { ExecutorService executorService = Executors.newFixedThreadPool(2 ); executorService.execute(() -> { log.debug("处理点餐..." ); Future<String> f = executorService.submit(() -> { log.debug("做菜" ); return cooking(); }); try { log.debug("上菜: {}" , f.get()); } catch (InterruptedException | ExecutionException e) { e.printStackTrace(); } }); executorService.execute(() -> { log.debug("处理点餐..." ); Future<String> f = executorService.submit(() -> { log.debug("做菜" ); return cooking(); }); try { log.debug("上菜: {}" , f.get()); } catch (InterruptedException | ExecutionException e) { e.printStackTrace(); } }); } }
输出
1 2 17:08:41.339 c.TestDeadLock [pool-1-thread-2] - 处理点餐... 17:08:41.339 c.TestDeadLock [pool-1-thread-1] - 处理点餐...
案例解析
饥饿的原因是工人即负责点餐任务又负责做菜任务,而且两个任务之间存在相互依赖关系,一旦所有工人都去处理了点餐任务,那么将发生永久没人工人处理做菜任务的饥饿现象,因为点餐任务依赖于做菜任务,做菜任务没有工人处理,那么点餐工人的任务也一直完成不了,无法释放点餐工人的生产力(点餐工人依赖于做菜工人是因为点餐工人等菜做完后还要上菜)
解决方案
可以增加线程池的大小,不过不是根本的解决方案,还是前面提到的,不同的任务类型,采用不同的线程池**(解除线程资源的相互依赖关系)**,例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 static final List<String> MENU = Arrays.asList("地三鲜" , "宫保鸡丁" , "辣子鸡丁" , "烤鸡翅" ); static Random RANDOM = new Random (); static String cooking () { return MENU.get(RANDOM.nextInt(MENU.size())); } public static void main (String[] args) { ExecutorService executorService1 = Executors.newFixedThreadPool(1 ); ExecutorService executorService2 = Executors.newFixedThreadPool(1 ); for (int i = 1 ; i <3 ; i++) { int j = i; executorService1.execute(() -> { log.debug("处理点餐" + j); }); } for (int i = 1 ; i < 3 ; i++) { int j = i; Future<String> future = executorService2.submit(()->{ log.debug("做菜" +j); return cooking(); }); executorService1.execute(()->{ try { String cook = future.get(); log.debug("上菜 {}..." ,cook); } catch (InterruptedException | ExecutionException e) { e.printStackTrace(); } }); } }
输出
1 2 3 4 5 6 21:37:13.696 [pool-2-thread-1] DEBUG com.czq.six.TestThreadHunger - 做菜1 21:37:13.696 [pool-1-thread-1] DEBUG com.czq.six.TestThreadHunger - 处理点餐1 21:37:13.698 [pool-2-thread-1] DEBUG com.czq.six.TestThreadHunger - 做菜2 21:37:13.698 [pool-1-thread-1] DEBUG com.czq.six.TestThreadHunger - 处理点餐2 21:37:13.698 [pool-1-thread-1] DEBUG com.czq.six.TestThreadHunger - 上菜 地三鲜... 21:37:13.699 [pool-1-thread-1] DEBUG com.czq.six.TestThreadHunger - 上菜 烤鸡翅...
创建多少线程池合适
过小会导致程序不能充分地利用系统资源、容易导致饥饿
过大会导致更多的线程上下文切换,占用更多内存
CPU 密集型运算
通常采用 cpu 核数 + 1 能够实现最优的 CPU 利用率,+1 是保证当线程由于页缺失故障(操作系统)或其它原因 导致暂停时,额外的这个线程就能顶上去,保证 CPU 时钟周期不被浪费
I/O 密集型运算
CPU 不总是处于繁忙状态,例如,当你执行业务计算时,这时候会使用 CPU 资源,但当你执行 I/O 操作时、远程 RPC 调用时,包括进行数据库操作时,这时候 CPU 就闲下来了,你可以利用多线程提高它的利用率。
经验公式如下
线程数 = 核数 * 期望 CPU 利用率 * 总时间(CPU计算时间+等待时间) / CPU 计算时间
例如 4 核 CPU 计算时间是 50% ,其它等待时间是 50%,期望 cpu 被 100% 利用,套用公式
4 * 100% * 100% / 50% = 8
例如 4 核 CPU 计算时间是 10% ,其它等待时间是 90%,期望 cpu 被 100% 利用,套用公式
4 * 100% * 100% / 10% = 40
计算公式的核心是将CPU的等待时间充分利用起来 ,比如4核CPU的计算时间是50%,如果是CPU计算时间是100%的话,此时四个线程就足矣让CPU没有空闲等待时间了,但他才50%,也就是四个线程他的利用才百分之50,所以需要使用另外四个线程填充CPU百分之50的空闲等待时间
任务调度线程池 在『任务调度线程池』功能加入之前(JDK1.3),可以使用 java.util.Timer 来实现定时功能,Timer 的优点在于简单易用,但由于所有任务都是由同一个线程来调度,因此所有任务都是串行执行的 ,同一时间只能有一个任务在执行,前一个 任务的延迟或异常都将会影响到之后的任务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 private static void method1 () { Timer timer = new Timer (); TimerTask task1 = new TimerTask () { @Override public void run () { log.debug("task 1" ); try { Thread.sleep(2000 ); } catch (InterruptedException e) { e.printStackTrace(); } } }; TimerTask task2 = new TimerTask () { @Override public void run () { log.debug("task 2" ); } }; timer.schedule(task1, 1000 ); timer.schedule(task2, 1000 ); }
输出
1 2 23:11:00.888 [Timer-0] DEBUG com.czq.six.TestTimer - task 1 23:11:02.902 [Timer-0] DEBUG com.czq.six.TestTimer - task 2
使用 ScheduledExecutorService 改写:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 private static void method2 (ScheduledExecutorService executorService) { executorService.submit(()->{ log.debug("task 1" ); try { Thread.sleep(2000 ); } catch (InterruptedException e) { e.printStackTrace(); } }); executorService.submit(()->{ log.debug("task 2" ); }); }
输出
1 2 23:11:43.801 [pool-1-thread-1] DEBUG com.czq.six.TestTimer - task 1 23:11:43.801 [pool-1-thread-2] DEBUG com.czq.six.TestTimer - task 2
scheduleAtFixedRate 例子:
1 2 3 4 5 6 7 8 9 10 11 12 ScheduledExecutorService executorService = Executors.newScheduledThreadPool(2 ); executorService.scheduleAtFixedRate(()->{ log.debug("1" ); try { Thread.sleep(2000 ); } catch (InterruptedException e) { e.printStackTrace(); } },1 ,1 , TimeUnit.SECONDS);
输出
1 2 3 4 5 23:12:10.449 [pool-1-thread-1] DEBUG com.czq.six.TestTimer - 1 23:12:12.456 [pool-1-thread-1] DEBUG com.czq.six.TestTimer - 1 23:12:14.472 [pool-1-thread-1] DEBUG com.czq.six.TestTimer - 1 23:12:16.483 [pool-1-thread-1] DEBUG com.czq.six.TestTimer - 1 23:12:18.487 [pool-1-thread-1] DEBUG com.czq.six.TestTimer - 1
scheduleWithFixedDelay 例子:
1 2 3 4 5 6 7 8 9 10 executorService.scheduleWithFixedDelay(()->{ log.debug("2" ); try { Thread.sleep(2000 ); } catch (InterruptedException e) { e.printStackTrace(); } },1 ,1 ,TimeUnit.SECONDS);
输出分析:scheduleWithFixedDelay 的间隔时间是 上一个任务执行时间+延时时间,所以下一个任务开始 所 以间隔都是 3s
1 2 3 4 23:13:54.518 [pool-1-thread-1] DEBUG com.czq.six.TestTimer - 2 23:13:57.540 [pool-1-thread-1] DEBUG com.czq.six.TestTimer - 2 23:14:00.560 [pool-1-thread-2] DEBUG com.czq.six.TestTimer - 2 23:14:03.570 [pool-1-thread-2] DEBUG com.czq.six.TestTimer - 2
定时任务的应用 如何让每周四 18:00:00 定时执行任务?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 LocalDateTime now = LocalDateTime.now();LocalDateTime thursday = now.with(DayOfWeek.THURSDAY).withHour(18 ).withMinute(0 ).withSecond(0 ).withNano(0 ); if (now.compareTo(thursday) >= 0 ) { thursday = thursday.plusWeeks(1 ); } long initialDelay = Duration.between(now, thursday).toMillis();long oneWeek = 7 * 24 * 3600 * 1000 ;ScheduledExecutorService executor = Executors.newScheduledThreadPool(2 );System.out.println("开始时间:" + new Date ()); executor.scheduleAtFixedRate(() -> { System.out.println("执行时间:" + new Date ()); }, initialDelay, oneWeek, TimeUnit.MILLISECONDS);
正确处理执行任务异常 不论是哪个线程池,在线程执行的任务发生异常后既不会抛出,也不会捕获,这时就需要我们做一定的处理。
方法1:主动捉异常
1 2 3 4 5 6 7 8 9 ExecutorService pool = Executors.newFixedThreadPool(1 );pool.submit(() -> { try { log.debug("task1" ); int i = 1 / 0 ; } catch (Exception e) { log.error("error:" , e); } });
输出
1 2 3 4 5 6 7 8 9 21:59:04.558 c.TestTimer [pool-1-thread-1] - task1 21:59:04.562 c.TestTimer [pool-1-thread-1] - error: java.lang.ArithmeticException: / by zero at cn.itcast.n8.TestTimer.lambda$main$0 (TestTimer.java:28) at java.util.concurrent.Executors$RunnableAdapter .call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker .run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)
方法2:使用 Future
说明:
lambda表达式内要有返回值,编译器才能将其识别为Callable,否则将识别为Runnable,也就不能用FutureTask
方法中如果出异常,futuretask.get会返回这个异常,否者正常返回。
1 2 3 4 5 6 7 ExecutorService pool = Executors.newFixedThreadPool(1 );Future<Boolean> f = pool.submit(() -> { log.debug("task1" ); int i = 1 / 0 ; return true ; }); log.debug("result:{}" , f.get());
输出
1 2 3 4 5 6 7 8 9 10 11 12 21:54:58.208 c.TestTimer [pool-1-thread-1] - task1 Exception in thread "main" java.util.concurrent.ExecutionException: java.lang.ArithmeticException: / by zero at java.util.concurrent.FutureTask.report(FutureTask.java:122) at java.util.concurrent.FutureTask.get(FutureTask.java:192) at cn.itcast.n8.TestTimer.main(TestTimer.java:31) Caused by: java.lang.ArithmeticException: / by zero at cn.itcast.n8.TestTimer.lambda$main$0 (TestTimer.java:28) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker .run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)
jdk提供的四种线程池实现总结 无论是那种线程池实现,本质都是调用底层线程池类的7个参数的构造方法,区别只是参数的值不一样,我们只要看核心参数的区别即可,核心参数有三个
核心线程数,最大线程数,任务队列,这三个参数透露出的本质是线程数要控制合理的范围内,任务数也要控制再合理的范围内,前者是因为线程资源宝贵和内存资源宝贵,后者是因为内存资源宝贵
1.FixedThreadPool和SingleThreadExecutor线程池的致命缺陷都是队列是无界的,也就是任务数是无限的,不仅导致没有非核心线程数,最大的问题是任务数堆积太多会导致内存溢出
2.CachedThreadPool和ScheduledThreadPoolExecutor的致命缺陷是最大线程数是Integer.MAX,几乎等同于线程无界,创建了无数了线程资源,线程资源如此宝贵,无休止的创建必然导致系统的崩溃以及内存的溢出
线程池详解的相关链接
新手也能看懂的线程池学习总结 (qq.com)
线程池最佳实践!安排! - 知乎 (zhihu.com)
如何设置线程池参数?美团给出了一个让面试官虎躯一震的回答。 (qq.com)
Java线程池实现原理及其在美团业务中的实践 - 美团技术团队 (meituan.com)
Tomcat 线程池 Tomcat 在哪里用到了线程池呢
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 graph LR subgraph Connector->NIO EndPoint t1(LimitLatch) t2(Acceptor) t3(SocketChannel 1) t4(SocketChannel 2) t5(Poller) subgraph Executor t7(worker1) t8(worker2) end t1 --> t2 t2 --> t3 t2 --> t4 t3 --有读--> t5 t4 --有读--> t5 t5 --socketProcessor--> t7 t5 --socketProcessor--> t8 end
LimitLatch 用来限流,可以控制最大连接个数,类似 J.U.C 中的 Semaphore 后面再讲
Acceptor 只负责【接收新的 socket 连接】
Poller 只负责监听 socket channel 是否有【可读的 I/O 事件】
一旦可读,封装一个任务对象(socketProcessor),提交给 Executor 线程池处理
Executor 线程池中的工作线程最终负责【处理请求】
Tomcat线程池充分体现了线程池的分工合作思想,每个线程池都是单一职责的处理某种类型的任务,Acceptor线程池专门用来处理建立连接的任务,Poller线程池专门用来监听通信信道是否有IO事件发生,Executor线程池专门用来处理请求任务,分工合作的思想有什么好处呢?
目前的答案是可以充分提高每一个岗位的生产效率,从而大大提高单位时间内处理任务的吞吐量,这个答案还有待深入学习探讨和完善
Tomcat 线程池扩展了 ThreadPoolExecutor,行为稍有不同
如果总线程数达到 maximumPoolSize
这时不会立刻抛 RejectedExecutionException 异常
而是再次尝试将任务放入队列,如果还失败,才抛出 RejectedExecutionException 异常
源码 tomcat-7.0.42
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public void execute (Runnable command, long timeout, TimeUnit unit) { submittedCount.incrementAndGet(); try { super .execute(command); } catch (RejectedExecutionException rx) { if (super .getQueue() instanceof TaskQueue) { final TaskQueue queue = (TaskQueue)super .getQueue(); try { if (!queue.force(command, timeout, unit)) { submittedCount.decrementAndGet(); throw new RejectedExecutionException ("Queue capacity is full." ); } } catch (InterruptedException x) { submittedCount.decrementAndGet(); Thread.interrupted(); throw new RejectedExecutionException (x); } } else { submittedCount.decrementAndGet(); throw rx; } } }
TaskQueue.java
1 2 3 4 5 6 7 8 public boolean force (Runnable o, long timeout, TimeUnit unit) throws InterruptedException { if ( parent.isShutdown() ) throw new RejectedExecutionException ( "Executor not running, can't force a command into the queue" ); return super .offer(o,timeout,unit); is rejected }
Connector 配置
配置项
默认值
说明
acceptorThreadCount 1
acceptor 线程数量
pollerThreadCount1
poller 线程数量
minSpareThreads10
核心线程数,即 corePoolSize
maxThreads200
最大线程数,即 maximumPoolSize
executor-
Executor 名称,用来引用下面的 Executor
Executor 线程配置
配置项
默认值
说明
threadPriority5
线程优先级
deamontrue
是否守护线程
minSpareThreads25
核心线程数,即corePoolSize
maxThreads200
最大线程数,即 maximumPoolSize
maxIdleTime60000
线程生存时间,单位是毫秒,默认值即 1 分钟
maxQueueSizeInteger.MAX_VALUE
队列长度
prestartminSpareThreadsfalse
核心线程是否在服务器启动时启动
Tomcat扩展Jdk线程池的点
1.Tomcat将线程池中的线程设置为了守护线程
2.Tomcat统计了实时运行的任务数,是通过任务数和核心线程数的比较来判断下一步的行为,而Jdk线程池是通过线程池中的活跃线程数和核心线程数比较的(存疑,实时运行的任务数和活跃线程数两种不同统计维度有什么差异?)
3.Tomcat线程池在活跃线程数超过核心线程数时,是先选择启用救急线程,直到线程数量达到最大线程数,才会选择将任务加入到阻塞队列中。而Jdk线程池是与之相反的,是先选择将任务加入到阻塞队列中,阻塞队列满了才会启用救急线程
Fork/Join 概念 Fork/Join 是 JDK 1.7 加入的新的线程池实现,它体现的是一种分治思想,适用于能够进行任务拆分的 cpu 密集型 运算
所谓的任务拆分,是将一个大任务拆分为算法上相同的小任务,直至不能拆分可以直接求解。跟递归相关的一些计 算,如归并排序、斐波那契数列、都可以用分治思想进行求解
Fork/Join 在分治的基础上加入了多线程,可以把每个任务的分解和合并交给不同的线程来完成,进一步提升了运 算效率
Fork/Join 默认会创建与 cpu 核心数大小相同的线程池
核心:
1.Fork/Join线程池是分治思想+多线程的综合应用线程池,分治思想负责将任务拆分成n个等价的小任务,每个任务分配一个线程去执行,使得原来任务的串行执行变成了并行执行,可以大大提高任务的执行效率
但需要注意的是拆分后的任务不能有前后依赖关系,否则即使任务的执行是并行,但任务互相等待彼此的执行结果仍旧是串行,那么总体的执行效率仍旧是串行,目前该线程池的致命缺陷就是要我们程序员手动去拆分成任务,如果任务拆分的不好,那就达不到并行执行任务的效果了
AQS 原理 概述 全称是 AbstractQueuedSynchronizer,是阻塞式锁和相关的同步器工具的框架
特点:
用 state 属性来表示资源的状态(分独占模式和共享模式),子类需要定义如何维护这个状态,控制如何获取 锁和释放锁
getState - 获取 state 状态
setState - 设置 state 状态
compareAndSetState - cas 机制设置 state 状态
独占模式是只有一个线程能够访问资源,而共享模式可以允许多个线程访问资源
提供了基于 FIFO 的等待队列,类似于 Monitor 的 EntryList
条件变量来实现等待、唤醒机制,支持多个条件变量,类似于 Monitor 的 WaitSet
子类主要实现这样一些方法(默认抛出 UnsupportedOperationException)
tryAcquire
tryRelease
tryAcquireShared
tryReleaseShared
isHeldExclusively
获取锁的姿势
1 2 3 4 if (!tryAcquire(arg)) { }
释放锁的姿势
1 2 3 4 if (tryRelease(arg)) { }
实现不可重入锁 自定义同步器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 final class MySync extends AbstractQueuedSynchronizer { @Override protected boolean tryAcquire (int acquires) { if (acquires == 1 ){ if (compareAndSetState(0 , 1 )) { setExclusiveOwnerThread(Thread.currentThread()); return true ; } } return false ; } @Override protected boolean tryRelease (int acquires) { if (acquires == 1 ) { if (getState() == 0 ) { throw new IllegalMonitorStateException (); } setExclusiveOwnerThread(null ); setState(0 ); return true ; } return false ; } protected Condition newCondition () { return new ConditionObject (); } @Override protected boolean isHeldExclusively () { return getState() == 1 ; } }
自定义锁 有了自定义同步器,很容易复用 AQS ,实现一个功能完备的自定义锁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class MyLock implements Lock { static MySync sync = new MySync (); @Override public void lock () { sync.acquire(1 ); } @Override public void lockInterruptibly () throws InterruptedException { sync.acquireInterruptibly(1 ); } @Override public boolean tryLock () { return sync.tryAcquire(1 ); } @Override public boolean tryLock (long time, TimeUnit unit) throws InterruptedException { return sync.tryAcquireNanos(1 , unit.toNanos(time)); } @Override public void unlock () { sync.release(1 ); } @Override public Condition newCondition () { return sync.newCondition(); } }
测试一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 MyLock lock = new MyLock ();new Thread (() -> { lock.lock(); try { log.debug("locking..." ); sleep(1 ); } finally { log.debug("unlocking..." ); lock.unlock(); } },"t1" ).start(); new Thread (() -> { lock.lock(); try { log.debug("locking..." ); } finally { log.debug("unlocking..." ); lock.unlock(); } },"t2" ).start();
输出
1 2 3 4 22:29:28.727 c.TestAqs [t1] - locking... 22:29:29.732 c.TestAqs [t1] - unlocking... 22:29:29.732 c.TestAqs [t2] - locking... 22:29:29.732 c.TestAqs [t2] - unlocking...
不可重入测试
如果改为下面代码,会发现自己也会被挡住(只会打印一次 locking)
1 2 3 4 lock.lock(); log.debug("locking..." ); lock.lock(); log.debug("locking..." );
心得 起源 早期程序员会自己通过一种同步器去实现另一种相近的同步器,例如用可重入锁去实现信号量,或反之。这显然不 够优雅,于是在 JSR166(java 规范提案)中创建了 AQS,提供了这种通用的同步器机制。
目标 AQS 要实现的功能目标
阻塞版本获取锁 acquire 和非阻塞的版本尝试获取锁 tryAcquire
获取锁超时机制
通过打断取消机制
独占机制及共享机制
条件不满足时的等待机制
要实现的性能目标
Instead, the primary performance goal here is scalability: to predictably maintain efficiency even, or especially, when synchronizers are contended.
设计 AQS 的基本思想其实很简单
获取锁的逻辑
1 2 3 4 5 6 while (state 状态不允许获取) { if (队列中还没有此线程) { 入队并阻塞 } } 当前线程出队
释放锁的逻辑
1 2 3 if (state 状态允许了) { 恢复阻塞的线程(s) }
要点
原子维护 state 状态
阻塞及恢复线程
维护队列
state 设计
state 使用 volatile 配合 cas 保证其修改时的原子性
state 使用了 32bit int 来维护同步状态,因为当时使用 long 在很多平台下测试的结果并不理想
阻塞恢复设计
早期的控制线程暂停和恢复的 api 有 suspend 和 resume,但它们是不可用的,因为如果先调用的 resume 那么 suspend 将感知不到
解决方法是使用 park & unpark 来实现线程的暂停和恢复,具体原理在之前讲过了,先 unpark 再 park 也没 问题
park & unpark 是针对线程的,而不是针对同步器的,因此控制粒度更为精细
park 线程还可以通过 interrupt 打断
队列设计
使用了 FIFO 先入先出队列,并不支持优先级队列
设计时借鉴了 CLH 队列,它是一种单向无锁队列
队列中有 head 和 tail 两个指针节点,都用 volatile 修饰配合 cas 使用,每个节点有 state 维护节点状态 入队伪代码,只需要考虑 tail 赋值的原子性
1 2 3 4 5 do { Node prev = tail; } while (tail.compareAndSet(prev, node))
出队伪代码
1 2 3 4 5 while ((Node prev=node.prev).state != 唤醒状态) {} head = node;
CLH 好处:
AQS 在一些方面改进了 CLH
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 private Node enq (final Node node) { for (;;) { Node t = tail; if (t == null ) { if (compareAndSetHead(new Node ())) tail = head; } else { node.prev = t; if (compareAndSetTail(t, node)) { t.next = node; return t; } } } }
主要用到 AQS 的并发工具类
关于AQS并发编程工具(框架)原理可以结合美团技术文章来理解,因为黑马视频中关于AQS的视频缺少了很多,可以不夸张的说Java层面的锁的思想和原理基本上都是依赖于AQS
从ReentrantLock的实现看AQS的原理及应用 - 美团技术团队 (meituan.com)
ReentrantLock 原理
非公平锁实现原理 加锁解锁流程 先从构造器开始看,默认为非公平锁实现
1 2 3 public ReentrantLock () { sync = new NonfairSync (); }
NonfairSync 继承自 AQS 没有竞争时
第一个竞争出现时
Thread-1 执行了
CAS 尝试将 state 由 0 改为 1,结果失败
进入 tryAcquire 逻辑,这时 state 已经是1,结果仍然失败
接下来进入 addWaiter 逻辑,构造 Node 队列
图中黄色三角表示该 Node 的 waitStatus 状态,其中 0 为默认正常状态
Node 的创建是懒惰的
其中第一个 Node 称为 Dummy(哑元)或哨兵,用来占位,并不关联线程
当前线程进入 acquireQueued 逻辑
acquireQueued 会在一个死循环中不断尝试获得锁,失败后进入 park 阻塞
如果自己是紧邻着 head(排第二位),那么再次 tryAcquire 尝试获取锁,当然这时 state 仍为 1,失败
进入 shouldParkAfterFailedAcquire 逻辑,将前驱 node,即 head 的 waitStatus 改为 -1,这次返回 false
shouldParkAfterFailedAcquire 执行完毕回到 acquireQueued ,再次 tryAcquire 尝试获取锁,当然这时 state 仍为 1,失败
当再次进入 shouldParkAfterFailedAcquire 时,这时因为其前驱 node 的 waitStatus 已经是 -1,这次返回 true
进入 parkAndCheckInterrupt, Thread-1 park(灰色表示)
再次有多个线程经历上述过程竞争失败,变成这个样子
Thread-0 释放锁,进入 tryRelease 流程,如果成功
设置 exclusiveOwnerThread 为 null
state = 0
当前队列不为 null,并且 head 的 waitStatus = -1,进入 unparkSuccessor 流程
找到队列中离 head 最近的一个 Node(没取消的),unpark 恢复其运行,本例中即为 Thread-1
回到 Thread-1 的 acquireQueued 流程
如果加锁成功(没有竞争),会设置
exclusiveOwnerThread 为 Thread-1,state = 1
head 指向刚刚 Thread-1 所在的 Node,该 Node 清空 Thread
原本的 head 因为从链表断开,而可被垃圾回收
如果这时候有其它线程来竞争(非公平的体现),例如这时有 Thread-4 来了
如果不巧又被 Thread-4 占了先
Thread-4 被设置为 exclusiveOwnerThread,state = 1
Thread-1 再次进入 acquireQueued 流程,获取锁失败,重新进入 park 阻塞
加锁源码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 static final class NonfairSync extends Sync { private static final long serialVersionUID = 7316153563782823691L ; final void lock () { if (compareAndSetState(0 , 1 )) setExclusiveOwnerThread(Thread.currentThread()); else acquire(1 ); } public final void acquire (int arg) { if ( !tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg) ) { selfInterrupt(); } } protected final boolean tryAcquire (int acquires) { return nonfairTryAcquire(acquires); } final boolean nonfairTryAcquire (int acquires) { final Thread current = Thread.currentThread(); int c = getState(); if (c == 0 ) { if (compareAndSetState(0 , acquires)) { setExclusiveOwnerThread(current); return true ; } } else if (current == getExclusiveOwnerThread()) { int nextc = c + acquires; if (nextc < 0 ) throw new Error ("Maximum lock count exceeded" ); setState(nextc); return true ; } return false ; } private Node addWaiter (Node mode) { Node node = new Node (Thread.currentThread(), mode); Node pred = tail; if (pred != null ) { node.prev = pred; if (compareAndSetTail(pred, node)) { pred.next = node; return node; } } enq(node); return node; } private Node enq (final Node node) { for (;;) { Node t = tail; if (t == null ) { if (compareAndSetHead(new Node ())) { tail = head; } } else { node.prev = t; if (compareAndSetTail(t, node)) { t.next = node; return t; } } } } final boolean acquireQueued (final Node node, int arg) { boolean failed = true ; try { boolean interrupted = false ; for (;;) { final Node p = node.predecessor(); if (p == head && tryAcquire(arg)) { setHead(node); p.next = null ; failed = false ; return interrupted; } if ( shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt() ) { interrupted = true ; } } } finally { if (failed) cancelAcquire(node); } } private static boolean shouldParkAfterFailedAcquire (Node pred, Node node) { int ws = pred.waitStatus; if (ws == Node.SIGNAL) { return true ; } if (ws > 0 ) { do { node.prev = pred = pred.prev; } while (pred.waitStatus > 0 ); pred.next = node; } else { compareAndSetWaitStatus(pred, ws, Node.SIGNAL); } return false ; } private final boolean parkAndCheckInterrupt () { LockSupport.park(this ); return Thread.interrupted(); } }
注意
是否需要 unpark 是由当前节点的前驱节点的 waitStatus == Node.SIGNAL 来决定,而不是本节点的 waitStatus 决定
总结:
调用lock,尝试将state从0修改为1
成功:将owner设为当前线程
失败:调用acquire->tryAcquire->nonfairTryAcquire,判断state=0则获得锁,或者state不为0但当前线程持有锁则重入锁,以上两种情况tryAcquire返回true,剩余情况返回false。
true:获得锁
false:调用acquireQueued(addWaiter(Node.EXCLUSIVE), arg),其中addwiter将关联线程的节点插入AQS队列尾部,进入acquireQueued中的for循环:
如果当前节点是头节点,并尝试获得锁成功,将当前节点设为头节点,清除此节点信息,返回打断标记。
调用shoudParkAfterFailure,第一次调用返回false,并将前驱节点改为-1,第二次循环如果再进入此方法,会进入阻塞并检查打断的方法。
加锁的核心过程:如果成功获取到锁则设置当前线程为锁的持有者,否则将当前线程加入到阻塞队列中并调用unpark方法阻塞当前线程
解锁源码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 static final class NonfairSync extends Sync { public void unlock () { sync.release(1 ); } public final boolean release (int arg) { if (tryRelease(arg)) { Node h = head; if ( h != null && h.waitStatus != 0 ) { unparkSuccessor(h); } return true ; } return false ; } protected final boolean tryRelease (int releases) { int c = getState() - releases; if (Thread.currentThread() != getExclusiveOwnerThread()) throw new IllegalMonitorStateException (); boolean free = false ; if (c == 0 ) { free = true ; setExclusiveOwnerThread(null ); } setState(c); return free; } private void unparkSuccessor (Node node) { int ws = node.waitStatus; if (ws < 0 ) { compareAndSetWaitStatus(node, ws, 0 ); } Node s = node.next; if (s == null || s.waitStatus > 0 ) { s = null ; for (Node t = tail; t != null && t != node; t = t.prev) if (t.waitStatus <= 0 ) s = t; } if (s != null ) LockSupport.unpark(s.thread); } }
总结:
unlock->syn.release(1)->tryRelease(1),如果当前线程并不持有锁,抛异常。state减去1,如果之后state为0,解锁成功,返回true;如果仍大于0,表示解锁不完全,当前线程依旧持有锁,返回false。返回true:检查AQS队列第一个节点状态图是否为SIGNAL(意味着有责任唤醒其后记节点),如果有,调用unparkSuccessor。
再unparkSuccessor中,不考虑已取消的节点, 从 AQS 队列从后至前找到队列最前面需要 unpark 的节点,如果有,将其唤醒。
返回false:
可重入原理 当持有锁的线程再次尝试获取锁时,会将state的值加1,state表示锁的重入量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 static final class NonfairSync extends Sync { final boolean nonfairTryAcquire (int acquires) { final Thread current = Thread.currentThread(); int c = getState(); if (c == 0 ) { if (compareAndSetState(0 , acquires)) { setExclusiveOwnerThread(current); return true ; } } else if (current == getExclusiveOwnerThread()) { int nextc = c + acquires; if (nextc < 0 ) throw new Error ("Maximum lock count exceeded" ); setState(nextc); return true ; } return false ; } protected final boolean tryRelease (int releases) { int c = getState() - releases; if (Thread.currentThread() != getExclusiveOwnerThread()) throw new IllegalMonitorStateException (); boolean free = false ; if (c == 0 ) { free = true ; setExclusiveOwnerThread(null ); } setState(c); return free; } }
可打断原理 不可打断模式
在此模式下,即使它被打断,仍会驻留在 AQS 队列中,并将打断信号存储在一个interrupt变量中。一直要等到获得锁后方能得知自己被打断了,并且调用selfInterrupt方法打断自己。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 static final class NonfairSync extends Sync { private final boolean parkAndCheckInterrupt () { LockSupport.park(this ); return Thread.interrupted(); } final boolean acquireQueued (final Node node, int arg) { boolean failed = true ; try { boolean interrupted = false ; for (;;) { final Node p = node.predecessor(); if (p == head && tryAcquire(arg)) { setHead(node); p.next = null ; failed = false ; return interrupted; } if ( shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt() ) { interrupted = true ; } } } finally { if (failed) cancelAcquire(node); } } public final void acquire (int arg) { if ( !tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg) ) { selfInterrupt(); } } static void selfInterrupt () { Thread.currentThread().interrupt(); } }
可打断模式
此模式下即使线程在等待队列中等待,一旦被打断,就会立刻抛出打断异常。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 static final class NonfairSync extends Sync { public final void acquireInterruptibly (int arg) throws InterruptedException { if (Thread.interrupted()) throw new InterruptedException (); if (!tryAcquire(arg)) doAcquireInterruptibly(arg); } private void doAcquireInterruptibly (int arg) throws InterruptedException { final Node node = addWaiter(Node.EXCLUSIVE); boolean failed = true ; try { for (;;) { final Node p = node.predecessor(); if (p == head && tryAcquire(arg)) { setHead(node); p.next = null ; failed = false ; return ; } if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) { throw new InterruptedException (); } } } finally { if (failed) cancelAcquire(node); } } }
公平锁实现原理 简而言之,公平与非公平的区别在于,公平锁中的tryAcquire方法被重写了,新来的线程即便得知了锁的state为0,也要先判断等待队列中是否还有线程等待,只有当队列没有线程等待式,才获得锁。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 static final class FairSync extends Sync { private static final long serialVersionUID = -3000897897090466540L ; final void lock () { acquire(1 ); } public final void acquire (int arg) { if ( !tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg) ) { selfInterrupt(); } } protected final boolean tryAcquire (int acquires) { final Thread current = Thread.currentThread(); int c = getState(); if (c == 0 ) { if (!hasQueuedPredecessors() && compareAndSetState(0 , acquires)) { setExclusiveOwnerThread(current); return true ; } } else if (current == getExclusiveOwnerThread()) { int nextc = c + acquires; if (nextc < 0 ) throw new Error ("Maximum lock count exceeded" ); setState(nextc); return true ; } return false ; } public final boolean hasQueuedPredecessors () { Node t = tail; Node h = head; Node s; return h != t && ( (s = h.next) == null || s.thread != Thread.currentThread() ); } }
我们发现在ReentrantLock虽然有公平锁和非公平锁两种,但是它们添加的都是独享锁 。根据源码所示,当某一个线程调用lock方法获取锁时,如果同步资源没有被其他线程锁住,那么当前线程在使用CAS更新state成功后就会成功抢占该资源。而如果公共资源被占用且不是被当前线程占用,那么就会加锁失败。所以可以确定ReentrantLock无论读操作还是写操作,添加的锁都是都是独享锁
条件变量实现原理 每个条件变量其实就对应着一个等待队列,其实现类是 ConditionObject
await 流程 开始 Thread-0 持有锁,调用 await,进入 ConditionObject 的 addConditionWaiter 流程
创建新的 Node 状态为 -2(Node.CONDITION),关联 Thread-0,加入等待队列尾部
接下来进入 AQS 的 fullyRelease 流程,释放同步器上的锁
unpark AQS 队列中的下一个节点,竞争锁,假设没有其他竞争线程,那么 Thread-1 竞争成功
park 阻塞 Thread-0
总结:
创建一个节点,关联当前线程,并插入到当前Condition队列的尾部
调用fullRelease,完全释放同步器中的锁,并记录当前线程的锁重入数
唤醒(park)AQS队列中的第一个线程
调用park方法,阻塞当前线程。
线程切换到等待状态的核心过程是将关联线程的节点加入到等待队列中,释放手中的锁资源并唤醒阻塞队列中的第一个线程,最后再阻塞当前线程
signal 流程 假设 Thread-1 要来唤醒 Thread-0
进入 ConditionObject 的 doSignal 流程,取得等待队列中第一个 Node,即 Thread-0 所在 Node
执行 transferForSignal 流程,将该 Node 加入 AQS 队列尾部,将 Thread-0 的 waitStatus 改为 0,Thread-3 的 waitStatus 改为 -1
Thread-1 释放锁,进入 unlock 流程,略
总结:
当前持有锁的线程唤醒等待队列中的线程,调用doSignal或doSignalAll方法,将等待队列中的第一个(或全部)节点插入到AQS队列中的尾部。
将插入的节点的状态从Condition设置为0,将插入节点的前一个节点的状态设置为-1(意味着要承担唤醒后一个节点的责任)
当前线程释放锁,parkAQS队列中的第一个节点线程。
唤醒的核心过程就是将等待队列的节点全部唤醒(等待队列置为空),再将节点一一加入到阻塞队列中
源码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 public class ConditionObject implements Condition , java.io.Serializable { private static final long serialVersionUID = 1173984872572414699L ; private transient Node firstWaiter; private transient Node lastWaiter; public ConditionObject () { } private Node addConditionWaiter () { Node t = lastWaiter; if (t != null && t.waitStatus != Node.CONDITION) { unlinkCancelledWaiters(); t = lastWaiter; } Node node = new Node (Thread.currentThread(), Node.CONDITION); if (t == null ) firstWaiter = node; else t.nextWaiter = node; lastWaiter = node; return node; } private void doSignal (Node first) { do { if ( (firstWaiter = first.nextWaiter) == null ) { lastWaiter = null ; } first.nextWaiter = null ; } while ( !transferForSignal(first) && (first = firstWaiter) != null ); } final boolean transferForSignal (Node node) { if (!compareAndSetWaitStatus(node, Node.CONDITION, 0 )) return false ; Node p = enq(node); int ws = p.waitStatus; if ( ws > 0 || !compareAndSetWaitStatus(p, ws, Node.SIGNAL) ) { LockSupport.unpark(node.thread); } return true ; } private void doSignalAll (Node first) { lastWaiter = firstWaiter = null ; do { Node next = first.nextWaiter; first.nextWaiter = null ; transferForSignal(first); first = next; } while (first != null ); } private void unlinkCancelledWaiters () { } public final void signal () { if (!isHeldExclusively()) throw new IllegalMonitorStateException (); Node first = firstWaiter; if (first != null ) doSignal(first); } public final void signalAll () { if (!isHeldExclusively()) throw new IllegalMonitorStateException (); Node first = firstWaiter; if (first != null ) doSignalAll(first); } public final void awaitUninterruptibly () { Node node = addConditionWaiter(); int savedState = fullyRelease(node); boolean interrupted = false ; while (!isOnSyncQueue(node)) { LockSupport.park(this ); if (Thread.interrupted()) interrupted = true ; } if (acquireQueued(node, savedState) || interrupted) selfInterrupt(); } private void doSignalAll (Node first) { lastWaiter = firstWaiter = null ; do { Node next = first.nextWaiter; first.nextWaiter = null ; transferForSignal(first); first = next; } while (first != null ); } private void unlinkCancelledWaiters () { } public final void signal () { if (!isHeldExclusively()) throw new IllegalMonitorStateException (); Node first = firstWaiter; if (first != null ) doSignal(first); } public final void signalAll () { if (!isHeldExclusively()) throw new IllegalMonitorStateException (); Node first = firstWaiter; if (first != null ) doSignalAll(first); } public final void awaitUninterruptibly () { Node node = addConditionWaiter(); int savedState = fullyRelease(node); boolean interrupted = false ; while (!isOnSyncQueue(node)) { LockSupport.park(this ); if (Thread.interrupted()) interrupted = true ; } if (acquireQueued(node, savedState) || interrupted) selfInterrupt(); } final int fullyRelease (Node node) { boolean failed = true ; try { int savedState = getState(); if (release(savedState)) { failed = false ; return savedState; } else { throw new IllegalMonitorStateException (); } } finally { if (failed) node.waitStatus = Node.CANCELLED; } } private static final int REINTERRUPT = 1 ; private static final int THROW_IE = -1 ; private int checkInterruptWhileWaiting (Node node) { return Thread.interrupted() ? (transferAfterCancelledWait(node) ? THROW_IE : REINTERRUPT) : 0 ; } private void reportInterruptAfterWait (int interruptMode) throws InterruptedException { if (interruptMode == THROW_IE) throw new InterruptedException (); else if (interruptMode == REINTERRUPT) selfInterrupt(); } public final void await () throws InterruptedException { if (Thread.interrupted()) { throw new InterruptedException (); } Node node = addConditionWaiter(); int savedState = fullyRelease(node); int interruptMode = 0 ; while (!isOnSyncQueue(node)) { LockSupport.park(this ); if ((interruptMode = checkInterruptWhileWaiting(node)) != 0 ) break ; } if (acquireQueued(node, savedState) && interruptMode != THROW_IE) interruptMode = REINTERRUPT; if (node.nextWaiter != null ) unlinkCancelledWaiters(); if (interruptMode != 0 ) reportInterruptAfterWait(interruptMode); } private Node addConditionWaiter () { Node t = lastWaiter; if (t != null && t.waitStatus != Node.CONDITION) { unlinkCancelledWaiters(); t = lastWaiter; } Node node = new Node (Thread.currentThread(), Node.CONDITION); if (t == null ) firstWaiter = node; else t.nextWaiter = node; lastWaiter = node; return node; } final boolean isOnSyncQueue (Node node) { if (node.waitStatus == Node.CONDITION || node.prev == null ) return false ; if (node.next != null ) return true ; return findNodeFromTail(node); } public final long awaitNanos (long nanosTimeout) throws InterruptedException { if (Thread.interrupted()) { throw new InterruptedException (); } Node node = addConditionWaiter(); int savedState = fullyRelease(node); final long deadline = System.nanoTime() + nanosTimeout; int interruptMode = 0 ; while (!isOnSyncQueue(node)) { if (nanosTimeout <= 0L ) { transferAfterCancelledWait(node); break ; } if (nanosTimeout >= spinForTimeoutThreshold) LockSupport.parkNanos(this , nanosTimeout); if ((interruptMode = checkInterruptWhileWaiting(node)) != 0 ) break ; nanosTimeout = deadline - System.nanoTime(); } if (acquireQueued(node, savedState) && interruptMode != THROW_IE) interruptMode = REINTERRUPT; if (node.nextWaiter != null ) unlinkCancelledWaiters(); if (interruptMode != 0 ) reportInterruptAfterWait(interruptMode); return deadline - System.nanoTime(); } public final boolean awaitUntil (Date deadline) throws InterruptedException { } public final boolean await (long time, TimeUnit unit) throws InterruptedException { } }
读写锁 ReentrantReadWriteLock 当读操作远远高于写操作时,这时候使用读写锁让读-读可以并发,提高性能。 类似于数据库中的select ... from ... lock in share mode
提供一个数据容器类内部分别使用读锁保护数据的 read() 方法,写锁保护数据的 write() 方法
测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class DataContainer { private Object data; private ReentrantReadWriteLock rw = new ReentrantReadWriteLock (); private ReentrantReadWriteLock.ReadLock r = rw.readLock(); private ReentrantReadWriteLock.WriteLock w = rw.writeLock(); public Object read () { log.debug("获取读锁..." ); r.lock(); try { log.debug("读取" ); sleep(1 ); return data; } finally { log.debug("释放读锁..." ); r.unlock(); } } public void write () { log.debug("获取写锁..." ); w.lock(); try { log.debug("写入" ); sleep(1 ); } finally { log.debug("释放写锁..." ); w.unlock(); } } }
测试读锁-读锁可以并发
1 2 3 4 5 6 7 DataContainer dataContainer = new DataContainer ();new Thread (() -> { dataContainer.read(); }, "t1" ).start(); new Thread (() -> { dataContainer.read(); }, "t2" ).start();
输出结果,从这里可以看到 Thread-0 锁定期间,Thread-1 的读操作不受影响
1 2 3 4 5 6 14:05:14.341 c.DataContainer [t2] - 获取读锁... 14:05:14.341 c.DataContainer [t1] - 获取读锁... 14:05:14.345 c.DataContainer [t1] - 读取 14:05:14.345 c.DataContainer [t2] - 读取 14:05:15.365 c.DataContainer [t2] - 释放读锁... 14:05:15.386 c.DataContainer [t1] - 释放读锁...
测试读锁-写锁相互阻塞
1 2 3 4 5 6 7 8 DataContainer dataContainer = new DataContainer ();new Thread (() -> { dataContainer.read(); }, "t1" ).start(); Thread.sleep(100 ); new Thread (() -> { dataContainer.write(); }, "t2" ).start();
输出结果
1 2 3 4 5 6 14 :04 :21.838 c.DataContainer [t1] - 获取读锁... 14 :04 :21.838 c.DataContainer [t2] - 获取写锁... 14 :04 :21.841 c.DataContainer [t2] - 写入14 :04 :22.843 c.DataContainer [t2] - 释放写锁... 14 :04 :22.843 c.DataContainer [t1] - 读取14 :04 :23.843 c.DataContainer [t1] - 释放读锁...
写锁-写锁也是相互阻塞的,这里就不测试了
注意事项
读锁不支持条件变量
重入时升级不支持:即持有读锁的情况下去获取写锁,会导致获取写锁永久等待
1 2 3 4 5 6 7 8 9 10 11 12 r.lock(); try { w.lock(); try { } finally { w.unlock(); } } finally { r.unlock(); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class CachedData { Object data; volatile boolean cacheValid; final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock (); void processCachedData () { rwl.readLock().lock(); if (!cacheValid) { rwl.readLock().unlock(); rwl.writeLock().lock(); try { if (!cacheValid) { data = ... cacheValid = true ; } rwl.readLock().lock(); } finally { rwl.writeLock().unlock(); } } try { use(data); } finally { rwl.readLock().unlock(); } } }
应用之缓存 缓存更新策略 更新时,是先清缓存还是先更新数据库
先清缓存
先更新数据库
补充一种情况,假设查询线程 A 查询数据时恰好缓存数据由于时间到期失效,或是第一次查询
这种情况的出现几率非常小,见 facebook 论文
总结
无论是那种缓存更新策略,都存在一定的问题,因为问题产生的原因是读写并发造成二者的指令交叉执行,要想真正保障缓存和持久层数据库的强一致性,只能通过加锁来实现 ,当然如果业务场景只要求弱一致性可以选择第二种更新策略
读写锁实现一致性缓存 使用读写锁实现一个简单的按需加载缓存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 class GenericCachedDao <T> { HashMap<SqlPair, T> map = new HashMap <>(); ReentrantReadWriteLock lock = new ReentrantReadWriteLock (); GenericDao genericDao = new GenericDao (); public int update (String sql, Object... params) { SqlPair key = new SqlPair (sql, params); lock.writeLock().lock(); try { int rows = genericDao.update(sql, params); map.clear(); return rows; } finally { lock.writeLock().unlock(); } } public T queryOne (Class<T> beanClass, String sql, Object... params) { SqlPair key = new SqlPair (sql, params); lock.readLock().lock(); try { T value = map.get(key); if (value != null ) { return value; } } finally { lock.readLock().unlock(); } lock.writeLock().lock(); try { T value = map.get(key); if (value == null ) { value = genericDao.queryOne(beanClass, sql, params); map.put(key, value); } return value; } finally { lock.writeLock().unlock(); } } class SqlPair { private String sql; private Object[] params; public SqlPair (String sql, Object[] params) { this .sql = sql; this .params = params; } @Override public boolean equals (Object o) { if (this == o) { return true ; } if (o == null || getClass() != o.getClass()) { return false ; } SqlPair sqlPair = (SqlPair) o; return sql.equals(sqlPair.sql) && Arrays.equals(params, sqlPair.params); } @Override public int hashCode () { int result = Objects.hash(sql); result = 31 * result + Arrays.hashCode(params); return result; } } }
注意
读写锁原理 图解流程 读写锁用的是同一个 Sycn 同步器,因此等待队列、state 等也是同一个
t1 w.lock,t2 r.lock
1) t1 成功上锁,流程与 ReentrantLock 加锁相比没有特殊之处,不同是写锁状态占了 state 的低 16 位,而读锁 使用的是 state 的高 16 位
2)t2 执行 r.lock,这时进入读锁的 sync.acquireShared(1) 流程,首先会进入 tryAcquireShared 流程。如果有写 锁占据,那么 tryAcquireShared 返回 -1 表示失败
tryAcquireShared 返回值表示
-1 表示失败
0 表示成功,但后继节点不会继续唤醒
正数表示成功,而且数值是还有几个后继节点需要唤醒,读写锁返回 1
3)这时会进入 sync.doAcquireShared(1) 流程,首先也是调用 addWaiter 添加节点,不同之处在于节点被设置为 Node.SHARED 模式而非 Node.EXCLUSIVE 模式,注意此时 t2 仍处于活跃状态
4)t2 会看看自己的节点是不是老二,如果是,还会再次调用 tryAcquireShared(1) 来尝试获取锁
5)如果没有成功,在 doAcquireShared 内 for (;;) 循环一次,把前驱节点的 waitStatus 改为 -1,再 for (;;) 循环一 次尝试 tryAcquireShared(1) 如果还不成功,那么在 parkAndCheckInterrupt() 处 park
t3 r.lock,t4 w.lock
这种状态下,假设又有 t3 加读锁和 t4 加写锁,这期间 t1 仍然持有锁,就变成了下面的样子
t1 w.unlock
这时会走到写锁的 sync.release(1) 流程,调用 sync.tryRelease(1) 成功,变成下面的样子
接下来执行唤醒流程 sync.unparkSuccessor,即让老二恢复运行,这时 t2 在 doAcquireShared 内 parkAndCheckInterrupt() 处恢复运行
这回再来一次 for (;;) 执行 tryAcquireShared 成功则让读锁计数加一
这时 t2 已经恢复运行,接下来 t2 调用 setHeadAndPropagate(node, 1),它原本所在节点被置为头节点
事情还没完,在 setHeadAndPropagate 方法内还会检查下一个节点是否是 shared,如果是则调用 doReleaseShared() 将 head 的状态从 -1 改为 0 并唤醒老二,这时 t3 在 doAcquireShared 内 parkAndCheckInterrupt() 处恢复运行
这回再来一次 for (;;) 执行 tryAcquireShared 成功则让读锁计数加一
这时 t3 已经恢复运行,接下来 t3 调用 setHeadAndPropagate(node, 1),它原本所在节点被置为头节点
下一个节点不是 shared 了,因此不会继续唤醒 t4 所在节点
t2 r.unlock,t3 r.unlock
t2 进入 sync.releaseShared(1) 中,调用 tryReleaseShared(1) 让计数减一,但由于计数还不为零
t3 进入 sync.releaseShared(1) 中,调用 tryReleaseShared(1) 让计数减一,这回计数为零了,进入 doReleaseShared() 将头节点从 -1 改为 0 并唤醒老二,即
之后 t4 在 acquireQueued 中 parkAndCheckInterrupt 处恢复运行,再次 for (;;) 这次自己是老二,并且没有其他 竞争,tryAcquire(1) 成功,修改头结点,流程结束
源码分析 写锁上锁流程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 static final class NonfairSync extends Sync { public void lock () { sync.acquire(1 ); } public final void acquire (int arg) { if ( !tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg) ) { selfInterrupt(); } } protected final boolean tryAcquire (int acquires) { Thread current = Thread.currentThread(); int c = getState(); int w = exclusiveCount(c); if (c != 0 ) { if ( w == 0 || current != getExclusiveOwnerThread() ) { return false ; } if (w + exclusiveCount(acquires) > MAX_COUNT) throw new Error ("Maximum lock count exceeded" ); setState(c + acquires); return true ; } if ( writerShouldBlock() || !compareAndSetState(c, c + acquires) ) { return false ; } setExclusiveOwnerThread(current); return true ; } final boolean writerShouldBlock () { return false ; } }
总结:
lock -> syn.acquire ->tryAquire
如果有锁:
如果是写锁或者锁持有者不为自己,返回false
如果时写锁且为自己持有,则重入
如果无锁:
判断无序阻塞并设置state成功后,将owner设为自己,返回true
成功,则获得了锁
失败:
调用acquireQueued(addWaiter(Node.EXCLUSIVE), arg)进入阻塞队列,将节点状态设置为EXCLUSIVE,之后的逻辑与之前的aquireQueued类似。
写锁释放流程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 static final class NonfairSync extends Sync { public void unlock () { sync.release(1 ); } public final boolean release (int arg) { if (tryRelease(arg)) { Node h = head; if (h != null && h.waitStatus != 0 ) unparkSuccessor(h); return true ; } return false ; } protected final boolean tryRelease (int releases) { if (!isHeldExclusively()) throw new IllegalMonitorStateException (); int nextc = getState() - releases; boolean free = exclusiveCount(nextc) == 0 ; if (free) { setExclusiveOwnerThread(null ); } setState(nextc); return free; } }
总结:
读锁上锁流程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 static final class NonfairSync extends Sync { public void lock () { sync.acquireShared(1 ); } public final void acquireShared (int arg) { if (tryAcquireShared(arg) < 0 ) { doAcquireShared(arg); } } protected final int tryAcquireShared (int unused) { Thread current = Thread.currentThread(); int c = getState(); if ( exclusiveCount(c) != 0 && getExclusiveOwnerThread() != current ) { return -1 ; } int r = sharedCount(c); if ( !readerShouldBlock() && r < MAX_COUNT && compareAndSetState(c, c + SHARED_UNIT) ) { return 1 ; } return fullTryAcquireShared(current); } final boolean readerShouldBlock () { return apparentlyFirstQueuedIsExclusive(); } final int fullTryAcquireShared (Thread current) { HoldCounter rh = null ; for (;;) { int c = getState(); if (exclusiveCount(c) != 0 ) { if (getExclusiveOwnerThread() != current) return -1 ; } else if (readerShouldBlock()) { } if (sharedCount(c) == MAX_COUNT) throw new Error ("Maximum lock count exceeded" ); if (compareAndSetState(c, c + SHARED_UNIT)) { return 1 ; } } } private void doAcquireShared (int arg) { final Node node = addWaiter(Node.SHARED); boolean failed = true ; try { boolean interrupted = false ; for (;;) { final Node p = node.predecessor(); if (p == head) { int r = tryAcquireShared(arg); if (r >= 0 ) { setHeadAndPropagate(node, r); p.next = null ; if (interrupted) selfInterrupt(); failed = false ; return ; } } if ( shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt() ) { interrupted = true ; } } } finally { if (failed) cancelAcquire(node); } } private void setHeadAndPropagate (Node node, int propagate) { Node h = head; setHead(node); if (propagate > 0 || h == null || h.waitStatus < 0 || (h = head) == null || h.waitStatus < 0 ) { Node s = node.next; if (s == null || s.isShared()) { doReleaseShared(); } } } private void doReleaseShared () { for (;;) { Node h = head; if (h != null && h != tail) { int ws = h.waitStatus; if (ws == Node.SIGNAL) { if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0 )) continue ; unparkSuccessor(h); } else if (ws == 0 && !compareAndSetWaitStatus(h, 0 , Node.PROPAGATE)) continue ; } if (h == head) break ; } } }
总结:
lock->syn.acquireShare->tryAcquireShare
如果其他线程持有写锁:则失败,返回-1
否则:判断无需等待后,将state加上一个写锁的单位,返回1
返回值大于等于0:成功
返回值小于0:
调用doAcquireShare,类似之前的aquireQueued,将当前线程关联节点,状态设置为SHARE,插入AQS队列尾部。在for循环中判断当前节点的前驱节点是否为头节点
是:调用tryAcquireShare
如果返回值大于等于0,则获取锁成功,并调用setHeadAndPropagate,出队,并不断唤醒AQS队列中的状态为SHARE的节点,直到下一个节点为EXCLUSIVE。 记录打断标记,之后退出方法(不返回打断标记)
判断是否在失败后阻塞
是:阻塞住,并监测打断信号。
否则:将前驱节点状态设为-1。(下一次循环就又要阻塞了)
读锁释放流程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 static final class NonfairSync extends Sync { public void unlock () { sync.releaseShared(1 ); } public final boolean releaseShared (int arg) { if (tryReleaseShared(arg)) { doReleaseShared(); return true ; } return false ; } protected final boolean tryReleaseShared (int unused) { for (;;) { int c = getState(); int nextc = c - SHARED_UNIT; if (compareAndSetState(c, nextc)) { return nextc == 0 ; } } } private void doReleaseShared () { for (;;) { Node h = head; if (h != null && h != tail) { int ws = h.waitStatus; if (ws == Node.SIGNAL) { if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0 )) continue ; unparkSuccessor(h); } else if (ws == 0 && !compareAndSetWaitStatus(h, 0 , Node.PROPAGATE)) continue ; } if (h == head) break ; } } }
总结:
unlock->releaseShared->tryReleaseShared,将state减去一个share单元,最后state为0则返回true,不然返回false。返回tue:调用doReleaseShare,唤醒队列中的节点。
返回false:解锁不完全。
细节:
1.无论是ReentrantLock还是读写锁ReentrantReadWriteLock,他们都是悲观锁,都是在操作共享资源前要先加锁,保证操作的数据不会被其他线程修改
2**.CAS算法只是保证比较并交换这两个操作是原子性的,并不能用有无CAS操作来辨别解决线程安全问题究竟是使用无锁实现还是有锁实现**,比如利用CAS的思想实现乐观锁(无锁实现)和ReentrantLock是利用CAS算法修改共享资源state状态来进行加锁和解锁(有锁实现)。AQS中大量的操作共享资源的操作都是用了CAS算法保证操作的原子性,但里面大多数是有锁实现
核心总结:
1**.ReentrantLock锁底层是AQS原理实现的,他是在Java层面实现的重量级锁,和C++层面实现的监听器Monitor锁(synchronized)的设计思想非常类似,在学习ReentrantLock的设计思想和源码时,二者可以类比学习**,只是ReentrantLock锁实现的更灵活更丰富
从ReentrantLock的实现看AQS的原理及应用 - 美团技术团队 (meituan.com)
2**.在阅读ReentrantLock锁原理笔记时最好是结合流程图+流程解析+源码的方式去学习和理解,这样会更清晰,黑马的笔记缺乏流程图,但有流程解析和源码,我们可以结合美团大佬的技术博客去更好的学习这部分内容**
从ReentrantLock的实现看AQS的原理及应用 - 美团技术团队 (meituan.com)
3.读写锁ReentrantReadWrite中的写锁和ReentrantLock实现的原理基本一致,有区别的是读锁的实现,在阅读源码时要重点去区分和理解读锁(共享锁)加锁和释放锁的原理,同样阅读读写锁源码时最好结合流程图+流程图解析+源码解析的方式去学习,这样会更好的理解,下面是腾讯大佬的技术博客(有流程图)
读写锁——ReentrantReadWriteLock原理详解 - 腾讯云开发者社区-腾讯云 (tencent.com)
4.美团技术团队关于Java锁的深度的解析,可以借此更深入学习和理解Java锁的相关知识
【基本功】不可不说的Java“锁”事 (qq.com)
StampedLock 该类自 JDK 8 加入,是为了进一步优化读性能,它的特点是在使用读锁、写锁时都必须配合【戳】使用 加解读锁
1 2 long stamp = lock.readLock();lock.unlockRead(stamp);
加解写锁
1 2 long stamp = lock.writeLock();lock.unlockWrite(stamp);
乐观读,StampedLock 支持 tryOptimisticRead() 方法(乐观读),读取完毕后需要做一次 戳校验 如果校验通 过,表示这期间确实没有写操作,数据可以安全使用,如果校验没通过,需要重新获取读锁,保证数据安全。
1 2 3 4 5 long stamp = lock.tryOptimisticRead();if (!lock.validate(stamp)){ }
提供一个数据容器类内部分别使用读锁保护数据的read()方法,写锁保护数据的write()方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 class DataContainerStamped { private int data; private final StampedLock lock = new StampedLock (); public DataContainerStamped (int data) { this .data = data; } public int read (int readTime) { long stamp = lock.tryOptimisticRead(); log.debug("optimistic read locking...{}" , stamp); sleep(readTime); if (lock.validate(stamp)) { log.debug("read finish...{}, data:{}" , stamp, data); return data; } log.debug("updating to read lock... {}" , stamp); try { stamp = lock.readLock(); log.debug("read lock {}" , stamp); sleep(readTime); log.debug("read finish...{}, data:{}" , stamp, data); return data; } finally { log.debug("read unlock {}" , stamp); lock.unlockRead(stamp); } } public void write (int newData) { long stamp = lock.writeLock(); log.debug("write lock {}" , stamp); try { sleep(2 ); this .data = newData; } finally { log.debug("write unlock {}" , stamp); lock.unlockWrite(stamp); } } }
测试读-读可以优化
1 2 3 4 5 6 7 8 9 10 public static void main (String[] args) { DataContainerStamped dataContainer = new DataContainerStamped (1 ); new Thread (() -> { dataContainer.read(1 ); }, "t1" ).start(); sleep(0.5 ); new Thread (() -> { dataContainer.read(0 ); }, "t2" ).start(); }
输出结果,可以看到实际没有加读锁
1 2 3 4 15:58:50.217 c.DataContainerStamped [t1] - optimistic read locking...256 15:58:50.717 c.DataContainerStamped [t2] - optimistic read locking...256 15:58:50.717 c.DataContainerStamped [t2] - read finish...256, data:1 15:58:51.220 c.DataContainerStamped [t1] - read finish...256, data:1
测试读-写时优化读补加读锁
1 2 3 4 5 6 7 8 9 10 public static void main (String[] args) { DataContainerStamped dataContainer = new DataContainerStamped (1 ); new Thread (() -> { dataContainer.read(1 ); }, "t1" ).start(); sleep(0.5 ); new Thread (() -> { dataContainer.write(100 ); }, "t2" ).start(); }
输出结果
1 2 3 4 5 6 7 15:57:00.219 c.DataContainerStamped [t1] - optimistic read locking...256 15:57:00.717 c.DataContainerStamped [t2] - write lock 384 15:57:01.225 c.DataContainerStamped [t1] - updating to read lock... 256 15:57:02.719 c.DataContainerStamped [t2] - write unlock 384 15:57:02.719 c.DataContainerStamped [t1] - read lock 513 15:57:03.719 c.DataContainerStamped [t1] - read finish...513, data:1000 15:57:03.719 c.DataContainerStamped [t1] - read unlock 513
注意
StampedLock 不支持条件变量
StampedLock 不支持可重入
核心思想
StampedLock优化读写锁中读锁的核心思想是将原来读写锁中的读锁从悲观锁变成乐观锁,因为读写锁加锁的原理是CAS操作修改state同步资源字段,每次加锁都要执行CAS操作修改state字段,非常耗费资源,所以优化的思路就是乐观锁思路,先不加锁(自然就不用执行CAS操作了),等到出现其他线程修改共享数据时再升级为读锁(再加锁)
Semaphore 基本使用 [ˈsɛməˌfɔr] 信号量,用来限制能同时访问共享资源的线程上限。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public static void main (String[] args) { Semaphore semaphore = new Semaphore (3 ); for (int i = 0 ; i < 10 ; i++) { new Thread (() -> { try { semaphore.acquire(); } catch (InterruptedException e) { e.printStackTrace(); } try { log.debug("running..." ); sleep(1 ); log.debug("end..." ); } finally { semaphore.release(); } }).start(); } }
输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 07:35:15.485 c.TestSemaphore [Thread-2] - running... 07:35:15.485 c.TestSemaphore [Thread-1] - running... 07:35:15.485 c.TestSemaphore [Thread-0] - running... 07:35:16.490 c.TestSemaphore [Thread-2] - end... 07:35:16.490 c.TestSemaphore [Thread-0] - end... 07:35:16.490 c.TestSemaphore [Thread-1] - end... 07:35:16.490 c.TestSemaphore [Thread-3] - running... 07:35:16.490 c.TestSemaphore [Thread-5] - running... 07:35:16.490 c.TestSemaphore [Thread-4] - running... 07:35:17.490 c.TestSemaphore [Thread-5] - end... 07:35:17.490 c.TestSemaphore [Thread-4] - end... 07:35:17.490 c.TestSemaphore [Thread-3] - end... 07:35:17.490 c.TestSemaphore [Thread-6] - running... 07:35:17.490 c.TestSemaphore [Thread-7] - running... 07:35:17.490 c.TestSemaphore [Thread-9] - running... 07:35:18.491 c.TestSemaphore [Thread-6] - end... 07:35:18.491 c.TestSemaphore [Thread-7] - end... 07:35:18.491 c.TestSemaphore [Thread-9] - end... 07:35:18.491 c.TestSemaphore [Thread-8] - running... 07:35:19.492 c.TestSemaphore [Thread-8] - end...
说明:
Semaphore有两个构造器:Semaphore(int permits)和Semaphore(int permits,boolean fair)
permits表示允许同时访问共享资源的线程数。
fair表示公平与否,与之前的ReentrantLock一样。
线程不是有序打印正是非公平锁的体现
Semaphore 应用 semaphore 限制对共享资源的使用
使用 Semaphore 限流,在访问高峰期时,让请求线程阻塞,高峰期过去再释放许可,**当然它只适合限制单机 线程数量,并且仅是限制线程数,而不是限制资源数(线程数和资源数的差异?)**(例如连接数,请对比 Tomcat LimitLatch 的实现)
用 Semaphore 实现简单连接池,对比『享元模式』下的实现(用wait notify),性能和可读性显然更好, 注意下面的实现中线程数和数据库连接数是相等的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 @Slf4j(topic = "c.Pool") class Pool { private final int poolSize; private Connection[] connections; private AtomicIntegerArray states; private Semaphore semaphore; public Pool (int poolSize) { this .poolSize = poolSize; this .semaphore = new Semaphore (poolSize); this .connections = new Connection [poolSize]; this .states = new AtomicIntegerArray (new int [poolSize]); for (int i = 0 ; i < poolSize; i++) { connections[i] = new MockConnection ("连接" + (i+1 )); } } public Connection borrow () { try { semaphore.acquire(); } catch (InterruptedException e) { e.printStackTrace(); } for (int i = 0 ; i < poolSize; i++) { if (states.get(i) == 0 ) { if (states.compareAndSet(i, 0 , 1 )) { log.debug("borrow {}" , connections[i]); return connections[i]; } } } return null ; } public void free (Connection conn) { for (int i = 0 ; i < poolSize; i++) { if (connections[i] == conn) { states.set(i, 0 ); log.debug("free {}" , conn); semaphore.release(); break ; } } } }
Semaphore 原理 加锁解锁流程 Semaphore有点像一个停车场,permits就好像停车位数量,当线程获得了permits就像是获得了停车位,然后停车场显示空余车位减一。
源码分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 static final class NonfairSync extends Sync { private static final long serialVersionUID = -2694183684443567898L ; NonfairSync(int permits ) { super (permits ); } public void acquire () throws InterruptedException { sync.acquireSharedInterruptibly(1 ); } public final void acquireSharedInterruptibly (int arg) throws InterruptedException { if (Thread.interrupted()) throw new InterruptedException (); if (tryAcquireShared(arg) < 0 ) doAcquireSharedInterruptibly(arg); } protected int tryAcquireShared (int acquires) { return nonfairTryAcquireShared(acquires); } final int nonfairTryAcquireShared (int acquires) { for (;;) { int available = getState(); int remaining = available - acquires; if ( remaining < 0 || compareAndSetState(available, remaining) ) { return remaining; } } } private void doAcquireSharedInterruptibly (int arg) throws InterruptedException { final Node node = addWaiter(Node.SHARED); boolean failed = true ; try { for (;;) { final Node p = node.predecessor(); if (p == head) { int r = tryAcquireShared(arg); if (r >= 0 ) { setHeadAndPropagate(node, r); p.next = null ; failed = false ; return ; } } if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) throw new InterruptedException (); } } finally { if (failed) cancelAcquire(node); } } public void release () { sync.releaseShared(1 ); } public final boolean releaseShared (int arg) { if (tryReleaseShared(arg)) { doReleaseShared(); return true ; } return false ; } protected final boolean tryReleaseShared (int releases) { for (;;) { int current = getState(); int next = current + releases; if (next < current) throw new Error ("Maximum permit count exceeded" ); if (compareAndSetState(current, next)) return true ; } } } private void setHeadAndPropagate (Node node, int propagate) { Node h = head; setHead(node); if (propagate > 0 || h == null || h.waitStatus < 0 || (h = head) == null || h.waitStatus < 0 ) { Node s = node.next; if (s == null || s.isShared()) { doReleaseShared(); } } } private void doReleaseShared () { for (;;) { Node h = head; if (h != null && h != tail) { int ws = h.waitStatus; if (ws == Node.SIGNAL) { if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0 )) continue ; unparkSuccessor(h); } else if (ws == 0 && !compareAndSetWaitStatus(h, 0 , Node.PROPAGATE)) continue ; } if (h == head) break ; } }
加锁流程总结:
acquire->acquireSharedInterruptibly(1)->tryAcquireShared(1)->nonfairTryAcquireShared(1),如果资源用完了,返回负数,tryAcquireShared返回负数,表示失败。否则返回正数,tryAcquireShared返回正数,表示成功。
如果成功,获取信号量成功。
如果失败,调用doAcquireSharedInterruptibly,进入for循环:
如果当前驱节点为头节点,调用tryAcquireShared尝试获取锁
如果结果大于等于0,表明获取锁成功,调用setHeadAndPropagate,将当前节点设为头节点,之后又调用doReleaseShared,唤醒后继节点。
调用shoudParkAfterFailure,第一次调用返回false,并将前驱节点改为-1,第二次循环如果再进入此方法,会进入阻塞并检查打断的方法。
解锁流程总结:
release->sync.releaseShared(1)->tryReleaseShared(1),只要不发生整数溢出,就返回true
如果返回true,调用doReleaseShared,唤醒后继节点。
如果返回false,解锁失败。
Semaphore的原理和读写锁中的读锁(共享锁)原理基本一致,只是共享锁是不限制共享的线程个数,而Semaphore锁是限制共享线程的个数,如果想更细致的研究源码可以直接去阅读读写锁中读锁的源码
CountdownLatch 用来进行线程同步协作,等待所有线程完成倒计时,和join,wait作用类似,但是CountdownLatch是上层api,应用起来更简单和更方便
其中构造参数用来初始化等待计数值,await() 用来等待计数归零,countDown() 用来让计数减一
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public static void main (String[] args) throws InterruptedException { CountDownLatch latch = new CountDownLatch (3 ); new Thread (() -> { log.debug("begin..." ); sleep(1 ); latch.countDown(); log.debug("end...{}" , latch.getCount()); }).start(); new Thread (() -> { log.debug("begin..." ); sleep(2 ); latch.countDown(); log.debug("end...{}" , latch.getCount()); }).start(); new Thread (() -> { log.debug("begin..." ); sleep(1.5 ); latch.countDown(); log.debug("end...{}" , latch.getCount()); }).start(); log.debug("waiting..." ); latch.await(); log.debug("wait end..." ); }
输出
1 2 3 4 5 6 7 8 18:44:00.778 c.TestCountDownLatch [main] - waiting... 18:44:00.778 c.TestCountDownLatch [Thread-2] - begin... 18:44:00.778 c.TestCountDownLatch [Thread-0] - begin... 18:44:00.778 c.TestCountDownLatch [Thread-1] - begin... 18:44:01.782 c.TestCountDownLatch [Thread-0] - end...2 18:44:02.283 c.TestCountDownLatch [Thread-2] - end...1 18:44:02.782 c.TestCountDownLatch [Thread-1] - end...0 18:44:02.782 c.TestCountDownLatch [main] - wait end...
相比于join,CountDownLatch能配合线程池使用 ,因为线程池中的核心线程是不会主动停止运行的,而join方法是要等待目的线程停止运行才会唤醒当前线程的,所以不能配合线程池使用,如果使用wait虽然也可以实现,但是wait实现起来较为复杂,不建议使用底层api自己实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public static void main (String[] args) throws InterruptedException { CountDownLatch latch = new CountDownLatch (3 ); ExecutorService service = Executors.newFixedThreadPool(4 ); service.submit(() -> { log.debug("begin..." ); sleep(1 ); latch.countDown(); log.debug("end...{}" , latch.getCount()); }); service.submit(() -> { log.debug("begin..." ); sleep(1.5 ); latch.countDown(); log.debug("end...{}" , latch.getCount()); }); service.submit(() -> { log.debug("begin..." ); sleep(2 ); latch.countDown(); log.debug("end...{}" , latch.getCount()); }); service.submit(()->{ try { log.debug("waiting..." ); latch.await(); log.debug("wait end..." ); } catch (InterruptedException e) { e.printStackTrace(); } }); }
应用之同步等待多线程准备完毕 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 AtomicInteger num = new AtomicInteger (0 );ExecutorService service = Executors.newFixedThreadPool(10 , (r) -> { return new Thread (r, "t" + num.getAndIncrement()); }); CountDownLatch latch = new CountDownLatch (10 );String[] all = new String [10 ]; Random r = new Random ();for (int j = 0 ; j < 10 ; j++) { int x = j; service.submit(() -> { for (int i = 0 ; i <= 100 ; i++) { try { Thread.sleep(r.nextInt(100 )); } catch (InterruptedException e) { } all[x] = Thread.currentThread().getName() + "(" + (i + "%" ) + ")" ; System.out.print("\r" + Arrays.toString(all)); } latch.countDown(); }); } latch.await(); System.out.println("\n游戏开始..." ); service.shutdown();
中间输出
1 [t0(52%), t1(47%), t2(51%), t3(40%), t4(49%), t5(44%), t6(49%), t7(52%), t8(46%), t9(46%)]
最后输出
1 2 3 [t0(100%), t1(100%), t2(100%), t3(100%), t4(100%), t5(100%), t6(100%), t7(100%), t8(100%), t9(100%)] 游戏开始...
应用之同步等待多个远程调用结束 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 @RestController public class TestCountDownlatchController { @GetMapping("/order/{id}") public Map<String, Object> order (@PathVariable int id) { HashMap<String, Object> map = new HashMap <>(); map.put("id" , id); map.put("total" , "2300.00" ); sleep(2000 ); return map; } @GetMapping("/product/{id}") public Map<String, Object> product (@PathVariable int id) { HashMap<String, Object> map = new HashMap <>(); if (id == 1 ) { map.put("name" , "小爱音箱" ); map.put("price" , 300 ); } else if (id == 2 ) { map.put("name" , "小米手机" ); map.put("price" , 2000 ); } map.put("id" , id); sleep(1000 ); return map; } @GetMapping("/logistics/{id}") public Map<String, Object> logistics (@PathVariable int id) { HashMap<String, Object> map = new HashMap <>(); map.put("id" , id); map.put("name" , "中通快递" ); sleep(2500 ); return map; } private void sleep (int millis) { try { Thread.sleep(millis); } catch (InterruptedException e) { e.printStackTrace(); } } }
rest远程调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 RestTemplate restTemplate = new RestTemplate ();log.debug("begin" ); ExecutorService service = Executors.newCachedThreadPool();CountDownLatch latch = new CountDownLatch (4 );Future<Map<String,Object>> f1 = service.submit(() -> { Map<String, Object> r = restTemplate.getForObject("http://localhost:8080/order/{1}" , Map.class, 1 ); return r; }); Future<Map<String, Object>> f2 = service.submit(() -> { Map<String, Object> r = restTemplate.getForObject("http://localhost:8080/product/{1}" , Map.class, 1 ); return r; }); Future<Map<String, Object>> f3 = service.submit(() -> { Map<String, Object> r = restTemplate.getForObject("http://localhost:8080/product/{1}" , Map.class, 2 ); return r; }); Future<Map<String, Object>> f4 = service.submit(() -> { Map<String, Object> r = restTemplate.getForObject("http://localhost:8080/logistics/{1}" , Map.class, 1 ); return r; }); System.out.println(f1.get()); System.out.println(f2.get()); System.out.println(f3.get()); System.out.println(f4.get()); log.debug("执行完毕" ); service.shutdown();
执行结果
1 2 3 4 5 6 19:51:39.711 c.TestCountDownLatch [main] - begin {total=2300.00, id =1} {price=300, name=小爱音箱, id =1} {price=2000, name=小米手机, id =2} {name=中通快递, id =1} 19:51:42.407 c.TestCountDownLatch [main] - 执行完毕
说明:
这种等待多个带有返回值的任务的场景,还是用future比较合适,CountdownLatch适合任务没有返回值的场景。 CountdownLatch有两个缺点,一是不能得到线程的执行结果(Future可以改进),而是不能重用(CyclicBarrier可以实现)
CyclicBarrier CountdownLatch的缺点在于不能重用,见下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 private static void test1 () { ExecutorService service = Executors.newFixedThreadPool(5 ); for (int i = 0 ; i < 3 ; i++) { CountDownLatch latch = new CountDownLatch (2 ); service.submit(() -> { log.debug("task1 start..." ); sleep(1 ); latch.countDown(); }); service.submit(() -> { log.debug("task2 start..." ); sleep(2 ); latch.countDown(); }); try { latch.await(); } catch (InterruptedException e) { e.printStackTrace(); } log.debug("task1 task2 finish..." ); } service.shutdown(); }
想要重复使用CountdownLatch进行同步,必须创建多个CountDownLatch对象。
[ˈsaɪklɪk ˈbæriɚ] 循环栅栏,用来进行线程协作,等待线程满足某个计数。构造时设置『计数个数』,每个线程执 行到某个需要“同步”的时刻调用 await() 方法进行等待,当等待的线程数满足『计数个数』时,继续执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 CyclicBarrier cb = new CyclicBarrier (2 ); new Thread (()->{ System.out.println("线程1开始.." +new Date ()); try { cb.await(); } catch (InterruptedException | BrokenBarrierException e) { e.printStackTrace(); } System.out.println("线程1继续向下运行..." +new Date ()); }).start(); new Thread (()->{ System.out.println("线程2开始.." +new Date ()); try { Thread.sleep(2000 ); } catch (InterruptedException e) { } try { cb.await(); } catch (InterruptedException | BrokenBarrierException e) { e.printStackTrace(); } System.out.println("线程2继续向下运行..." +new Date ()); }).start();
注意
CyclicBarrier 与 CountDownLatch 的主要区别在于 CyclicBarrier 是可以重用的 CyclicBarrier 可以被比 喻为『人满发车』
CountDownLatch的计数和阻塞方法是分开的两个方法,而CyclicBarrier是一个方法。
CyclicBarrier的构造器还有一个Runnable类型的参数,在计数为0时会执行其中的run方法。
以上的同步器组件都有其对应的应用场景,底层的原理都是基于AQS,在AQS的基础上根据自己应用场景进行拓展的,以下简单罗列以下这些同步器组件的应用场景
1.ReentrantLock,属于重量级锁,想要使用重量级锁保障操作的原子性话的可以使用
2.ReentrantReadWriteLock读写锁,同样属于重量级锁,只是将读写分离了,提高读读并发的性能,适用于读多写少的场景
3.StampedLock,属于读写锁特定场景的优化版,优化了读写锁中的读锁,将读写锁中的读锁从悲观锁改为了乐观锁(无锁实现)实现,进一步提高读读并发的性能,同样适用于读多写少的场景
4.Semaphore,类似读写锁中读锁(共享锁),但其限制共享资源的访问数量,也就是不能像读锁一样没有限制的共享,原理是通过同步资源state模拟信号量的机制限制共享资源的访问线程数,可用于高峰期限制共享资源的访问线程数(具体的实践应用场景还有待学习和探索)
5.CountdownLatch,属于为线程通信机制而生的同步器组件,作用和join,wait基本一致,但CountdownLatch属于上层api,使用起来更简单更友好
6.CyclicBarrier,同样是为线程通信机制而生的同步器组件,改进了CountdownLatch不可复用的缺点
线程安全集合类概述
线程安全集合类可以分为三大类:
遗留的线程安全集合如Hashtable,Vector
使用Collections装饰的线程安全集合,如:
Collections.synchronizedCollection Collections.synchronizedList Collections.synchronizedMap Collections.synchronizedSet Collections.synchronizedNavigableMap Collections.synchronizedNavigableSet Collections.synchronizedSortedMap Collections.synchronizedSortedSet 说明:以上集合均采用修饰模式设计,将非线程安全的集合包装后,在调用方法时包裹了一层synchronized代码块。其并发性并不比遗留的安全集合好。
java.util.concurrent.*
重点介绍java.util.concurrent.* 下的线程安全集合类,可以发现它们有规律,里面包含三类关键词: Blocking、CopyOnWrite、Concurrent
Blocking 大部分实现基于锁,并提供用来阻塞的方法
CopyOnWrite 之类容器修改开销相对较重
Concurrent 类型的容器
内部很多操作使用 cas 优化,一般可以提供较高吞吐量
弱一致性
遍历时弱一致性,例如,当利用迭代器遍历时,如果容器发生修改,迭代器仍然可以继续进行遍 历,这时内容是旧的
求大小弱一致性,size 操作未必是 100% 准确
读取弱一致性
遍历时如果发生了修改,对于非安全容器来讲,使用 fail-fast 机制也就是让遍历立刻失败,抛出 ConcurrentModificationException,不再继续遍历
ConcurrentHashMap 应用之单词计数 搭建练习环境:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 public class Test { public static void main (String[] args) { } public static <V> void calculate (Supplier<Map<String,V>> supplier, BiConsumer<Map<String,V>, List<String>> consumer) { Map<String, V> map = supplier.get(); CountDownLatch count = new CountDownLatch (26 ); for (int i = 1 ; i < 27 ; i++) { int k = i; new Thread (()->{ ArrayList<String> list = new ArrayList <>(); read(list,k); consumer.accept(map,list); count.countDown(); }).start(); } try { count.await(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(map.toString()); } public static void read (List<String> list,int i) { try { String element; BufferedReader reader = new BufferedReader (new FileReader (i + ".txt" )); while ((element = reader.readLine()) != null ){ list.add(element); } }catch (IOException e){ } } public void construct () { String str = "abcdefghijklmnopqrstuvwxyz" ; ArrayList<String> list = new ArrayList <>(); for (int i = 0 ; i < str.length(); i++) { for (int j = 0 ; j < 200 ; j++) { list.add(String.valueOf(str.charAt(i))); } } Collections.shuffle(list); for (int i = 0 ; i < 26 ; i++) { try (PrintWriter out = new PrintWriter (new FileWriter (i + 1 + ".txt" ))) { String collect = list.subList(i * 200 , (i + 1 ) * 200 ).stream().collect(Collectors.joining("\n" )); out.println(collect); } catch (IOException e) { e.printStackTrace(); } } } }
实现一: 1 2 3 4 5 6 7 8 9 10 11 12 13 demo( () -> new ConcurrentHashMap <String, Integer>(), (map, words) -> { for (String word : words) { Integer counter = map.get(word); int newValue = counter == null ? 1 : counter + 1 ; map.put(word, newValue); } } );
输出:
1 2 {a=186, b=192, c=187, d=184, e=185, f=185, g=176, h=185, i=193, j=189, k=187, l=157, m=189, n=181, o=180, p=178, q=185, r=188, s=181, t=183, u=177, v=186, w=188, x=178, y=189, z=186} 47
错误原因:
ConcurrentHashMap虽然每个方法都是线程安全的,但是多个方法的组合并不是线程安全的 解决线程安全问题要先定位线程安全问题在哪里,才能进一步采取有效的方案解决 并且要注意很多线程安全类只是保障其方法api是线程安全的,调用完方法后就会释放锁,仍旧是线程不安全的,即使是多个线程安全的方法组合在一起他们仍旧是线程不安全的,因为方法调用完会释放锁,就一定出现指定的交叉运行
正确答案一: 1 2 3 4 5 6 7 8 9 demo( () -> new ConcurrentHashMap <String, LongAdder>(), (map, words) -> { for (String word : words) { map.computeIfAbsent(word, (key) -> new LongAdder ()).increment(); } } );
说明:
computIfAbsent方法的作用是:当map中不存在以参数1为key对应的value时,会将参数2函数式接口的返回值作为value,put进map中,然后返回该value。如果存在key,则直接返回value
以上两部均是线程安全的。
正确答案二: 1 2 3 4 5 6 7 8 9 demo( () -> new ConcurrentHashMap <String, Integer>(), (map, words) -> { for (String word : words) { map.merge(word, 1 , Integer::sum); } } );
ConcurrentHashMap 原理 JDK 7 HashMap 并发死链 测试代码 注意
要在 JDK 7 下运行,否则扩容机制和 hash 的计算方法都变了
以下测试代码是精心准备的,不要随便改动
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 public static void main (String[] args) { System.out.println("长度为16时,桶下标为1的key" ); for (int i = 0 ; i < 64 ; i++) { if (hash(i) % 16 == 1 ) { System.out.println(i); } } System.out.println("长度为32时,桶下标为1的key" ); for (int i = 0 ; i < 64 ; i++) { if (hash(i) % 32 == 1 ) { System.out.println(i); } } final HashMap<Integer, Integer> map = new HashMap <Integer, Integer>(); map.put(2 , null ); map.put(3 , null ); map.put(4 , null ); map.put(5 , null ); map.put(6 , null ); map.put(7 , null ); map.put(8 , null ); map.put(9 , null ); map.put(10 , null ); map.put(16 , null ); map.put(35 , null ); map.put(1 , null ); System.out.println("扩容前大小[main]:" +map.size()); new Thread () { @Override public void run () { map.put(50 , null ); System.out.println("扩容后大小[Thread-0]:" +map.size()); } }.start(); new Thread () { @Override public void run () { map.put(50 , null ); System.out.println("扩容后大小[Thread-1]:" +map.size()); } }.start(); } final static int hash (Object k) { int h = 0 ; if (0 != h && k instanceof String) { return sun.misc.Hashing.stringHash32((String) k); } h ^= k.hashCode(); h ^= (h >>> 20 ) ^ (h >>> 12 ); return h ^ (h >>> 7 ) ^ (h >>> 4 ); }
死链复现 调试工具使用 idea
在 HashMap 源码 590 行加断点
1 int newCapacity = newTable.length;
断点的条件如下,目的是让 HashMap 在扩容为 32 时,并且线程为 Thread-0 或 Thread-1 时停下来
1 2 3 4 5 newTable.length==32 && ( Thread.currentThread().getName().equals("Thread-0" )|| Thread.currentThread().getName().equals("Thread-1" ) )
断点暂停方式选择 Thread,否则在调试 Thread-0 时,Thread-1 无法恢复运行
运行代码,程序在预料的断点位置停了下来,输出
1 2 3 4 5 6 7 8 9 长度为16时,桶下标为1的key 1 16 35 50 长度为32时,桶下标为1的key 1 35 扩容前大小[main]:12
接下来进入扩容流程调试
在 HashMap 源码 594 行加断点
1 2 3 Entry<K,V> next = e.next; if (rehash)
这是为了观察 e 节点和 next 节点的状态,Thread-0 单步执行到 594 行,再 594 处再添加一个断点(条件 Thread.currentThread().getName().equals(“Thread-0”))
这时可以在 Variables 面板观察到 e 和 next 变量,使用view as -> Object查看节点状态
1 2 e (1 )->(35 )->(16 )->null next (35 ) ->(16 )->null
在 Threads 面板选中 Thread-1 恢复运行,可以看到控制台输出新的内容如下,Thread-1 扩容已完成
1 newTable[1 ] (35 )->(1 )->null
这时 Thread-0 还停在 594 处, Variables 面板变量的状态已经变化为
1 2 e (1 )->null next (35 ) ->(1 )->null
为什么呢,因为 Thread-1 扩容时链表也是后加入的元素放入链表头,因此链表就倒过来了,但 Thread-1 虽然结 果正确,但它结束后 Thread-0 还要继续运行
接下来就可以单步调试(F8)观察死链的产生了
下一轮循环到 594,将 e 搬迁到 newTable 链表头
1 2 3 newTable[1 ] (1 )->null e (35 ) ->(1 )->null next (1 ) ->null
下一轮循环到 594,将 e 搬迁到 newTable 链表头
1 2 3 newTable[1 ] (35 )->(1 )->null e (1 ) ->null next null
再看看源码
1 2 3 4 5 6 7 e.next = newTable[1 ]; newTable[1 ] = e; e = next;
源码分析 HashMap 的并发死链发生在扩容时
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void transfer (Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; for (Entry<K,V> e : table) { while (null != e) { Entry<K,V> next = e.next; if (rehash) { e.hash = null == e.key ? 0 : hash(e.key); } int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; newTable[i] = e; e = next; } } }
假设 map 中初始元素是
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 原始链表,格式:[下标] (key,next) [1 ] (1 ,35 )->(35 ,16 )->(16 ,null ) 线程 a 执行到 1 处 ,此时局部变量 e 为 (1 ,35 ),而局部变量 next 为 (35 ,16 ) 线程 a 挂起 线程 b 开始执行 第一次循环 [1 ] (1 ,null ) 第二次循环 [1 ] (35 ,1 )->(1 ,null ) 第三次循环 [1 ] (35 ,1 )->(1 ,null ) [17 ] (16 ,null ) 切换回线程 a,此时局部变量 e 和 next 被恢复,引用没变但内容变了:e 的内容被改为 (1 ,null ),而 next 的内 容被改为 (35 ,1 ) 并链向 (1 ,null ) 第一次循环 [1 ] (1 ,null ) 第二次循环,注意这时 e 是 (35 ,1 ) 并链向 (1 ,null ) 所以 next 又是 (1 ,null ) [1 ] (35 ,1 )->(1 ,null ) 第三次循环,e 是 (1 ,null ),而 next 是 null ,但 e 被放入链表头,这样 e.next 变成了 35 (2 处) [1 ] (1 ,35 )->(35 ,1 )->(1 ,35 ) 已经是死链了
小结
究其原因,是因为在多线程环境下使用了非线程安全的 map 集合
JDK 8 虽然将扩容算法做了调整,不再将元素加入链表头(而是保持与扩容前一样的顺序),但仍不意味着能 够在多线程环境下能够安全扩容,还会出现其它问题(如扩容丢数据)
JDK 8 ConcurrentHashMap 重要属性和内部类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 private transient volatile int sizeCtl;static class Node <K,V> implements Map .Entry<K,V> {}transient volatile Node<K,V>[] table;private transient volatile Node<K,V>[] nextTable;static final class ForwardingNode <K,V> extends Node <K,V> {}static final class ReservationNode <K,V> extends Node <K,V> {}static final class TreeBin <K,V> extends Node <K,V> {}static final class TreeNode <K,V> extends Node <K,V> {}
重要方法 1 2 3 4 5 6 7 8 9 10 11 static final <K,V> Node<K,V> tabAt (Node<K,V>[] tab, int i) static final <K,V> boolean casTabAt (Node<K,V>[] tab, int i, Node<K,V> c, Node<K,V> v) static final <K,V> void setTabAt (Node<K,V>[] tab, int i, Node<K,V> v)
构造器分析 可以看到实现了懒惰初始化,在构造方法中仅仅计算了 table 的大小,以后在第一次使用时才会真正创建
1 2 3 4 5 6 7 8 9 10 11 public ConcurrentHashMap (int initialCapacity, float loadFactor, int concurrencyLevel) { if (!(loadFactor > 0.0f ) || initialCapacity < 0 || concurrencyLevel <= 0 ) throw new IllegalArgumentException (); if (initialCapacity < concurrencyLevel) initialCapacity = concurrencyLevel; long size = (long )(1.0 + (long )initialCapacity / loadFactor); int cap = (size >= (long )MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : tableSizeFor((int )size); this .sizeCtl = cap; }
初始化方法 初始化方法能保证线程安全性的核心原理是使用CAS算法实现线程的同步互斥效果,用CAS算法操作sizectl变量,只要有线程在初始化了就使用CAS算法将该标记变量设置为-1,其他线程因为标记变量的值发生了变化,CAS算法修改值失败,无法进入初始化流程,自然就实现了初始化过程中的线程同步互斥效果了
细节:因为concurrentHashMap是懒惰初始化,所以初始化流程是在put方法内部执行的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 private final Node<K,V>[] initTable() { Node<K,V>[] tab; int sc; while ((tab = table) == null || tab.length == 0 ) { if ((sc = sizeCtl) < 0 ) Thread.yield (); else if (U.compareAndSwapInt(this , SIZECTL, sc, -1 )) { try { if ((tab = table) == null || tab.length == 0 ) { int n = (sc > 0 ) ? sc : DEFAULT_CAPACITY; @SuppressWarnings("unchecked") Node<K,V>[] nt = (Node<K,V>[])new Node <?,?>[n]; table = tab = nt; sc = n - (n >>> 2 ); } } finally { sizeCtl = sc; } break ; } } return tab; }
get流程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public V get (Object key) { Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek; int h = spread(key.hashCode()); if ((tab = table) != null && (n = tab.length) > 0 && (e = tabAt(tab, (n - 1 ) & h)) != null ) { if ((eh = e.hash) == h) { if ((ek = e.key) == key || (ek != null && key.equals(ek))) return e.val; } else if (eh < 0 ) return (p = e.find(h, key)) != null ? p.val : null ; while ((e = e.next) != null ) { if (e.hash == h && ((ek = e.key) == key || (ek != null && key.equals(ek)))) return e.val; } } return null ; }
总结:
如果table不为空且长度大于0且索引位置有元素
if 头节点key的hash值相等
else if 头节点的hash为负数(数组在扩容或者是treebin节点)
进入循环(e不为空):
节点key的hash值相等,且key指向同一个地址或equals
返回null
为什么读操作get不用加锁就可以保证线程安全性呢?
首先如果是并发读读操作不会产生线程安全问题,其次即使是并发读写操作,也只会产生读取脏数据,不可重复读的问题,其中读取脏数据是不能忍受的,而不可重复读基本不影响结果,一般不需要处理
读取脏数据的原因是线程的写操作对其他不可见,原理是线程读写操作有可能针对是缓存,自然其他线程对其缓存是不可见,只要保证线程读写操作都是操作的内存而非缓存,自然就可以实现可见性了,所以只要加volatile关键字即可实现可见性和有序性
put 流程 以下数组简称(table),链表简称(bin)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 public V put (K key, V value) { return putVal(key, value, false ); } final V putVal (K key, V value, boolean onlyIfAbsent) { if (key == null || value == null ) throw new NullPointerException (); int hash = spread(key.hashCode()); int binCount = 0 ; for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; if (tab == null || (n = tab.length) == 0 ) tab = initTable(); else if ((f = tabAt(tab, i = (n - 1 ) & hash)) == null ) { if (casTabAt(tab, i, null , new Node <K,V>(hash, key, value, null ))) break ; } else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); else { V oldVal = null ; synchronized (f) { if (tabAt(tab, i) == f) { if (fh >= 0 ) { binCount = 1 ; for (Node<K,V> e = f;; ++binCount) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break ; } Node<K,V> pred = e; if ((e = e.next) == null ) { pred.next = new Node <K,V>(hash, key, value, null ); break ; } } } else if (f instanceof TreeBin) { Node<K,V> p; binCount = 2 ; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null ) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0 ) { if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); if (oldVal != null ) return oldVal; break ; } } } addCount(1L , binCount); return null ; } private final Node<K,V>[] initTable() { Node<K,V>[] tab; int sc; while ((tab = table) == null || tab.length == 0 ) { if ((sc = sizeCtl) < 0 ) Thread.yield (); else if (U.compareAndSwapInt(this , SIZECTL, sc, -1 )) { try { if ((tab = table) == null || tab.length == 0 ) { int n = (sc > 0 ) ? sc : DEFAULT_CAPACITY; Node<K,V>[] nt = (Node<K,V>[])new Node <?,?>[n]; table = tab = nt; sc = n - (n >>> 2 ); } } finally { sizeCtl = sc; } break ; } } return tab; } private final void addCount (long x, int check) { CounterCell[] as; long b, s; if ( (as = counterCells) != null || !U.compareAndSwapLong(this , BASECOUNT, b = baseCount, s = b + x) ) { CounterCell a; long v; int m; boolean uncontended = true ; if ( as == null || (m = as.length - 1 ) < 0 || (a = as[ThreadLocalRandom.getProbe() & m]) == null || !(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x)) ) { fullAddCount(x, uncontended); return ; } if (check <= 1 ) return ; s = sumCount(); } }
总结:
1.做插入操作时,首先进入乐观锁(死循环for,直到put操作完成才会退出循环)
2.判断容器是否初始化(容器初始化流程也是用乐观锁思想来实现,即CAS来实现)
3.如果已经初始化,则判断该hash位置的节点是否为空,如果为空,则通过CAS操作进行插入
4.如果该节点不为空,再判断容器是否在扩容中 ,如果在扩容,则帮助其扩容
5.如果没有扩容,则进行最后一步,先加锁,然后找到hash值相同的那个节点(hash冲突)
当出现hash冲突时,就会出现多个共享数据(链表 or 红黑树),此时使用无锁(CAS)实现已经无法解决线程安全问题,只能使用有锁来实现,但jdk8对于锁的范围优化的非常好,充分利用了链表结构只能根据前一个节点才能找到一个节点的特性,只给了链表头节点上锁就可以实现线程的同步互斥效果了,也就是锁的范围变成了每个链表的头节点,而非整个数组+链表,大大缩小了锁的范围,从而大大提高了并发的性能
6.循环判断这个节点上的链表,决定做更新操作还是插入操作
7.判断链表的长度是否大于等于8,如果是则需要将链表转换成红黑树
8.增加元素计数(原理是使用原子累加器实现 )
9.检查容器是否需要扩容,如果需要则进行扩容操作
触发扩容的两种情况
A.容器中元素的数量已经达到了容器的当前阈值(负载因子 * 数组长度)
B.容器中的元素数量<64且某一个桶的链表长度大于等于8
扩容原理 A.判断容器是否需要扩容的addCount方法
addCount扩容判断流程流程
判断是否需要扩容
如果正在扩容中,就协助扩容
如果还没有扩容,新建数组开始扩容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 private final void addCount (long x, int check) { if (check >= 0 ) { Node<K,V>[] tab, nt; int n, sc; while (s >= (long )(sc = sizeCtl) && (tab = table) != null && (n = tab.length) < MAXIMUM_CAPACITY) { int rs = resizeStamp(n); if (sc < 0 ) { if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0 ) break ; if (U.compareAndSwapInt(this , SIZECTL, sc, sc + 1 )) transfer(tab, nt); } else if (U.compareAndSwapInt(this , SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2 )) transfer(tab, null ); s = sumCount(); } } }
说明1
1 2 3 static final int resizeStamp(int n) { return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1)); }
Integer.numberOfLeadingZeros表示一个数从高位算起为0的位的个数,比如当n = 1时,结果为31,当n = 2时,结果为30。
1 << (RESIZE_STAMP_BITS - 1),由于RESIZE_STAMP_BITS = 16,所以这个就是把1的二进制左移15位,也就是2^16,2的16次方。
上面两个结果做或运算,就相当于两个数向加,因为第二数的低16位全是0。假设n = 16,最后的结果为:32795
由于每次传入的n不相同,所以每次结果也不同,也就是每次的标识也不同,这个值这么做的好处就是只在低16位有值,在下面计算sizeCtl的时候,只要继续左移16位,那低16位也就没有值了
说明2
1 sc >>> RESIZE_STAMP_SHIFT) != rs
这段代码是否成立,要想搞清楚这段代码是否成立,要先搞清楚sc是多少。
1 while (s >= (long)(sc = sizeCtl)
从while循环看,sc = sizeCtl,那sizeCtl是多少,如下:
1 2 else if (U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2))
这个CAS操作,会修改sizeCtl的值,最后sizeCtl = ( (rs << 16) + 2),可以知道最开始的那个不等式就相当于如下:
1 ((rs << RESIZE_STAMP_SHIFT) + 2) >>> RESIZE_STAMP_SHIFT != rs
上面这个公式就很清楚了,相当于rs先有符号左移16位,之后加2,最后再无符号右移16位,由于加的2在低位,右移的时候就没了,所以最后的结果还是rs
说明3
经过上面两个说明,应该可以清楚的知道sizeCtl的高16位是标志位,就是每一轮扩容生成的一个唯一的标志,低16位标识参与扩容的线程数,所以这里进行加1操作 。那问题来了,为什么要记录参与扩容的线程数?这个原因一会看扩容的代码就明白了,这里先提一下,记录参与扩容的线程数的原因是每个线程执行完扩容,sizeCtl就减1,当最后发现sizeCtl = rs <<RESIZE_STAMP_SHIFT的时候,说明所有参与扩容的线程都执行完,防止最后以为扩容结束了,旧的数组都被干掉了,但是还有的线程在copy
B.真正的扩容原理和流程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 private final void transfer (Node<K,V>[] tab, Node<K,V>[] nextTab) { int n = tab.length, stride; if ((stride = (NCPU > 1 ) ? (n >>> 3 ) / NCPU : n) < MIN_TRANSFER_STRIDE) stride = MIN_TRANSFER_STRIDE; if (nextTab == null ) { try { Node<K,V>[] nt = (Node<K,V>[])new Node <?,?>[n << 1 ]; nextTab = nt; } catch (Throwable ex) { sizeCtl = Integer.MAX_VALUE; return ; } nextTable = nextTab; transferIndex = n; } int nextn = nextTab.length; ForwardingNode<K,V> fwd = new ForwardingNode <K,V>(nextTab); boolean advance = true ; boolean finishing = false ; for (int i = 0 , bound = 0 ;;) { Node<K,V> f; int fh; while (advance) { int nextIndex, nextBound; if (--i >= bound || finishing) advance = false ; else if ((nextIndex = transferIndex) <= 0 ) { i = -1 ; advance = false ; } else if (U.compareAndSwapInt (this , TRANSFERINDEX, nextIndex, nextBound = (nextIndex > stride ? nextIndex - stride : 0 ))) { bound = nextBound; i = nextIndex - 1 ; advance = false ; } } if (i < 0 || i >= n || i + n >= nextn) { int sc; if (finishing) { nextTable = null ; table = nextTab; sizeCtl = (n << 1 ) - (n >>> 1 ); return ; } if (U.compareAndSwapInt(this , SIZECTL, sc = sizeCtl, sc - 1 )) { if ((sc - 2 ) != resizeStamp(n) << RESIZE_STAMP_SHIFT) return ; finishing = advance = true ; i = n; } } else if ((f = tabAt(tab, i)) == null ) advance = casTabAt(tab, i, null , fwd); else if ((fh = f.hash) == MOVED) advance = true ; else { synchronized (f) { if (tabAt(tab, i) == f) { Node<K,V> ln, hn; if (fh >= 0 ) { int runBit = fh & n; Node<K,V> lastRun = f; for (Node<K,V> p = f.next; p != null ; p = p.next) { int b = p.hash & n; if (b != runBit) { runBit = b; lastRun = p; } } if (runBit == 0 ) { ln = lastRun; hn = null ; } else { hn = lastRun; ln = null ; } for (Node<K,V> p = f; p != lastRun; p = p.next) { int ph = p.hash; K pk = p.key; V pv = p.val; if ((ph & n) == 0 ) ln = new Node <K,V>(ph, pk, pv, ln); else hn = new Node <K,V>(ph, pk, pv, hn); } setTabAt(nextTab, i, ln); setTabAt(nextTab, i + n, hn); setTabAt(tab, i, fwd); advance = true ; } else if (f instanceof TreeBin) { TreeBin<K,V> t = (TreeBin<K,V>)f; TreeNode<K,V> lo = null , loTail = null ; TreeNode<K,V> hi = null , hiTail = null ; int lc = 0 , hc = 0 ; for (Node<K,V> e = t.first; e != null ; e = e.next) { int h = e.hash; TreeNode<K,V> p = new TreeNode <K,V> (h, e.key, e.val, null , null ); if ((h & n) == 0 ) { if ((p.prev = loTail) == null ) lo = p; else loTail.next = p; loTail = p; ++lc; } else { if ((p.prev = hiTail) == null ) hi = p; else hiTail.next = p; hiTail = p; ++hc; } } ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) : (hc != 0 ) ? new TreeBin <K,V>(lo) : t; hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) : (lc != 0 ) ? new TreeBin <K,V>(hi) : t; setTabAt(nextTab, i, ln); setTabAt(nextTab, i + n, hn); setTabAt(tab, i, fwd); advance = true ; } } } } } }
以上流程如下:
根据CPU核数和集合length计算每个核一轮处理桶的个数,最小是16
修改transferIndex标志位,每个线程领取完任务就减去多少,比如初始大小是transferIndex = table.length = 64,每个线程领取的桶个数是16,第一个线程领取完任务后transferIndex = 48,也就是说第二个线程这时进来是从第48个桶开始处理,再减去16,依次类推,这就是多线程协作处理的原理
领取完任务之后就开始处理,如果桶为空就设置为ForwardingNode,如果不为空就加锁拷贝,拷贝完成之后也设置为ForwardingNode节点
如果某个线程分配的桶处理完了之后,再去申请,发现transferIndex = 0,这个时候就说明所有的桶都领取完了,但是别的线程领取任务之后有没有处理完并不知道,该线程会将sizeCtl的值减1,然后判断是不是所有线程都退出了,如果还有线程在处理,就退出
直到最后一个线程处理完,发现sizeCtl = rs<< RESIZE_STAMP_SHIFT,才会将旧数组干掉,用新数组覆盖,并且会重新设置sizeCtl为新数组的扩容点
以上过程总的来说分成两个部分:
分配任务部分:这部分其实很简单,就是把一个大的数组给切分,切分多个小份,然后每个线程处理其中每一小份,当然可能就只有1个或者几个线程在扩容,那就一轮一轮的处理,一轮处理一份
处理任务部分:复制部分主要有两点,第一点就是加锁,第二点就是处理完之后置为ForwardingNode
精华部分图解
1.ConCurrentHashMap 支持并发扩容,实现方式是,将表拆分,让每个线程处理自己的区间
2.而每个线程在处理自己桶中的数据的时候,是下图这样的
扩容前的状态
当对 4 号桶或者 10 号桶进行转移的时候,会将链表拆成两份,规则是根据节点的 hash 值取于 length,如果结果是 0,放在低位,否则放在高位
扩容结果
扩容总结 通过给每个线程分配桶区间来支持多线程扩容,通过标记节点避免实现线程间扩容的可见性,通过加锁实现桶节点扩容过程中的安全性,扩容性能之所以高,是因为其中运用了大量的无锁实现而非直接加重量级锁,这才给多线程扩容提供了鼎立的支持
关于标记节点和加锁的说明
在多线程环境下,ConcurrentHashMap用两点来保证正确性:ForwardingNode和synchronized 。当一个线程遍历到的节点如果是ForwardingNode,则继续往后遍历,如果不是,则将该节点加锁,防止其他线程进入,完成后设置ForwardingNode节点,以便要其他线程可以看到该节点已经处理过了,如此交叉进行,高效而又安全
参考文献
1.ConcurrentHashMap原理分析(二)-扩容 - 猿起缘灭 - 博客园 (cnblogs.com)
2.并发编程——ConcurrentHashMap#transfer() 扩容逐行分析 - 掘金 (juejin.cn)
size 计算流程 size 计算实际发生在 put,remove 改变集合元素的操作之中
没有竞争发生,向 baseCount 累加计数
有竞争发生,新建 counterCells,向其中的一个 cell 累加计
counterCells 初始有两个 cell
如果计数竞争比较激烈,会创建新的 cell 来累加计数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public int size () { long n = sumCount(); return ((n < 0L ) ? 0 : (n > (long )Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int )n); } final long sumCount () { CounterCell[] as = counterCells; CounterCell a; long sum = baseCount; if (as != null ) { for (int i = 0 ; i < as.length; ++i) { if ((a = as[i]) != null ) sum += a.value; } } return sum; }
性能分析 ConcurrentHashMap为什么在多线程环境下性能仍然非常高呢?
原因在于其运用了大量的无锁实现,并没有上来就加重量级锁,即使后来加重量级锁也只是给桶节点的链表头节点加锁,大大缩小了锁的细粒度,即使在扩容过程中也是如此,线程的并发度非常高,性能自然就不会差
分析源码的思路 1.从源码的设计思想入手分析,最好是分析思路是依据源码的设计思路->具体的方法流程图分析->步骤总结三个步骤入手分析源码,一般吃透源码的思想是没有问题的,而且精华就在思想部分而不是具体的某些细节
2.切记一上来就扎进代码中,没有任何意义,代码中的细节非常多,非常的复杂,分析起来会耗费大量的时间,且需要你自己从代码中归纳中源码的设计思想和具体实现,非常的困难,结果往往是浪费了大量的时间也分析不出个所以然出来
JDK 7 ConcurrentHashMap 它维护了一个 segment 数组,每个 segment 对应一把锁
优点:如果多个线程访问不同的 segment,实际是没有冲突的,这与 jdk8 中是类似的
缺点:Segments 数组默认大小为16,这个容量初始化指定后就不能改变了,并且不是懒惰初始化
构造器分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public ConcurrentHashMap (int initialCapacity, float loadFactor, int concurrencyLevel) { if (!(loadFactor > 0 ) || initialCapacity < 0 || concurrencyLevel <= 0 ) throw new IllegalArgumentException (); if (concurrencyLevel > MAX_SEGMENTS) concurrencyLevel = MAX_SEGMENTS; int sshift = 0 ; int ssize = 1 ; while (ssize < concurrencyLevel) { ++sshift; ssize <<= 1 ; } this .segmentShift = 32 - sshift; this .segmentMask = ssize - 1 ; if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; int c = initialCapacity / ssize; if (c * ssize < initialCapacity) ++c; int cap = MIN_SEGMENT_TABLE_CAPACITY; while (cap < c) cap <<= 1 ; Segment<K,V> s0 = new Segment <K,V>(loadFactor, (int )(cap * loadFactor), (HashEntry<K,V>[])new HashEntry [cap]); Segment<K,V>[] ss = (Segment<K,V>[])new Segment [ssize]; UNSAFE.putOrderedObject(ss, SBASE, s0); this .segments = ss; }
put 流程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public V put (K key, V value) { Segment<K,V> s; if (value == null ) throw new NullPointerException (); int hash = hash(key); int j = (hash >>> segmentShift) & segmentMask; if ((s = (Segment<K,V>)UNSAFE.getObject (segments, (j << SSHIFT) + SBASE)) == null ) { s = ensureSegment(j); } return s.put(key, hash, value, false ); }
segment 继承了可重入锁(ReentrantLock),它的 put 方法为
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 final V put (K key, int hash, V value, boolean onlyIfAbsent) { HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value); V oldValue; try { HashEntry<K,V>[] tab = table; int index = (tab.length - 1 ) & hash; HashEntry<K,V> first = entryAt(tab, index); for (HashEntry<K,V> e = first;;) { if (e != null ) { K k; if ((k = e.key) == key || (e.hash == hash && key.equals(k))) { oldValue = e.value; if (!onlyIfAbsent) { e.value = value; ++modCount; } break ; } e = e.next; } else { if (node != null ) node.setNext(first); else node = new HashEntry <K,V>(hash, key, value, first); int c = count + 1 ; if (c > threshold && tab.length < MAXIMUM_CAPACITY) rehash(node); else setEntryAt(tab, index, node); ++modCount; count = c; oldValue = null ; break ; } } } finally { unlock(); } return oldValue; }
rehash 流程 发生在 put 中,因为此时已经获得了锁,因此 rehash 时不需要考虑线程安全
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 private void rehash (HashEntry<K,V> node) { HashEntry<K,V>[] oldTable = table; int oldCapacity = oldTable.length; int newCapacity = oldCapacity << 1 ; threshold = (int )(newCapacity * loadFactor); HashEntry<K,V>[] newTable = (HashEntry<K,V>[]) new HashEntry [newCapacity]; int sizeMask = newCapacity - 1 ; for (int i = 0 ; i < oldCapacity ; i++) { HashEntry<K,V> e = oldTable[i]; if (e != null ) { HashEntry<K,V> next = e.next; int idx = e.hash & sizeMask; if (next == null ) newTable[idx] = e; else { HashEntry<K,V> lastRun = e; int lastIdx = idx; for (HashEntry<K,V> last = next; last != null ; last = last.next) { int k = last.hash & sizeMask; if (k != lastIdx) { lastIdx = k; lastRun = last; } } newTable[lastIdx] = lastRun; for (HashEntry<K,V> p = e; p != lastRun; p = p.next) { V v = p.value; int h = p.hash; int k = h & sizeMask; HashEntry<K,V> n = newTable[k]; newTable[k] = new HashEntry <K,V>(h, p.key, v, n); } } } } int nodeIndex = node.hash & sizeMask; node.setNext(newTable[nodeIndex]); newTable[nodeIndex] = node; table = newTable; }
附,调试代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public static void main (String[] args) { ConcurrentHashMap<Integer, String> map = new ConcurrentHashMap <>(); for (int i = 0 ; i < 1000 ; i++) { int hash = hash(i); int segmentIndex = (hash >>> 28 ) & 15 ; if (segmentIndex == 4 && hash % 8 == 2 ) { System.out.println(i + "\t" + segmentIndex + "\t" + hash % 2 + "\t" + hash % 4 + "\t" + hash % 8 ); } } map.put(1 , "value" ); map.put(15 , "value" ); map.put(169 , "value" ); map.put(197 , "value" ); map.put(341 , "value" ); map.put(484 , "value" ); map.put(545 , "value" ); map.put(912 , "value" ); map.put(941 , "value" ); System.out.println("ok" ); } private static int hash (Object k) { int h = 0 ; if ((0 != h) && (k instanceof String)) { return sun.misc.Hashing.stringHash32((String) k); } h ^= k.hashCode(); h += (h << 15 ) ^ 0xffffcd7d ; h ^= (h >>> 10 ); h += (h << 3 ); h ^= (h >>> 6 ); h += (h << 2 ) + (h << 14 ); int v = h ^ (h >>> 16 ); return v; }
get 流程 get 时并未加锁,用了 UNSAFE 方法保证了可见性,扩容过程中,get 先发生就从旧表取内容,get 后发生就从新 表取内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public V get (Object key) { Segment<K,V> s; HashEntry<K,V>[] tab; int h = hash(key); long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE; if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null && (tab = s.table) != null ) { for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile (tab, ((long )(((tab.length - 1 ) & h)) << TSHIFT) + TBASE); e != null ; e = e.next) { K k; if ((k = e.key) == key || (e.hash == h && key.equals(k))) return e.value; } } return null ; }
size 计算流程
计算元素个数前,先不加锁计算两次,如果前后两次结果如一样,认为个数正确返回
如果不一样,进行重试,重试次数超过 3,将所有 segment 锁住,重新计算个数返回
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 public int size () { final Segment<K,V>[] segments = this .segments; int size; boolean overflow; long sum; long last = 0L ; int retries = -1 ; try { for (;;) { if (retries++ == RETRIES_BEFORE_LOCK) { for (int j = 0 ; j < segments.length; ++j) ensureSegment(j).lock(); } sum = 0L ; size = 0 ; overflow = false ; for (int j = 0 ; j < segments.length; ++j) { Segment<K,V> seg = segmentAt(segments, j); if (seg != null ) { sum += seg.modCount; int c = seg.count; if (c < 0 || (size += c) < 0 ) overflow = true ; } } if (sum == last) break ; last = sum; } } finally { if (retries > RETRIES_BEFORE_LOCK) { for (int j = 0 ; j < segments.length; ++j) segmentAt(segments, j).unlock(); } } return overflow ? Integer.MAX_VALUE : size; }
BlockingQueue BlockingQueue 原理 基本的入队出队 1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class LinkedBlockingQueue <E> extends AbstractQueue <E> implements BlockingQueue <E>, java.io.Serializable { static class Node <E> { E item; Node<E> next; Node(E x) { item = x; } } }
加锁分析 高明之处 在于用了两把锁和 dummy 节点
用一把锁,同一时刻,最多只允许有一个线程(生产者或消费者,二选一)执行
用两把锁,同一时刻,可以允许两个线程同时(一个生产者与一个消费者)执行
消费者与消费者线程仍然串行
生产者与生产者线程仍然串行
线程安全分析
当节点总数大于 2 时(包括 dummy 节点),putLock 保证的是 last 节点的线程安全,takeLock 保证的是 head 节点的线程安全。两把锁保证了入队和出队没有竞争
当节点总数等于 2 时(即一个 dummy 节点,一个正常节点)这时候,仍然是两把锁锁两个对象,不会竞争
当节点总数等于 1 时(就一个 dummy 节点)这时 take 线程会被 notEmpty 条件阻塞,有竞争,会阻塞
1 2 3 4 private final ReentrantLock putLock = new ReentrantLock ();private final ReentrantLock takeLock = new ReentrantLock ();
put 操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public void put (E e) throws InterruptedException { if (e == null ) throw new NullPointerException (); int c = -1 ; Node<E> node = new Node <E>(e); final ReentrantLock putLock = this .putLock; final AtomicInteger count = this .count; putLock.lockInterruptibly(); try { while (count.get() == capacity) { notFull.await(); } enqueue(node); c = count.getAndIncrement(); if (c + 1 < capacity) notFull.signal(); } finally { putLock.unlock(); } if (c == 0 ) signalNotEmpty(); }
take 操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public E take () throws InterruptedException { E x; int c = -1 ; final AtomicInteger count = this .count; final ReentrantLock takeLock = this .takeLock; takeLock.lockInterruptibly(); try { while (count.get() == 0 ) { notEmpty.await(); } x = dequeue(); c = count.getAndDecrement(); if (c > 1 ) notEmpty.signal(); } finally { takeLock.unlock(); } if (c == capacity) signalNotFull() return x; }
由 put 唤醒 put 是为了避免信号不足
性能比较 主要列举 LinkedBlockingQueue 与 ArrayBlockingQueue 的性能比较
Linked 支持有界,Array 强制有界
Linked 实现是链表,Array 实现是数组
Linked 是懒惰的,而 Array 需要提前初始化 Node 数组
Linked 每次入队会生成新 Node,而 Array 的 Node 是提前创建好的
Linked 两把锁,Array 一把锁
ConcurrentLinkedQueue ConcurrentLinkedQueue 的设计与 LinkedBlockingQueue 非常像,也是
两把【锁】,同一时刻,可以允许两个线程同时(一个生产者与一个消费者)执行
dummy 节点的引入让两把【锁】将来锁住的是不同对象,避免竞争
只是这【锁】使用了 cas 来实现
事实上,ConcurrentLinkedQueue 应用还是非常广泛的
例如之前讲的 Tomcat 的 Connector 结构时,Acceptor 作为生产者向 Poller 消费者传递事件信息时,正是采用了 ConcurrentLinkedQueue 将 SocketChannel 给 Poller 使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 graph LR subgraph Connector->NIO EndPoint t1(LimitLatch) t2(Acceptor) t3(SocketChannel 1) t4(SocketChannel 2) t5(Poller) subgraph Executor t7(worker1) t8(worker2) end t1 --> t2 t2 --> t3 t2 --> t4 t3 --有读--> t5 t4 --有读--> t5 t5 --socketProcessor--> t7 t5 --socketProcessor--> t8 end
ConcurrentLinkedQueue 原理 模仿 ConcurrentLinkedQueue 初始代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 package cn.itcast.concurrent.thirdpart.test;import java.util.Collection;import java.util.Iterator;import java.util.Queue;import java.util.concurrent.atomic.AtomicReference;public class Test3 { public static void main (String[] args) { MyQueue<String> queue = new MyQueue <>(); queue.offer("1" ); queue.offer("2" ); queue.offer("3" ); System.out.println(queue); } } class MyQueue <E> implements Queue <E> { @Override public String toString () { StringBuilder sb = new StringBuilder (); for (Node<E> p = head; p != null ; p = p.next.get()) { E item = p.item; if (item != null ) { sb.append(item).append("->" ); } } sb.append("null" ); return sb.toString(); } @Override public int size () { return 0 ; } @Override public boolean isEmpty () { return false ; } @Override public boolean contains (Object o) { return false ; } @Override public Iterator<E> iterator () { return null ; } @Override public Object[] toArray() { return new Object [0 ]; } @Override public <T> T[] toArray(T[] a) { return null ; } @Override public boolean add (E e) { return false ; } @Override public boolean remove (Object o) { return false ; } @Override public boolean containsAll (Collection<?> c) { return false ; } @Override public boolean addAll (Collection<? extends E> c) { return false ; } @Override public boolean removeAll (Collection<?> c) { return false ; } @Override public boolean retainAll (Collection<?> c) { return false ; } @Override public void clear () { } @Override public E remove () { return null ; } @Override public E element () { return null ; } @Override public E peek () { return null ; } public MyQueue () { head = last = new Node <>(null , null ); } private volatile Node<E> last; private volatile Node<E> head; private E dequeue () { return null ; } @Override public E poll () { return null ; } @Override public boolean offer (E e) { return true ; } static class Node <E> { volatile E item; public Node (E item, Node<E> next) { this .item = item; this .next = new AtomicReference <>(next); } AtomicReference<Node<E>> next; } }
offer
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public boolean offer (E e) { Node<E> n = new Node <>(e, null ); while (true ) { AtomicReference<Node<E>> next = last.next; if (next.compareAndSet(null , n)) { last = n; return true ; } } }
CopyOnWriteArrayList CopyOnWriteArraySet是它的马甲 底层实现采用了 写入时拷贝 的思想,增删改操作会将底层数组拷贝一份,更 改操作在新数组上执行,这时不影响其它线程的并发读 ,读写分离 。 以新增为例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public boolean add (E e) { synchronized (lock) { Object[] es = getArray(); int len = es.length; es = Arrays.copyOf(es, len + 1 ); es[len] = e; setArray(es); return true ; } }
这里的源码版本是 Java 11,在 Java 1.8 中使用的是可重入锁而不是 synchronized
其它读操作并未加锁,例如:
1 2 3 4 5 6 7 public void forEach (Consumer<? super E> action) { Objects.requireNonNull(action); for (Object x : getArray()) { @SuppressWarnings("unchecked") E e = (E) x; action.accept(e); } }
适合『读多写少』的应用场景
get 弱一致性
时间点
操作
1
Thread-0 getArray()
2
Thread-1 getArray()
3
Thread-1 setArray(arrayCopy)
4
Thread-0 array[index]
不容易测试,但问题确实存在
迭代器弱一致性 1 2 3 4 5 6 7 8 9 10 11 12 13 14 CopyOnWriteArrayList<Integer> list = new CopyOnWriteArrayList <>(); list.add(1 ); list.add(2 ); list.add(3 ); Iterator<Integer> iter = list.iterator(); new Thread (() -> { list.remove(0 ); System.out.println(list); }).start(); sleep1s(); while (iter.hasNext()) { System.out.println(iter.next()); }
不要觉得弱一致性就不好
数据库的 MVCC 都是弱一致性的表现
并发高和一致性是矛盾的,需要权衡
关于线程安全集合这章的原理+源码解析,个人觉得黑马的视频后面讲的太宽泛了,太水了,没有深入细节的讲解,只是粗略过了一遍,很多都没有讲为什么这样设计,甚至忽略了很多点,所以在这一章节基本没有学到什么,只是把黑马的源码笔记copy下来(因为他的源码有注释),后续希望从各种途径再继续深入学习这一章节的原理
集合之所以能够保证线程安全性,正是应用了前面学习有锁实现和无锁实现,深入学习线程安全性集合的原理有助于我们深入理解无锁,有锁实现的原理和应用,所以深入学习线程安全性集合是如何保证线程安全性是非常有必要的
总结 线程并发会出现的情况以及会导致的问题,我将其分为三类
1.并发读读,不会出现线程安全性问题,因为不涉及共享数据的写操作
2.并发读写,会出现读到脏数据(一个线程更新了数据但该更新操作对其他线程不可见,原因在于cpu的内存的缓存机制,可以用volatile时间可见性解决),不可重复读的问题(一般不影响结果,也不需要解决)
3.并发写写,会出现丢失更新数据的问题(因为线程会互相覆盖彼此的更新数据,所以就会丢失更新数据),要想解决该问题就要实现并发线程的互斥 ,可以用无锁来实现,也可以用有锁来实现
JUC并发编程的整体知识脉络(知识体系)
JUC并发编程学下来给我的感觉就是解决并发过程中出现的三大问题,如何保障原子性,可见性,有序性 ,除此之外还有线程间的通信方式,各种通信模式的应用(保护性暂停模式,生产者消费者模式…),最后还有并发工具类的使用,诸如线程池,各种原子类,线程安全的集合等
1.原子性
A.就是因为没有保障原子性,才会出现线程的交叉执行,指令的交叉执行,从而出现线程安全问题。解决原子性的方案有无锁->有锁(偏向锁->轻量级锁->重量级锁,其中重量级锁有两种典型的实现,Monitor监听器和ReentrantLock,前者是利用操作系统底层的互斥来实现的,后者是利用AQS+CAS算法实现的)
B.一般有限采用无锁实现,因为无锁实现一般要比有锁实现性能高,具体原因上面讲无锁实现已经很详细了就不再重复了,但无锁实现有个致命的缺点,无锁只能实现单个共享资源的线程安全对于多个共享资源就难以实现,此时只能使用有锁实现来解决了。有锁实现,如果锁的范围非常大的话,那么并发度就会非常低,如果更好细化锁的范围,控制好锁的粗细度,才能让有锁实现有更好的性能,这是一个难点也是有锁的优化思路
2.可见性和有序性
通过violate关键字可以保障有序性和可见性,有序性就是cpu访问内存而非缓存,让线程能获取最新的数据而非缓存的旧数据,可见性就是防止指令重排序造成的数据问题。具体的原理可以去看violate的原理
3.线程间的通信
主要是通过wait/notity,await/singal,park/unpark来实现线程间的通信,具体的原理可以在上述笔记中找到
4.线程池
线程池主要是应用了典型的享元模式实现大量重复线程资源的复用+生产者消费模式实现线程间的通信+线程安全的阻塞队列
5.各种封装好的无锁实现线程安全的原子类,还有线程安全的集合等,值得注意的是线程安全的集合的了解还非常浅显,需要好时间深入学习和理解
多线程在项目中的应用 伙伴匹配系统的第六期:https://meeting.tencent.com/v2/cloud-record/share?id=65c1d5f7-8465-4c70-99bb-eb3e148ceb0c&from=3(访问密码:wr5M)
Mysql批量插入100W条数据的开发思路
关键思考点:罗列主要的性能影响因素,通过测试实践发现性能瓶颈究竟卡在那了,是CPU核数,网络io还是数据库本身是性能瓶颈
批量插入数据的性能影响
1.并发性对批量插入数据的性能影响
2.网络IO资源,比如建立多少次数据库连接,传输带宽等因素
3.数据库方面,比如SQL语句,数据库配置等等
4.磁盘io
批量插入数据性能测试
批量插入
后续要单独测试每次批量的数据量不一致,看看对性能的影响,主要是看网络传输的带宽对性能的影响
批量插入
一次传输数据量 1w 1w/10w 1k/1w/10w/100w 1w/10w/100w
3.05s 17.2s/17.04s 132s/130s/111s/130s 2083s 接近34分钟/
多线程+批量插入100w条数据对性能的影响
一次批量插入的数据量是1w条
100w条 数据,固定10个线程,测试多线程+批量插入的batchSize对性能的影响
一次传输数据量 1k 1w 10w
27s 42s 48s
经过实践测试,暂时有以下结论
2.批量插入的数据量大小如何确定,通过一次次调整批量插入的数据量大小对性能影响,最终得出一个性能较高的数据量大小。但带宽对性能影响不是很大,可能就是8/1-10/1的优化吧
小解读:带宽越大,需要建立的数据连接越少,所以关于网络带宽和数据库连接要综合考虑以及多次测试才能得出一个恰当的数据
鱼皮小tips:极限值是数据库连接资源最大化利用+带宽资源最大化利用,当然千万不要在生产环境这样弄,上来就占用那么多资源,其他需要资源的功能怎么办,而且推荐测试循序渐进,数据量逐渐增多,可以及早发现的问题,不然一上来数据量就这么大,问题一出就会很严重
3.多线程(线程池)+批量插入。线程池中的核心线程数,最大线程数应如何确定?
关于核心线程数,最大线程数如何确定的问题,这里借美团技术团队的文章来浅答以下(我自己的水平有限)
通过阅读美团技术团队对线程池参数的解读,发现线程池的参数是很难有一个标准答案,不同的业务差异是非常大的,不同的任务类型差距业非常大,所以美团选择了一个折中的方案,就是动态化+实时监控线程池的状态,根据实际业务状况实时调整线程池的参数
4.确定了线程池的核心参数后,那么业务实际分配的线程数又该如何确定呢?
我从鱼皮视频中学到的思路就是不断的测试,实践才能得到真知,线程数,数据量逐渐增大,每个层级的线程数和数据量进行测试,当经过了大量的测试后,得到一个较为恰当的答案应该是没问题的
实验中的测试案例
其实你会发现多线程到15个的时候,无论再怎么增加线程数,性能都不会有多大变化,证明性能的瓶颈到了,且瓶颈不是线程数的问题,也不是数据库连接数的问题了(因为已经用批量插入优化了,也测试过了),很有可能就是数据库同一时刻只能处理这么多插入数据,是数据库本身的性能瓶颈到了,但是多线程对比单线程性能是足足提高了50%-60%,至于业务实际要分配多少个线程数,我想没什么比实践的结果来得更可靠,一次一次测试,直到得到最恰当的数值,自然就是业务所需的实际线程数分配了
5.遗留的问题
进一步深入领悟学习方法 问题
在学习JUC并发编程时发现我对每一个知识点都学习的非常的零碎,完全无法串起来,每个知识点的知识体系完全无法搭建起来,学起来非常的乱,东懂一块西懂一块的
解决方案:使用是什么,为什么,怎么做三步学习法(无论是在输入还是)
深刻的领悟到学习(输入)一个知识为什么要遵守是什么?为什么?怎么做这三步学习法了,体会到三步学习法对于学习的重要作用,简单用一句话概括就是在输入知识时可以帮助我们带着问题去学习,引导我们主动去思考的学习。在输出知识时可以帮助我们以层层递减(是什么,为什么,怎么做..)的关系将琐碎的知识点串联起来形成一个小的知识体系
更深入的体会到他的作用不仅是在输入的过程让我带着目标去学习,引导我们主动思考而非被动思考,还能帮助我们把零碎的知识点以逻辑的层层递进关系把零碎的知识点串联成一个小的知识体系, 形成某一个知识点的知识体系对学习和理解该知识点起到了至关重要的作用
疑问
知识点内部的零碎知识可以使用三步法串联起来,但大的知识点与知识点如何串联起来呢?如何找到他们的关联呢?只有将每个章节的知识都串联起来才能形成该技术 or 学科的完整 知识体系,在这一点上我尚且较为模糊,不知道具体怎么找到他们之间的关联
操作系统聊天课程设计问题 1.如何在泛型集合中添加泛型元素时选择添加其泛型的子类元素?
泛型本身就支持集合中添加其子类元素,但如果是泛型中包含泛型,想要支持被包含泛型中的子类元素添加,就需要将泛型设计成<? extend 父类> 或者将泛型设计成< ? >,前者是类型上限是父类,后者的类型上限是Object
2.关于泛型结合继承实现类型动态化还是有待深入学习
在仔细琢磨了一个小时后发现泛型是编译时行为,也就是编译时就需要知道准确的类型。而多态是运行时行为,只有运行时才知道实际的类型,二者可以结合使用,典型的jdk8的函数式接口就是二者的结合体。函数式接口既可以实现参数类型的动态化,又可以实现运行时的动态绑定
综合上述的理解,泛型是用来实现编译时类型的动态化,而多态是用来实现运行时类型的动态化,二者的侧重点和应用场景不一样。编译时类型的动态可以借鉴mybatis-plus的BaseMapper的泛型继承体系进行学习,完全是一致的
但我发现如果泛型结合多态使用(即实际的类型是泛型包泛型的情况),如果将对应的实例加入到容器中时,容器是很难识别嵌套泛型的类型的,当你从 容器中获取元素时,就会发现嵌套的泛型只能被识别为Object类型,这样等于是要自己做好类型检查的防范工作,否则就会类型转换异常
3.解决方案:泛型+多态结合使用就不应该再结合容器使用,因为容器识别不出嵌套泛型的类型,会有可能出现bug,我的解决方案是去掉泛型
现在我把类的泛型去掉了,不需要泛型实现动态类型的变化,而是在接口方法参数中使用顶级父类接收类型(如果是泛型的话接口方法的参数则是泛型参数),再在具体的子类中进行类型转换即可,也可以实现动态类型的变化
4.关于函数式接口的深入理解,函数接口实际上就是泛型+多态+面向接口编程的思想 ,其中泛型是如何指定的呢?因为其泛型是加在接口上的,只要在实现类中指明泛型的类型即可,如果使用Lambda表达式的话,可以在方法参数上显式指定参数类型而不是用他的类型推断,返回值可以使用其类型推断,因为非常的明显
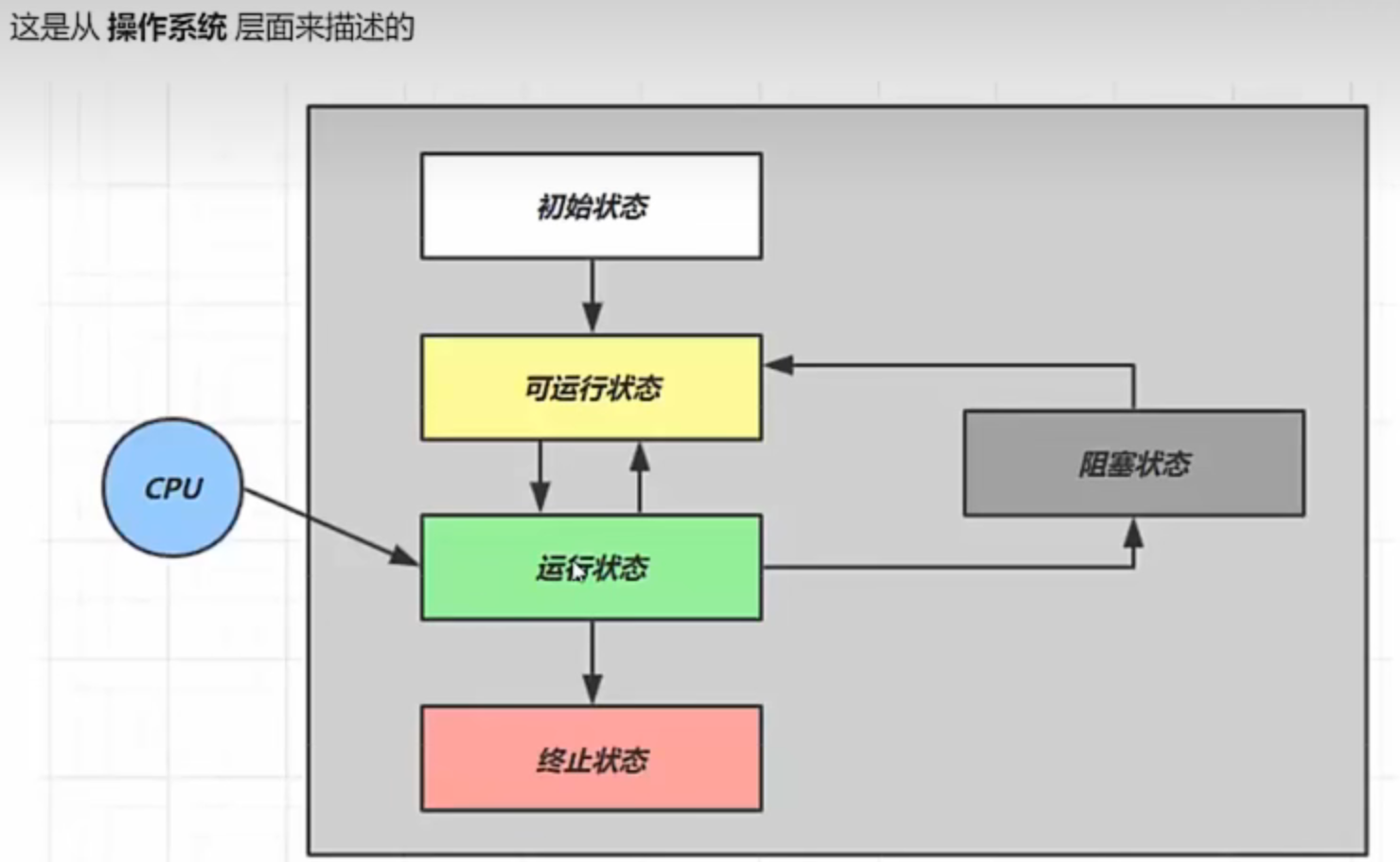
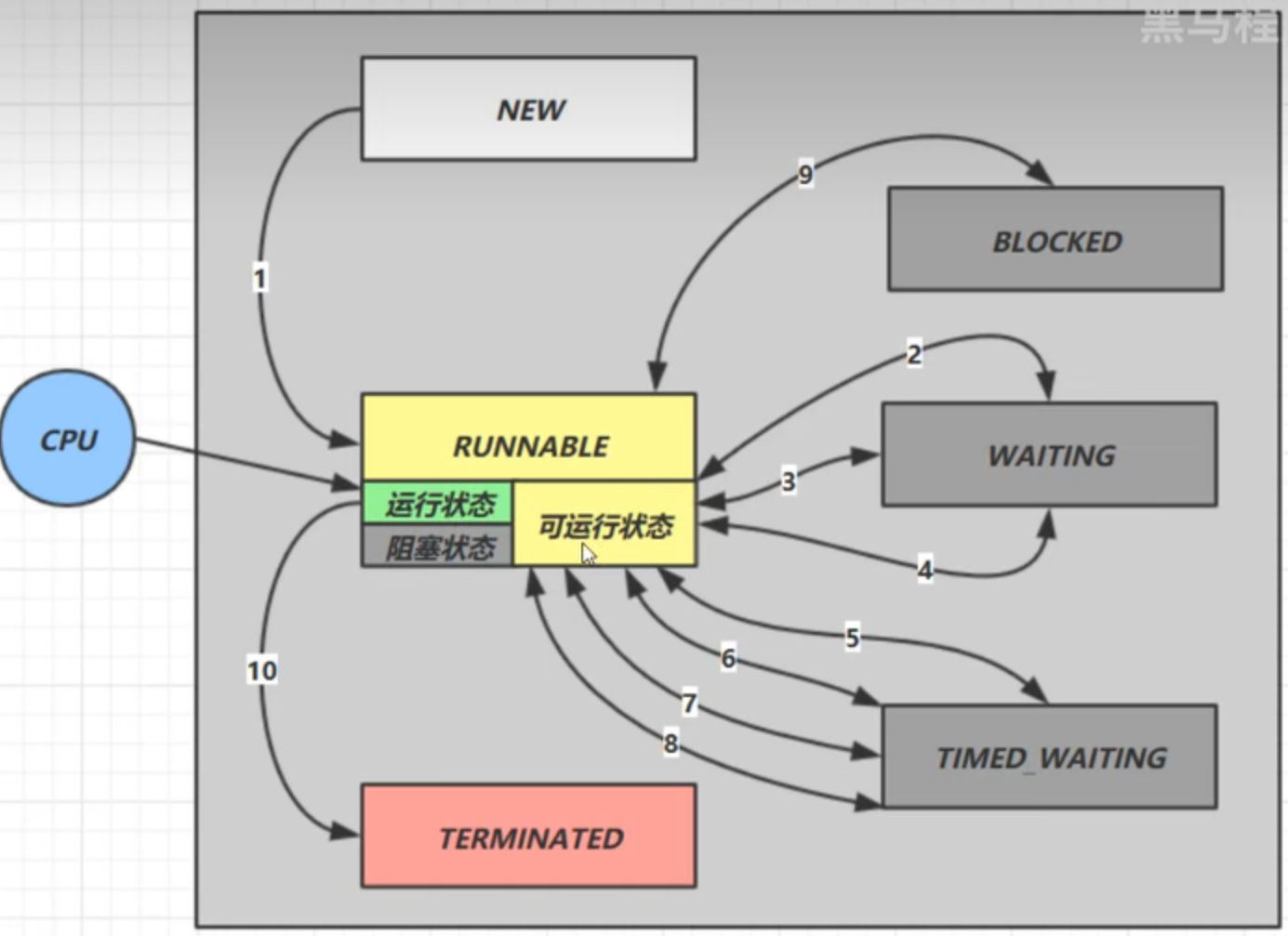
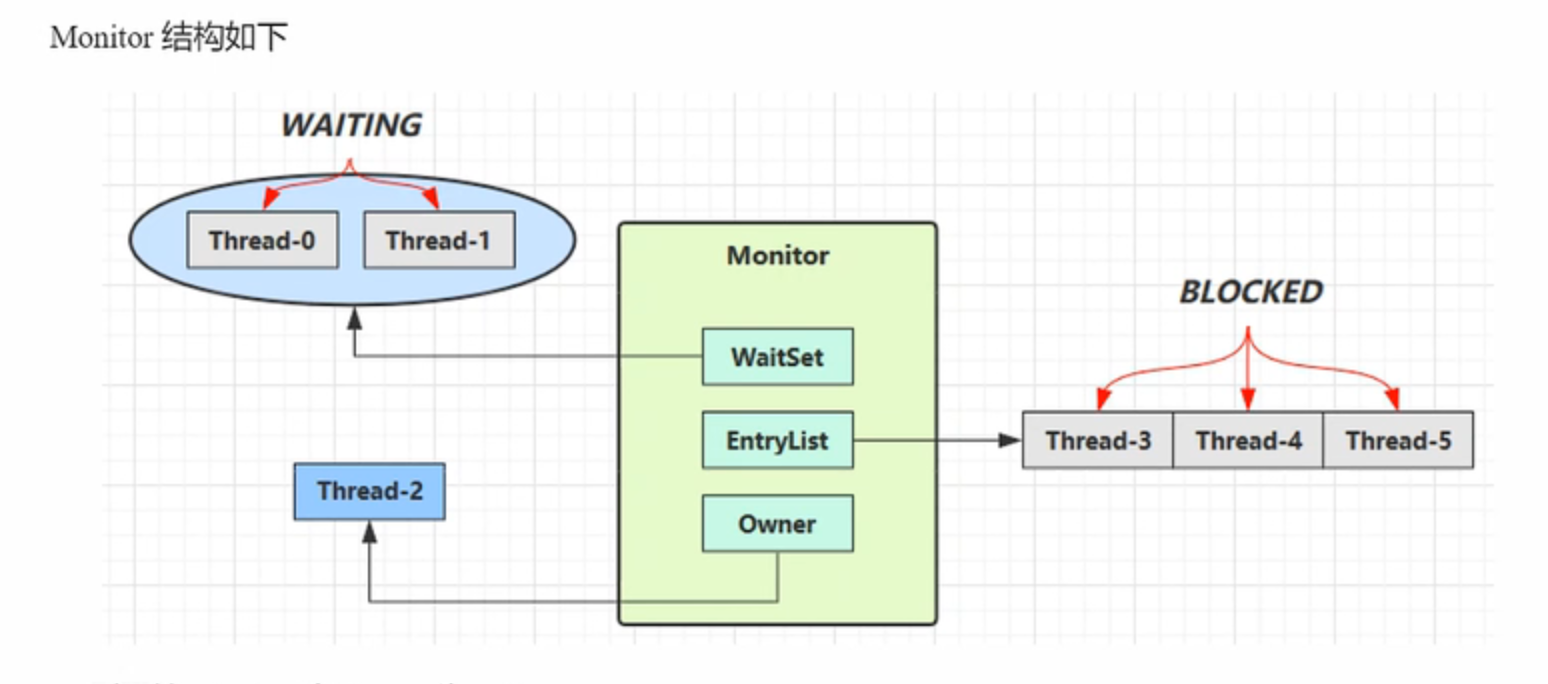
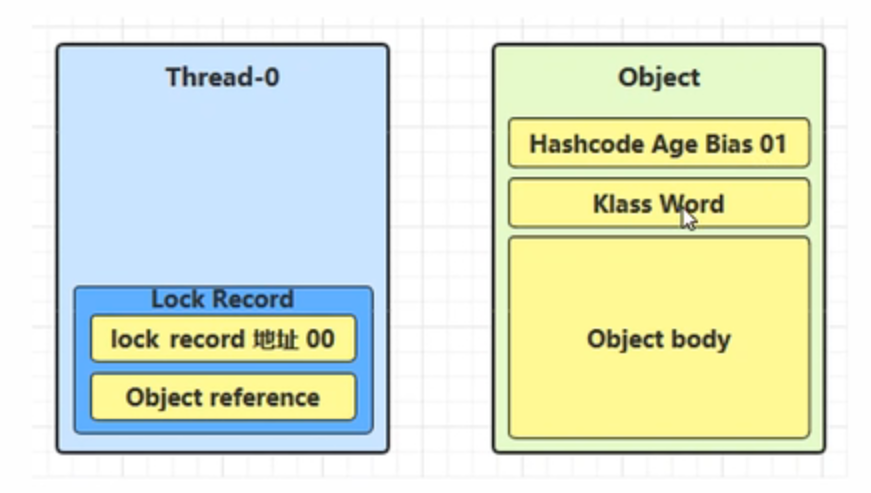
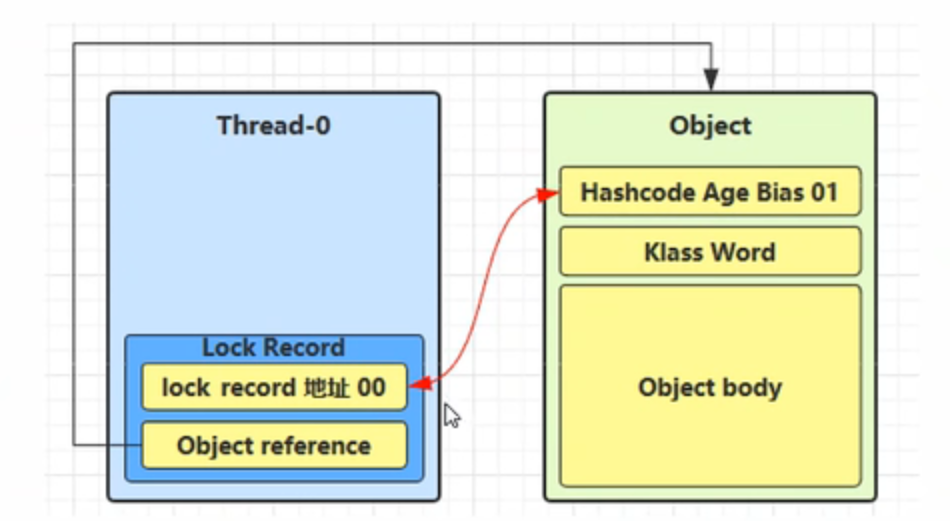
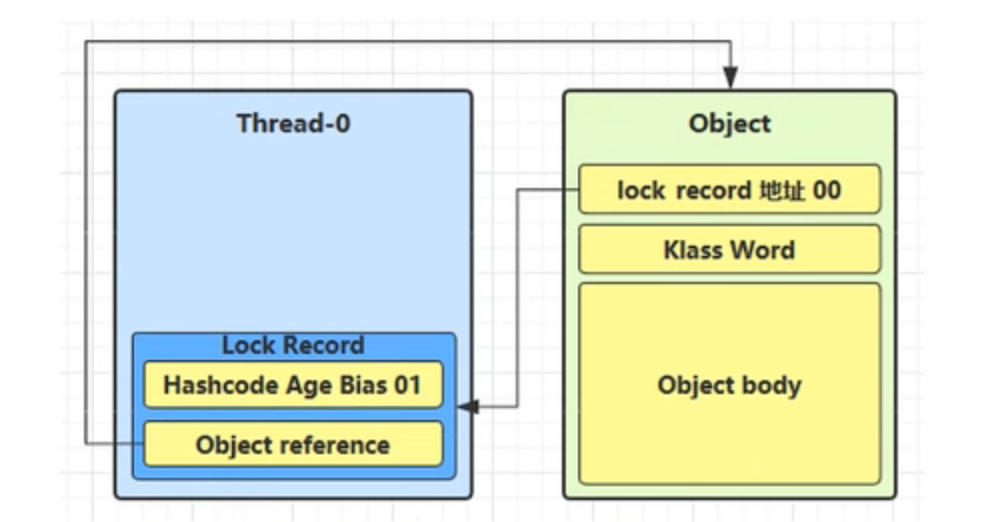
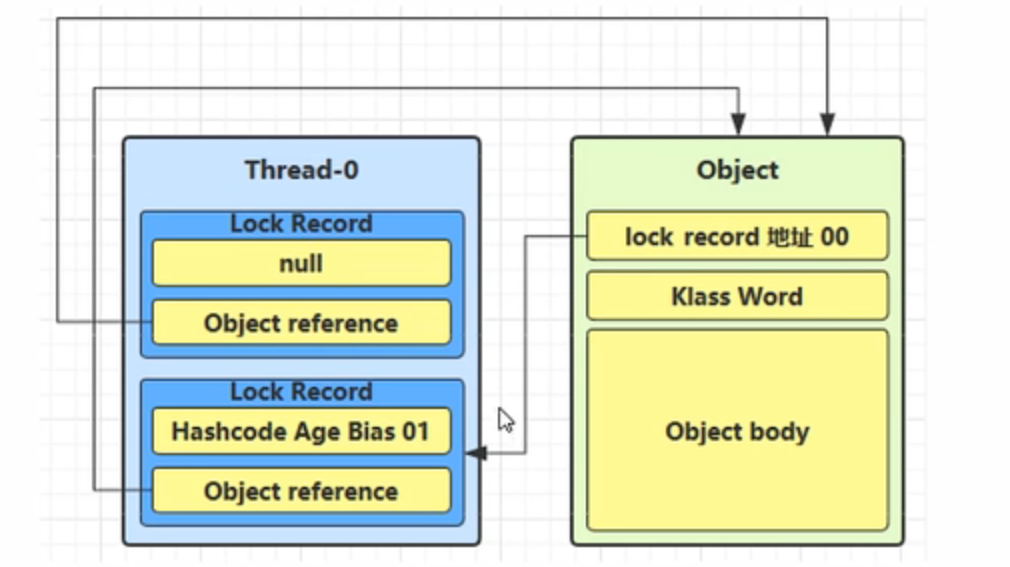
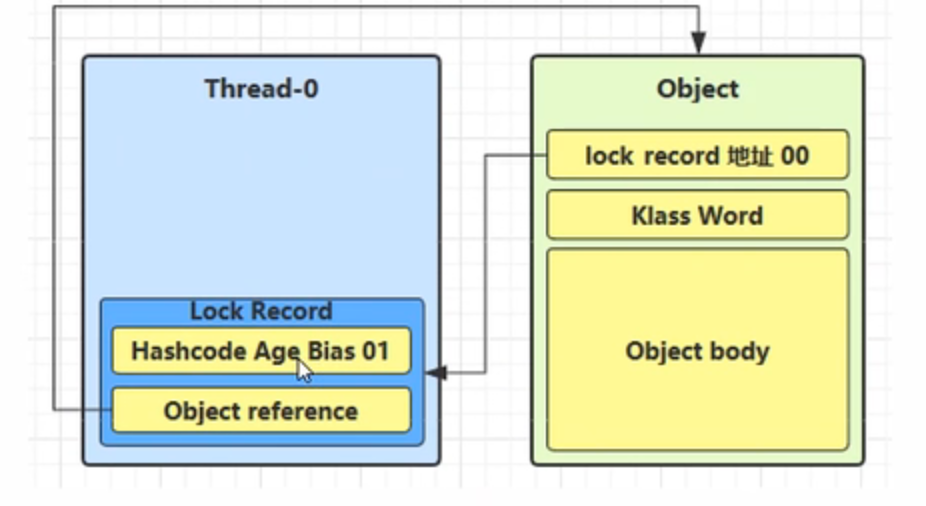
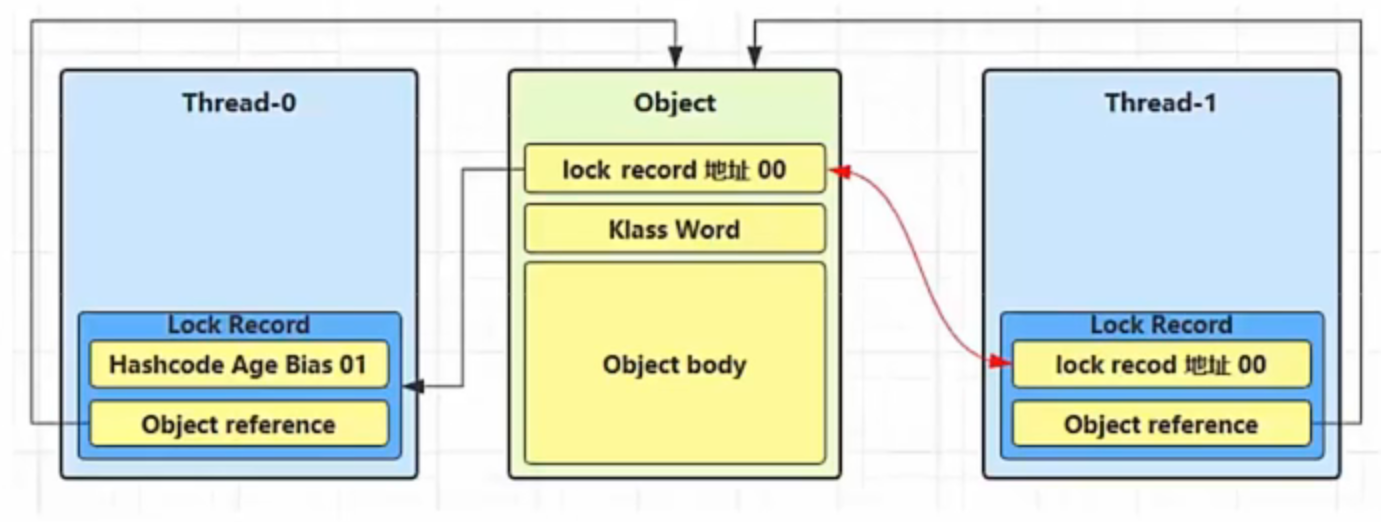
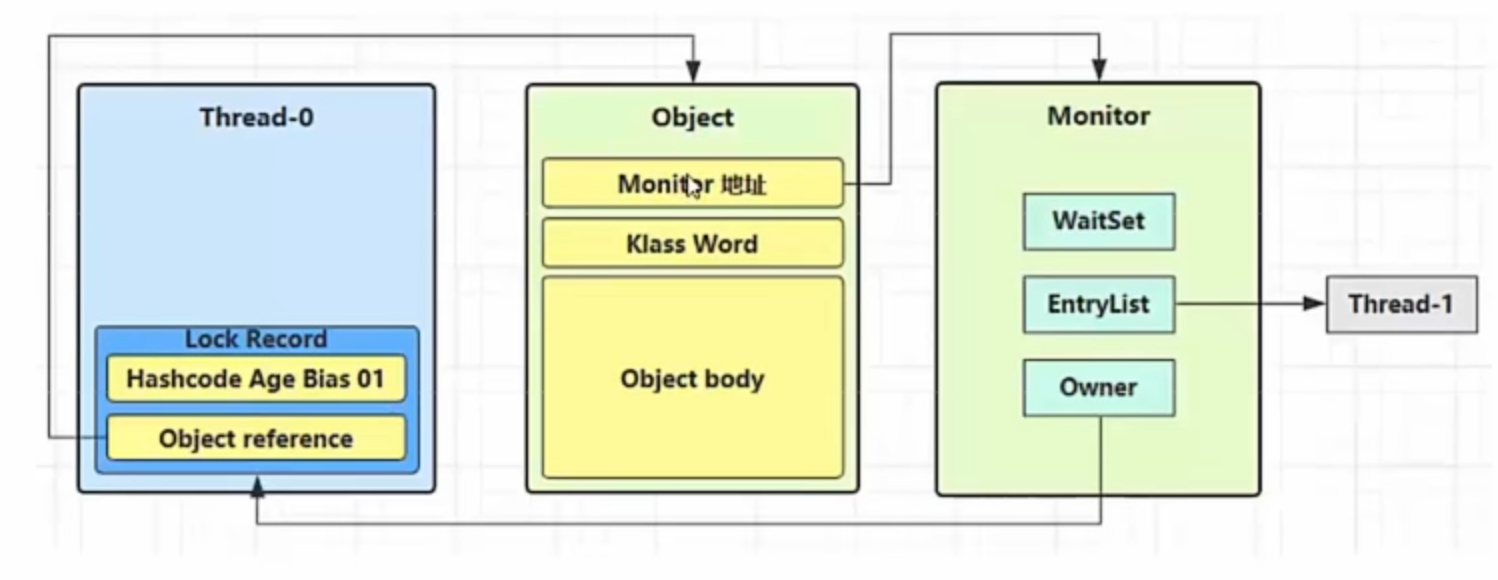
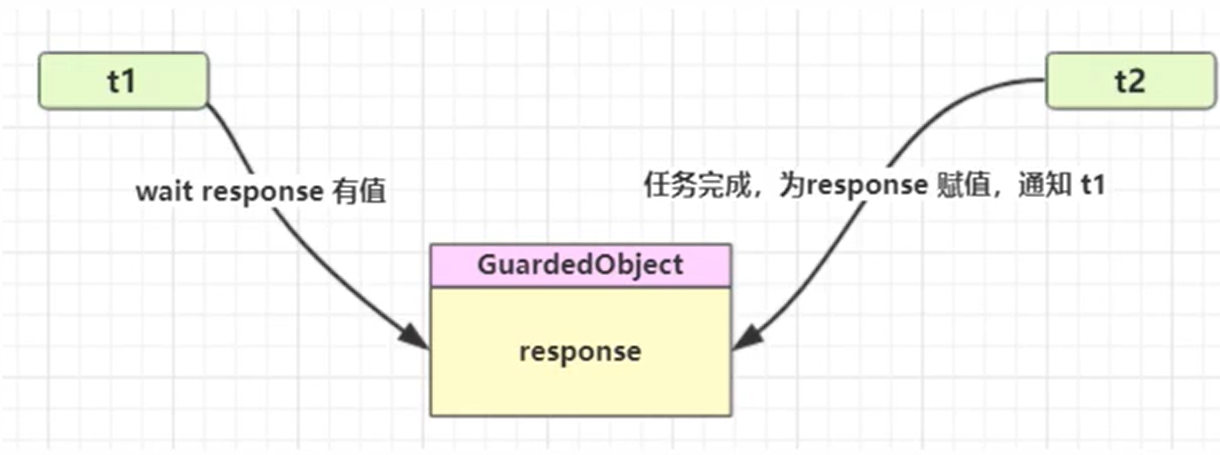
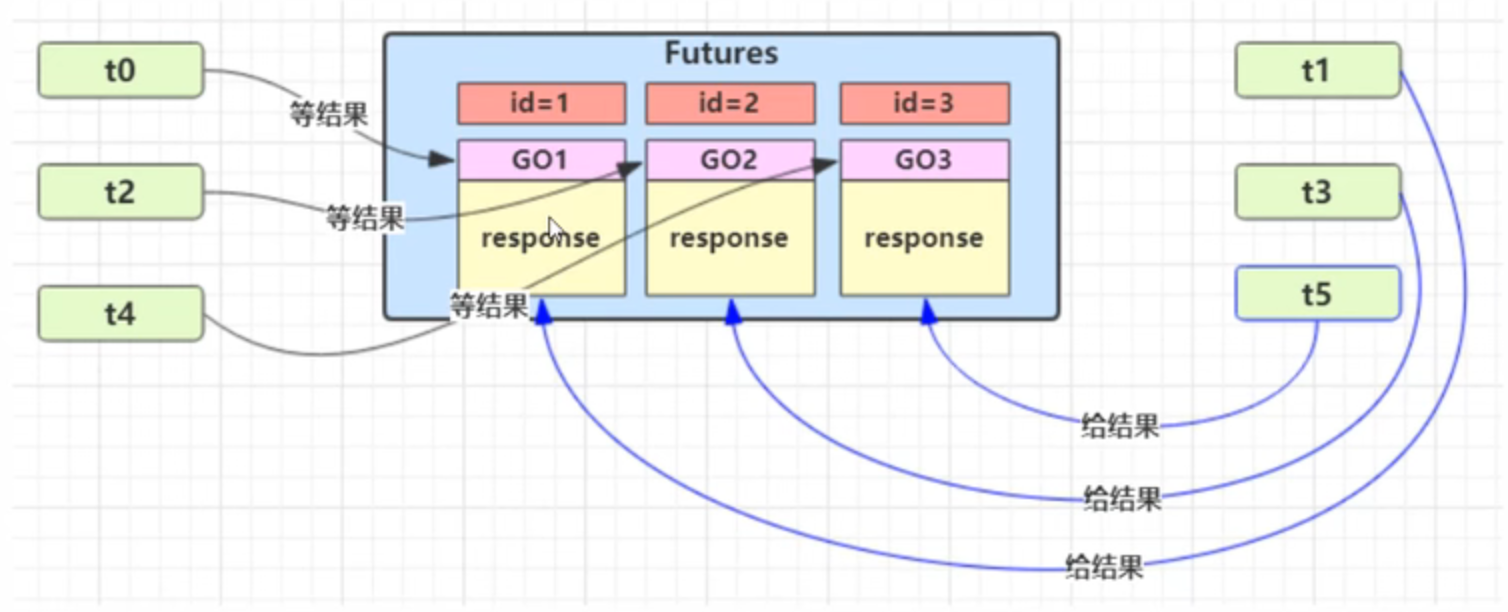
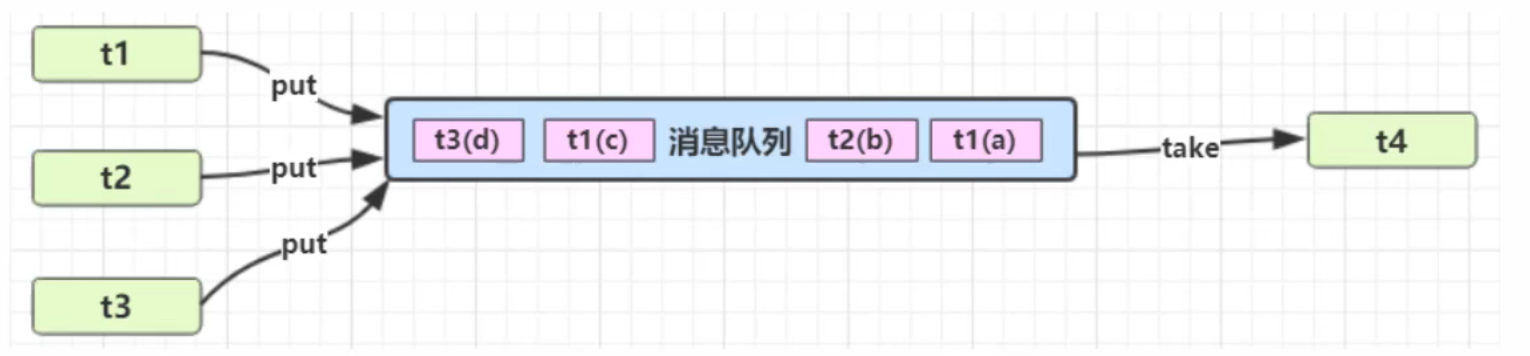
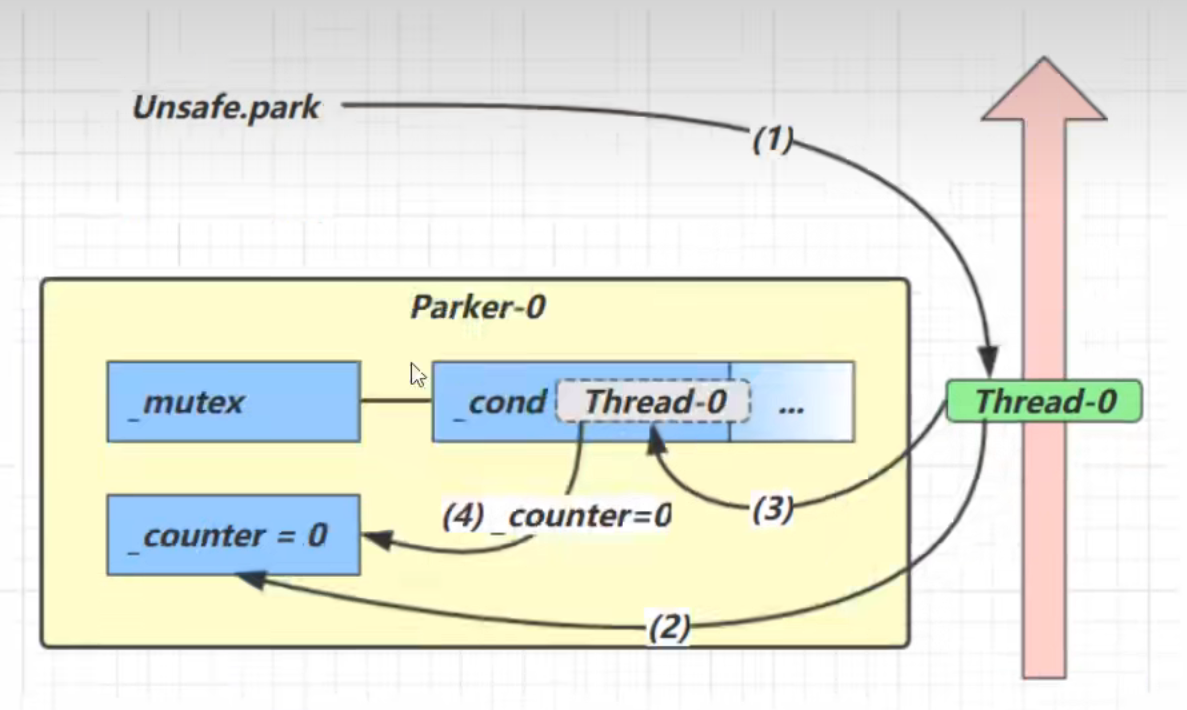
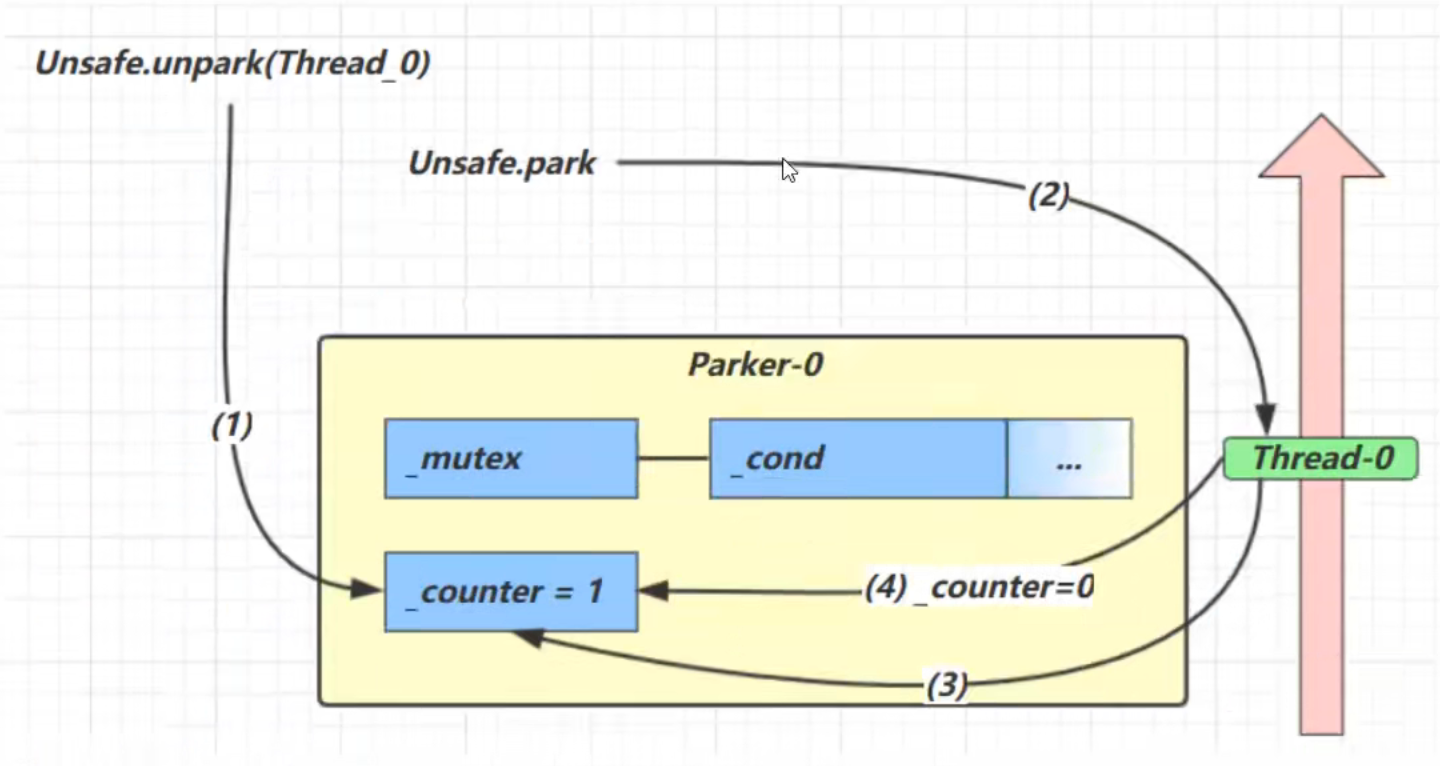
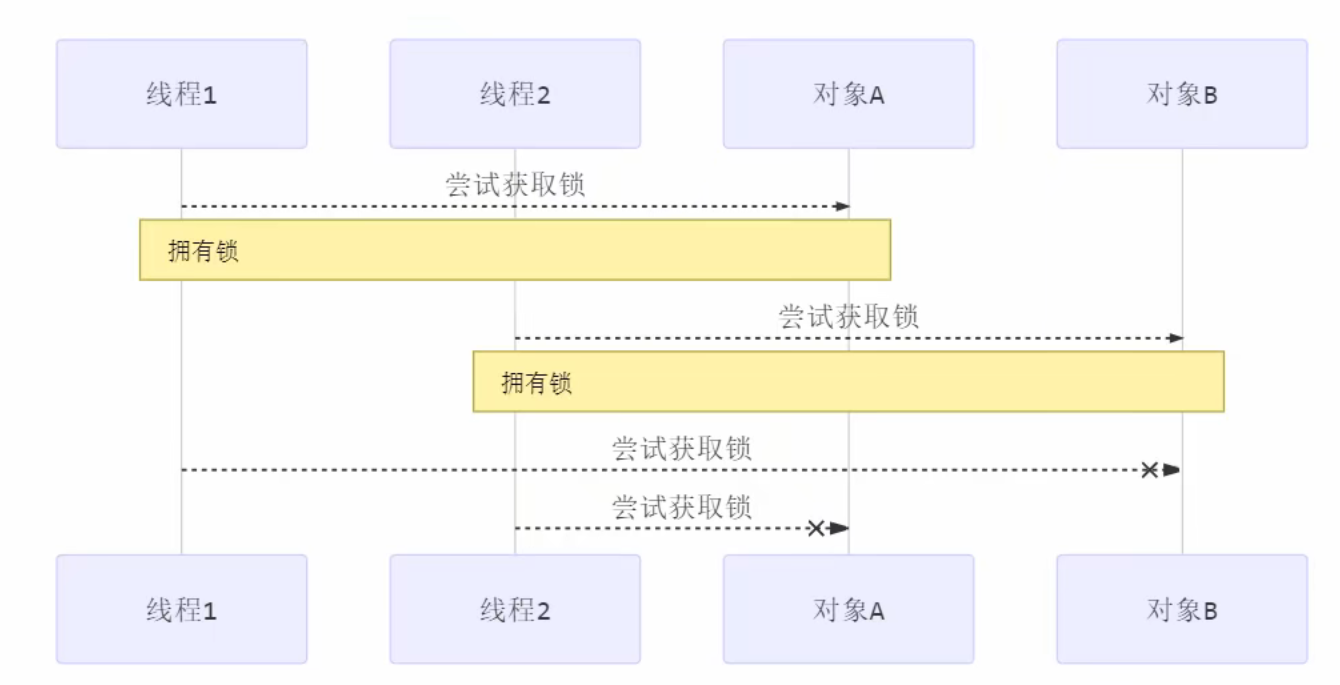
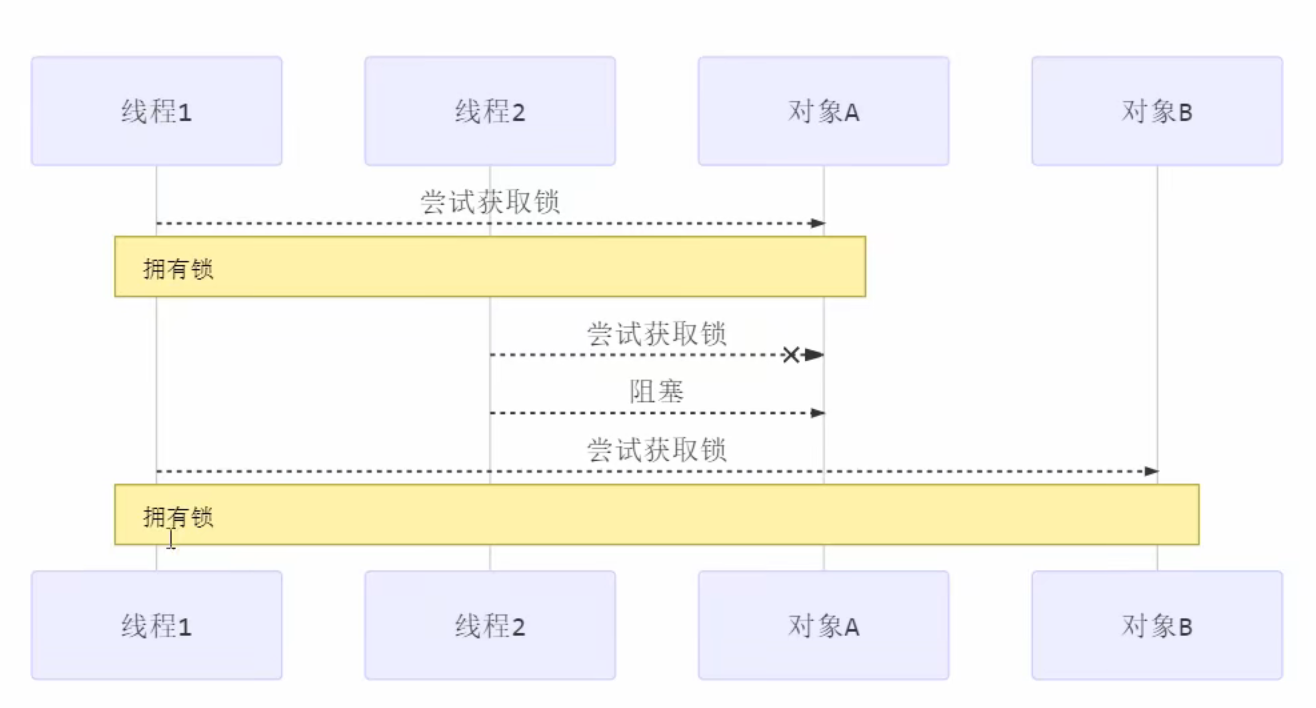
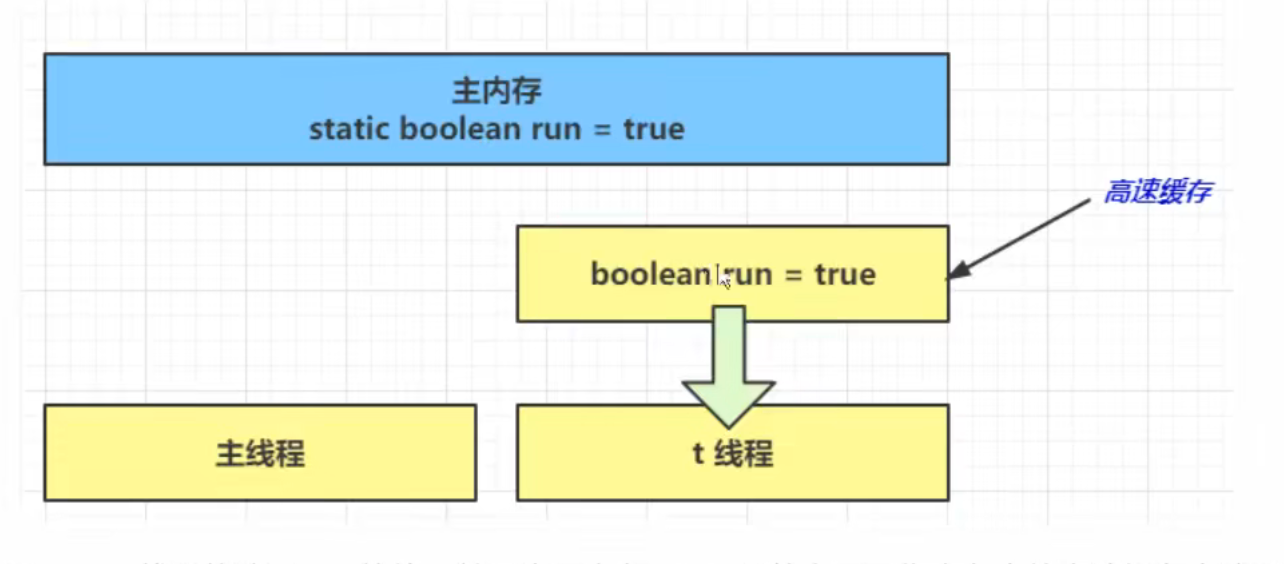
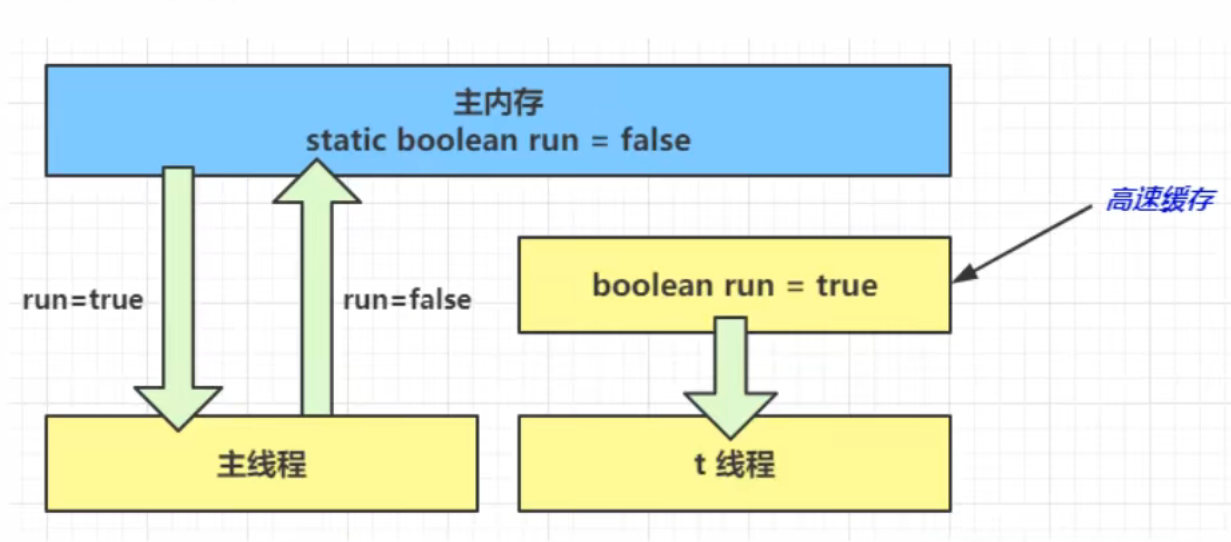
.png)
.png)

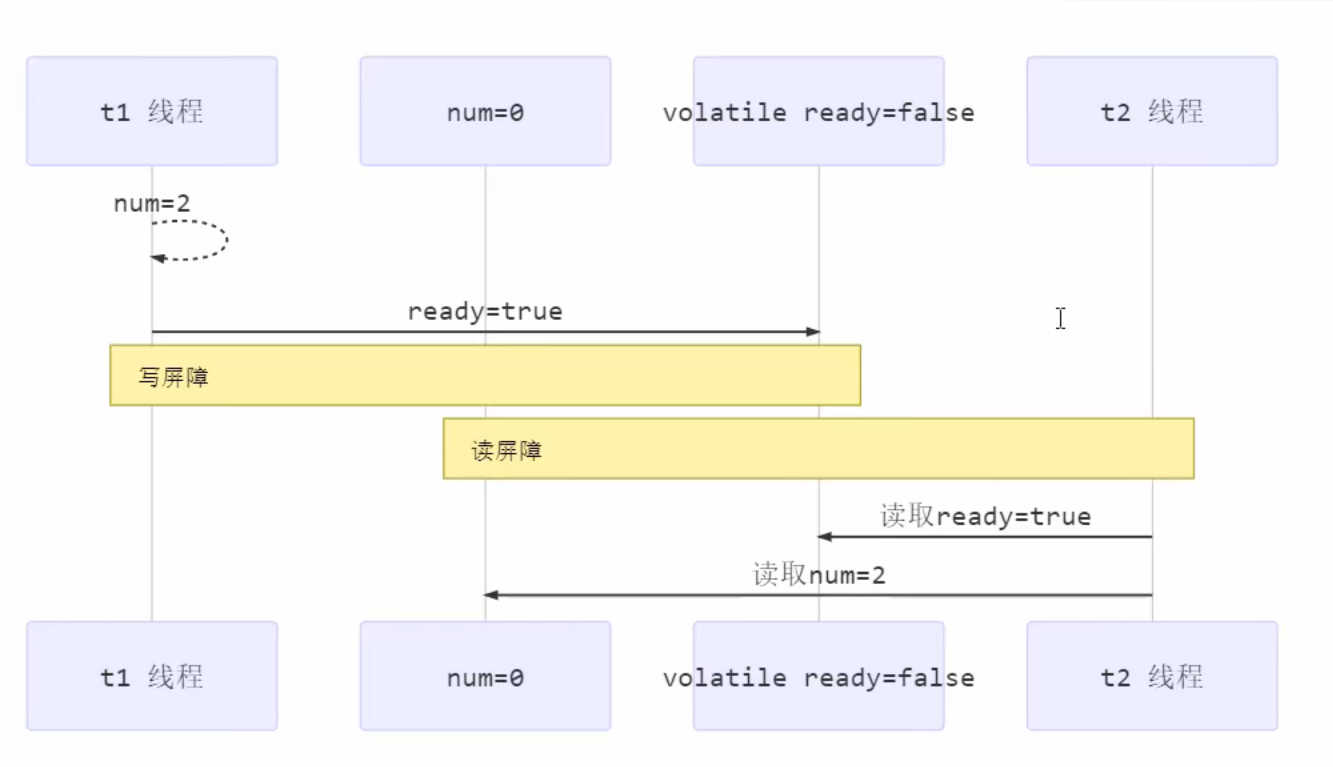
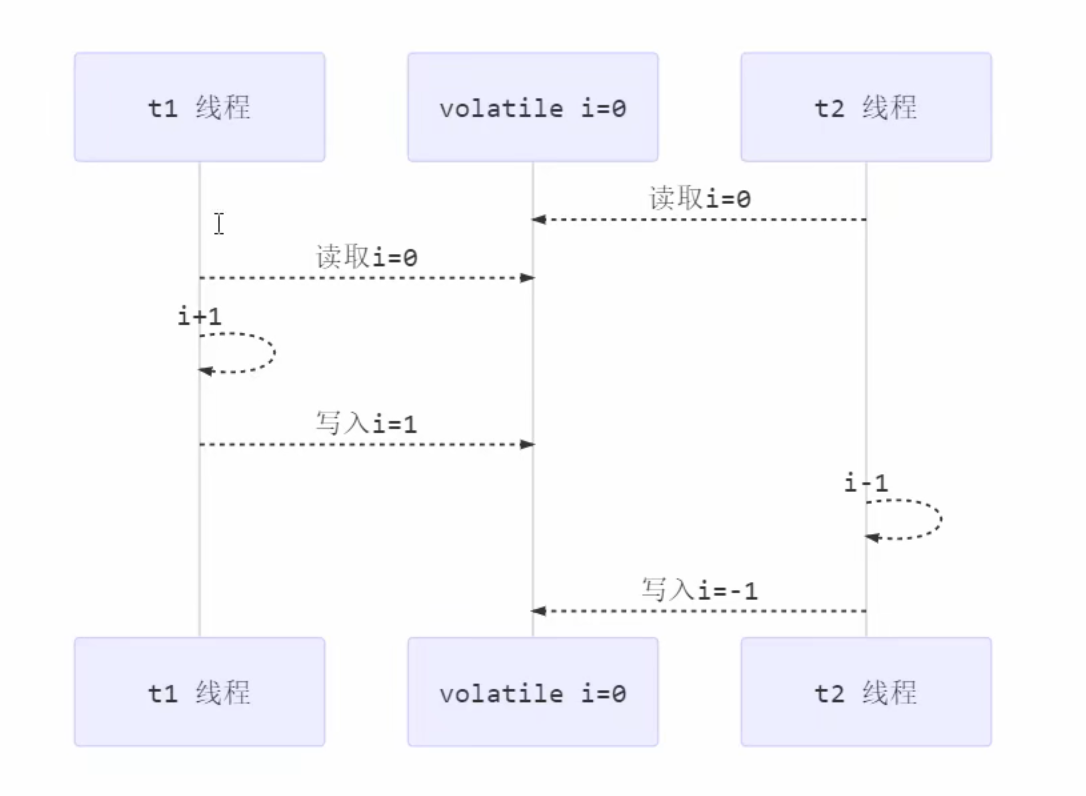
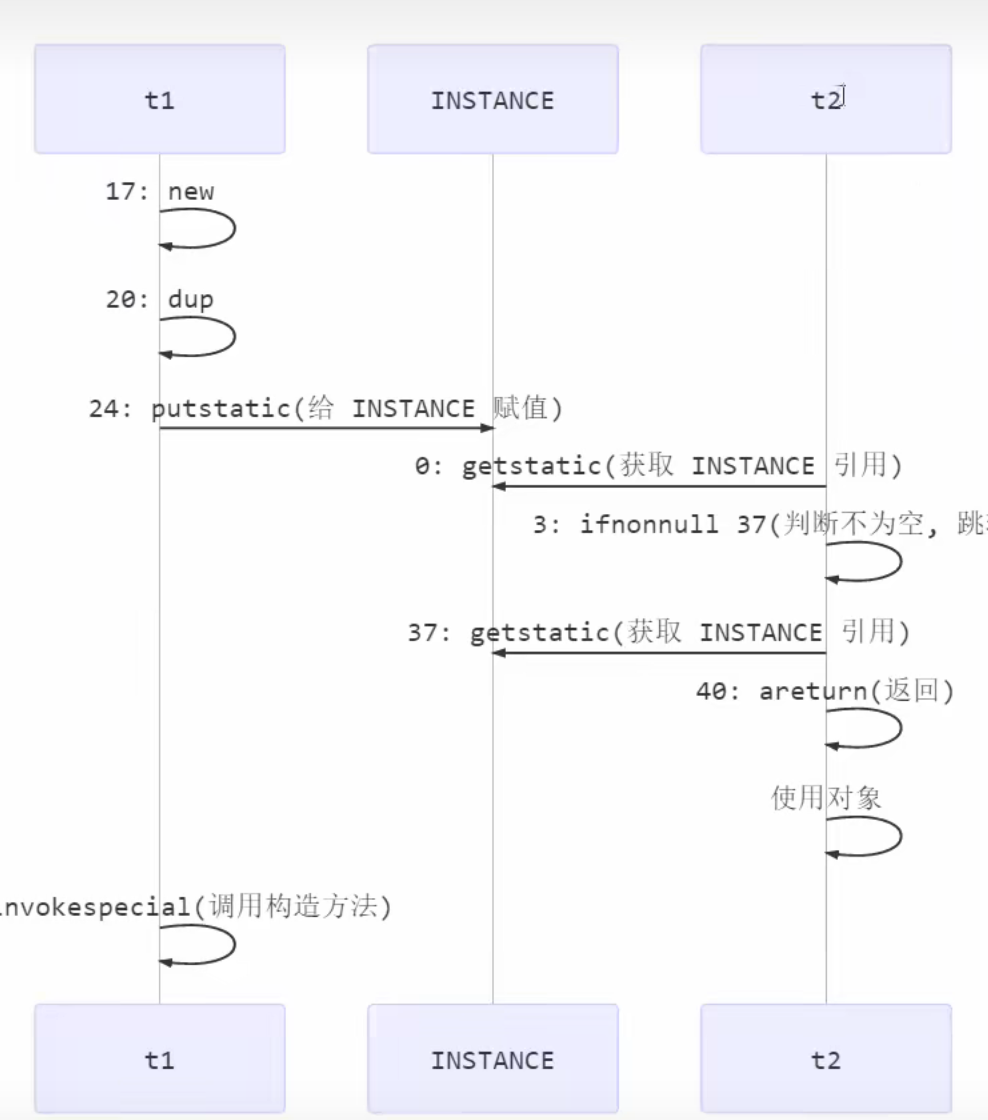
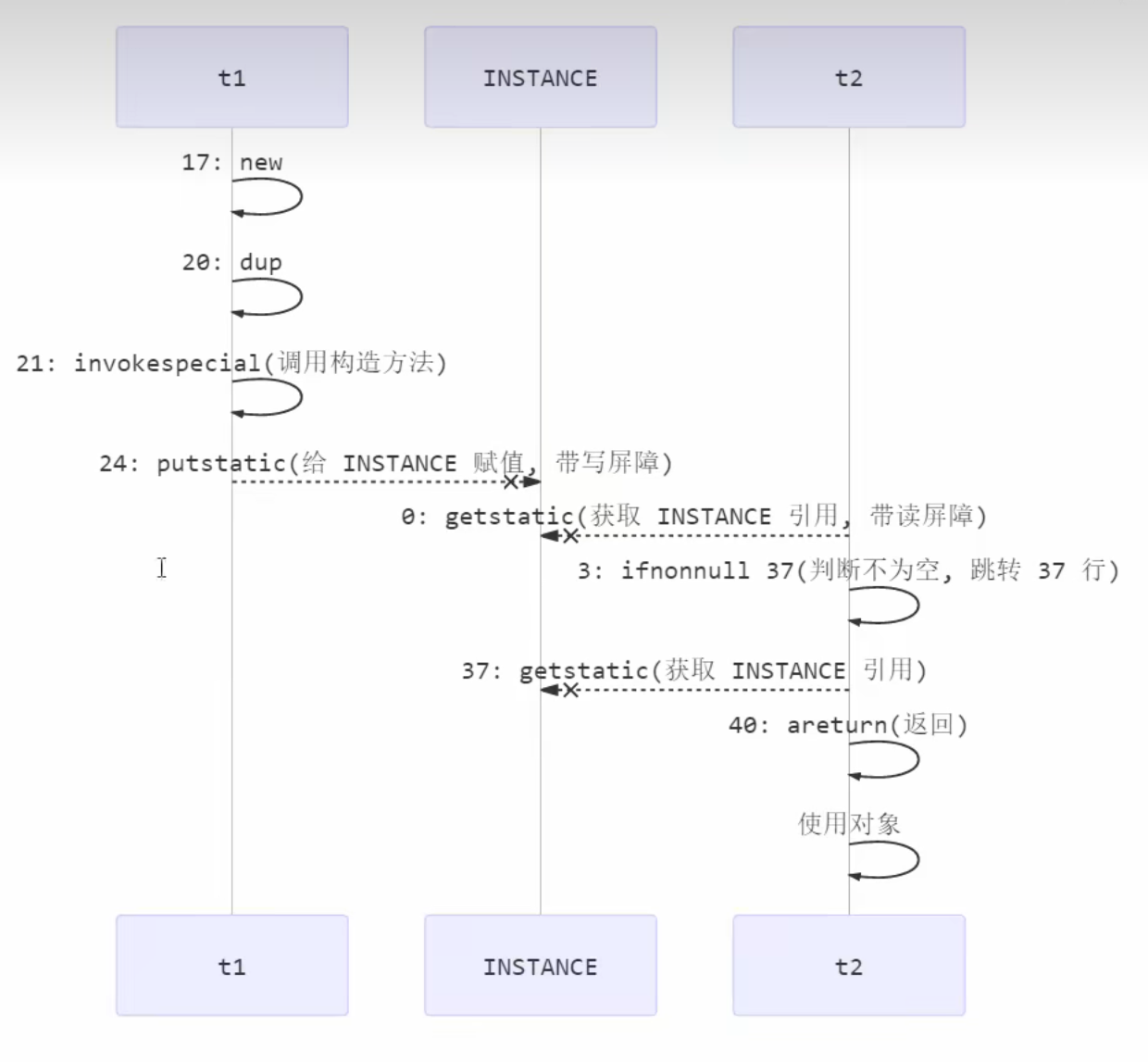
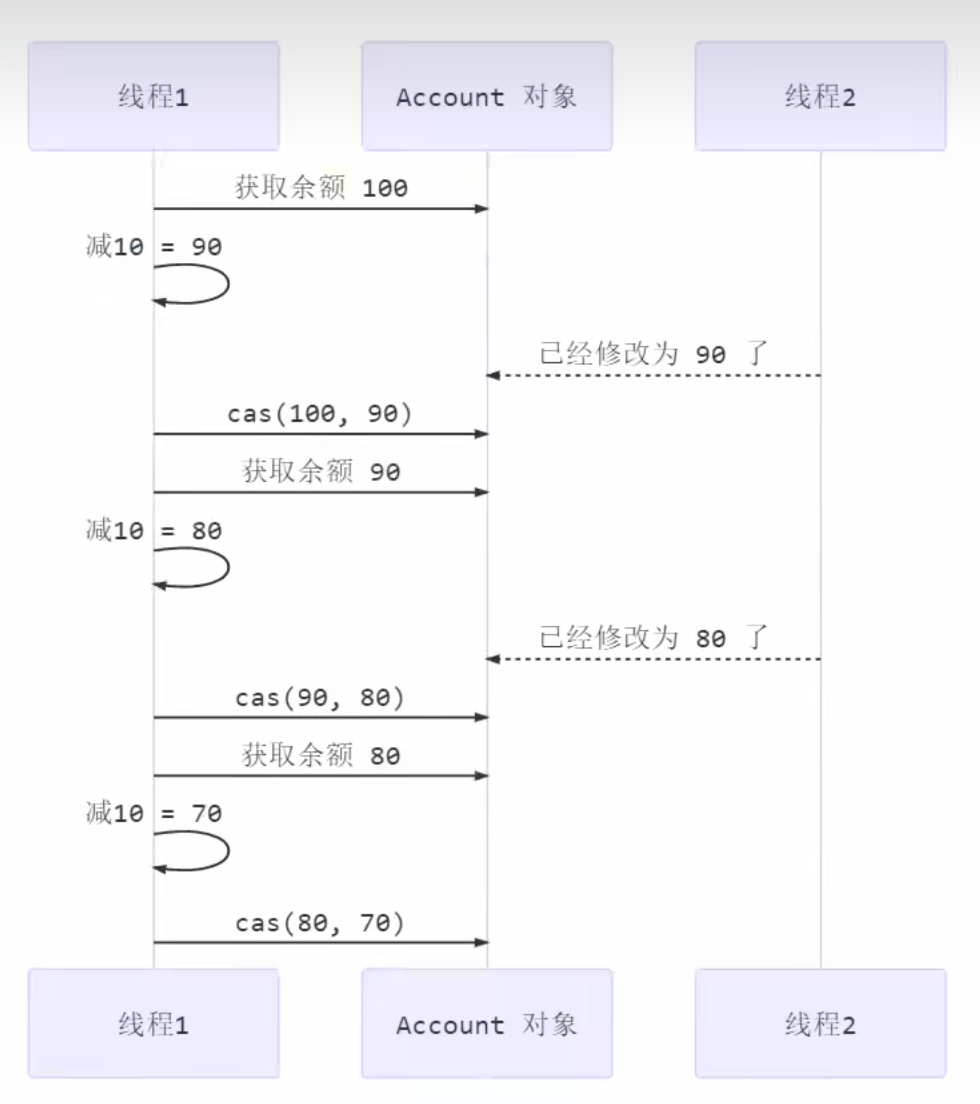
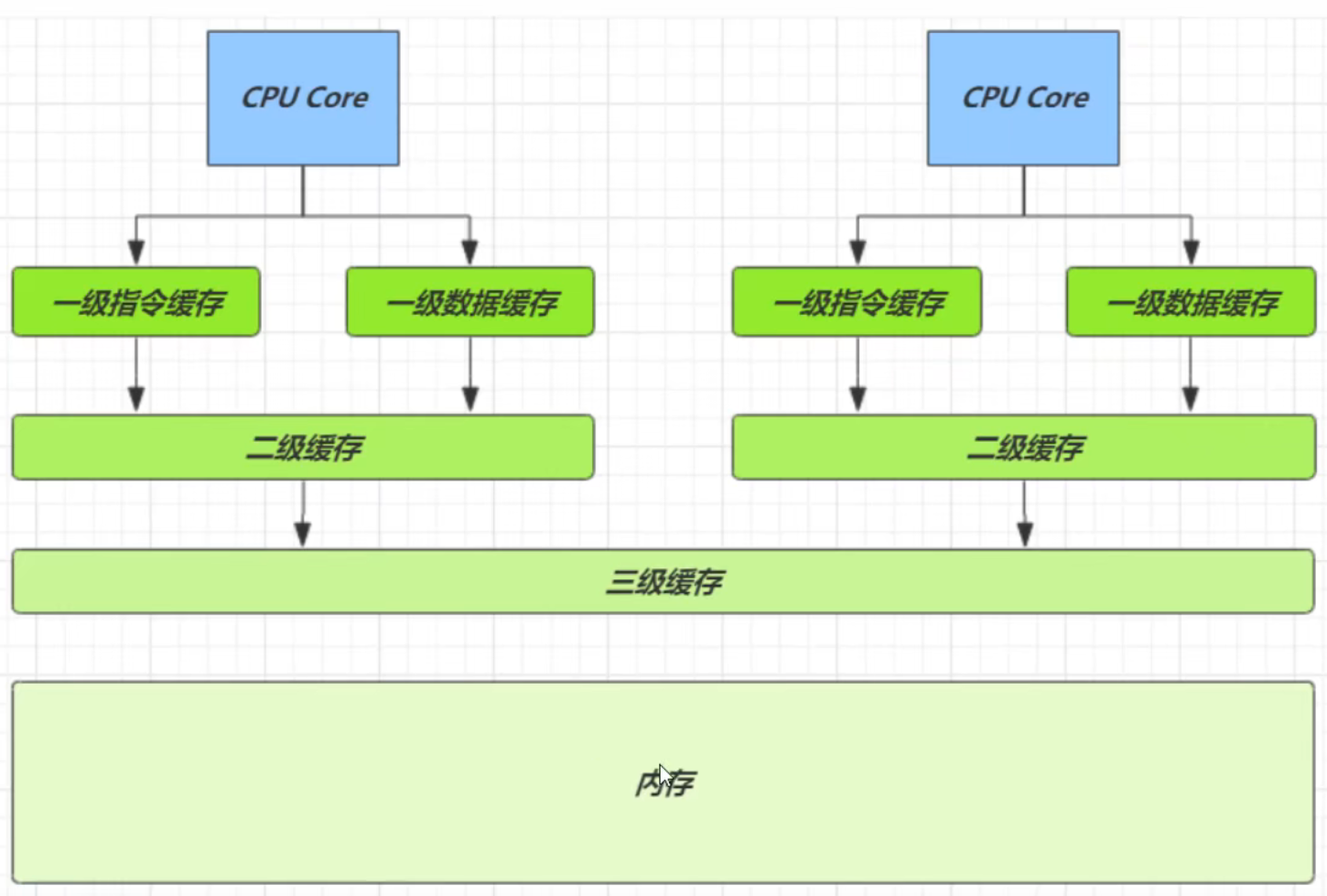
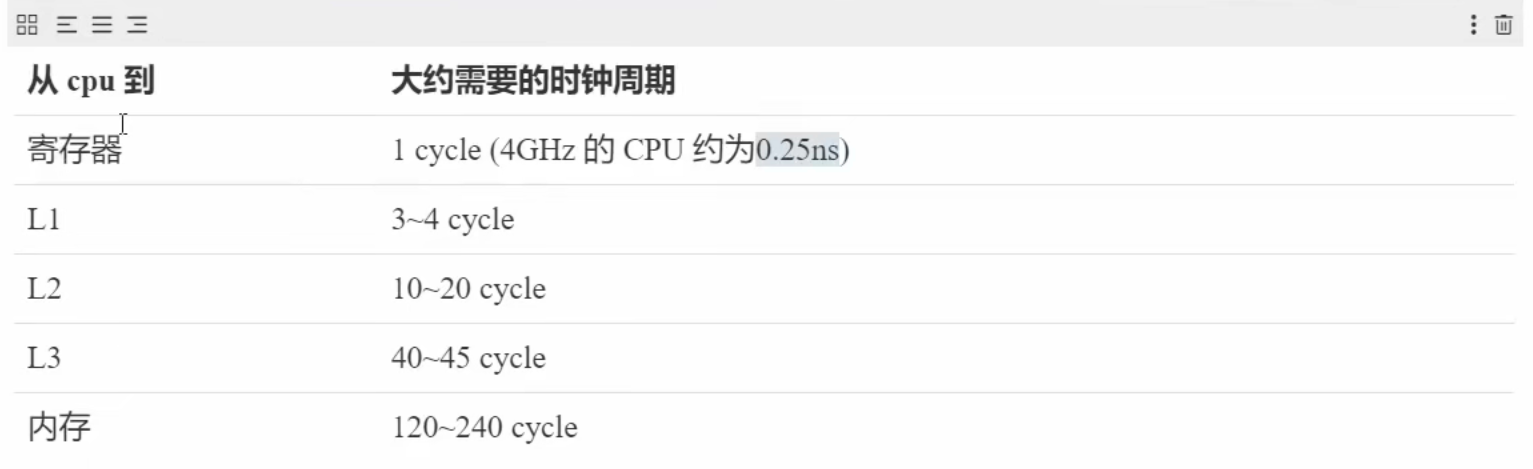
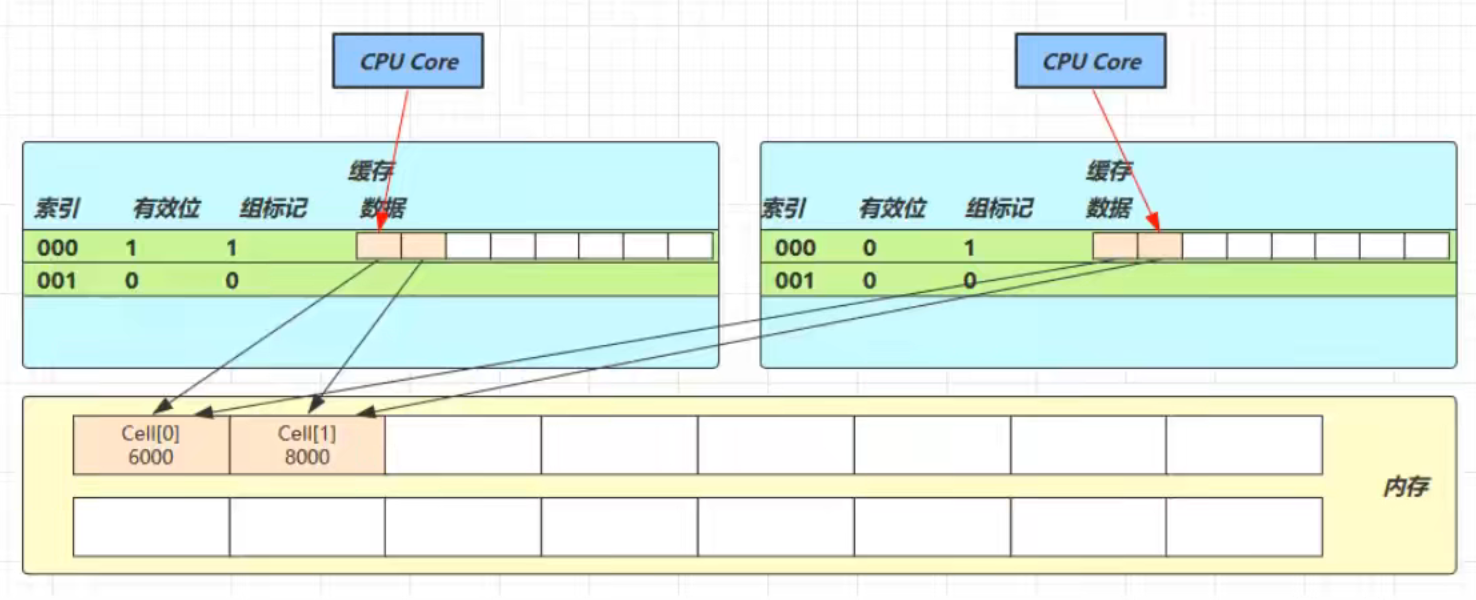
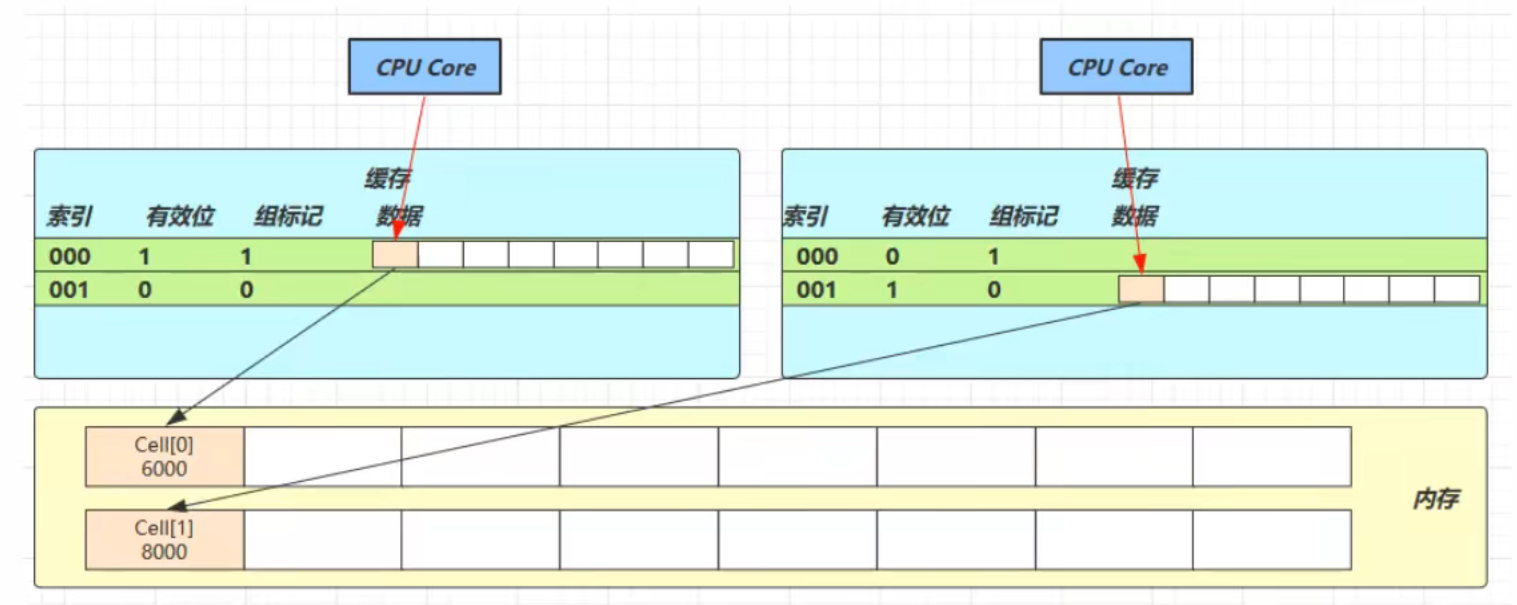

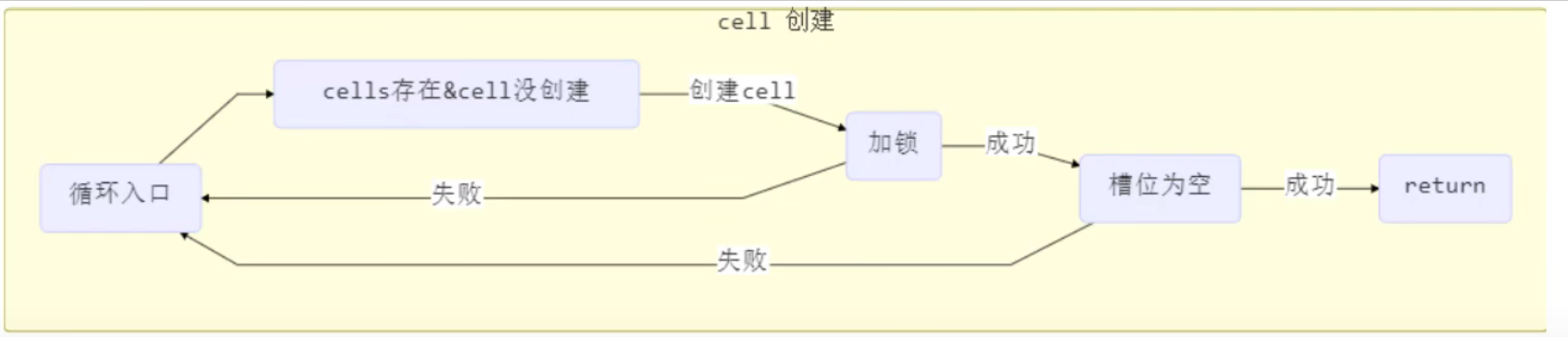
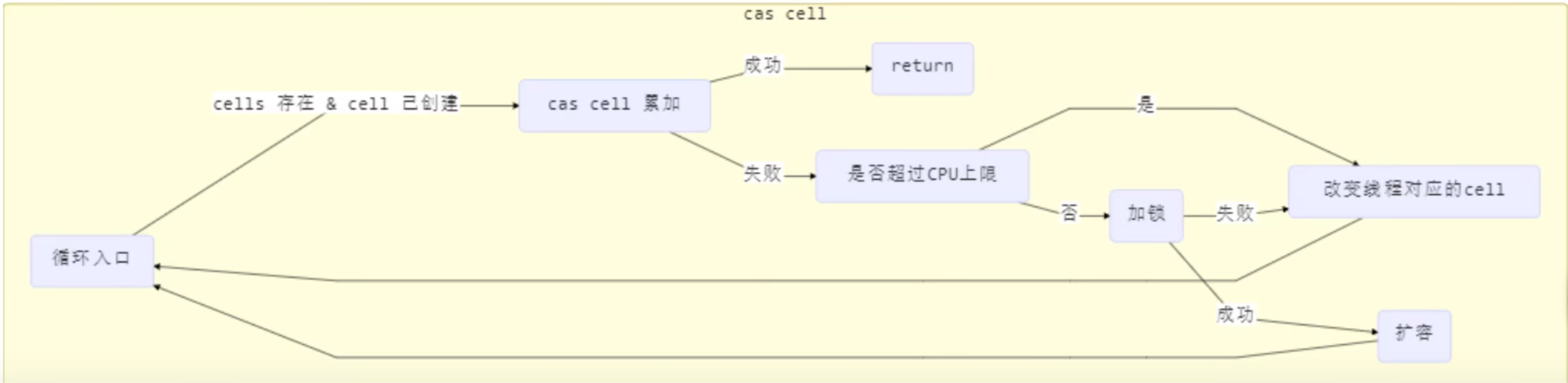
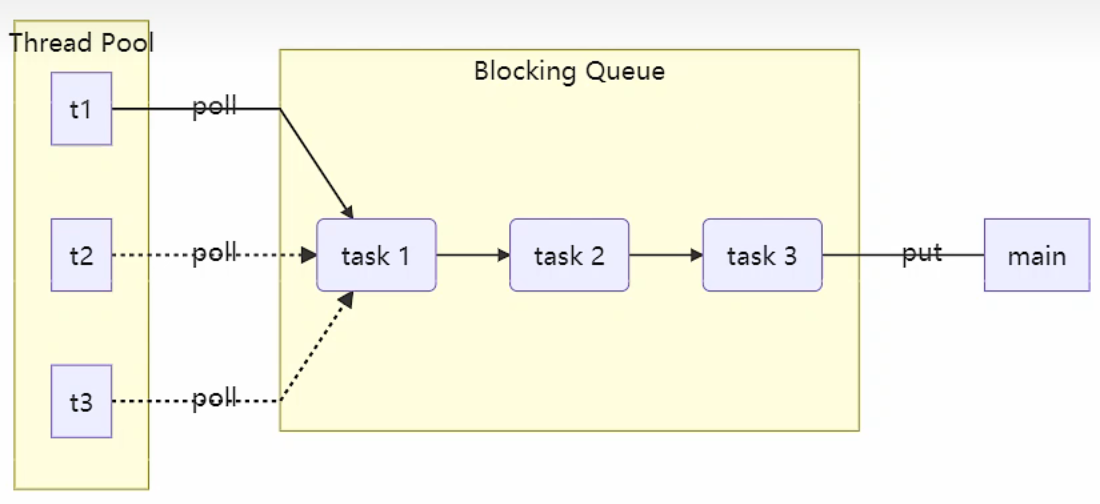

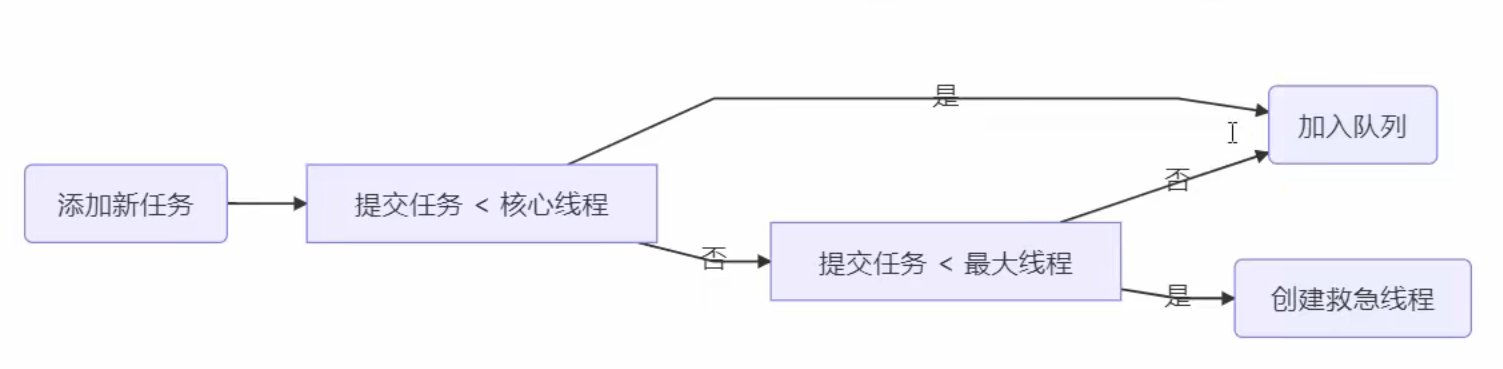
%E7%B1%BB%E5%9B%BE%E7%BB%93%E6%9E%84.png)